Ad Click Aggregator System Design: Why One Pipeline Isn't Enough
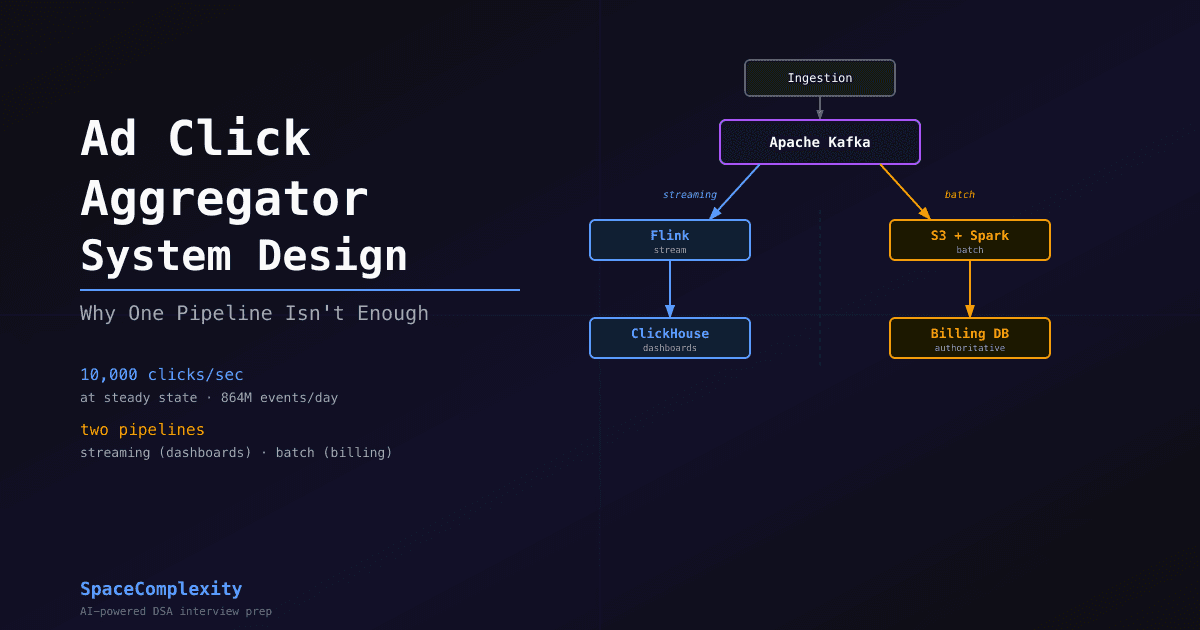
- Two pipelines (Kafka + Flink for dashboards, S3 + Spark for billing) resolve the speed-vs-correctness tension at the heart of this design.
- Event time, not ingestion time, is the only safe clock for billing; ingestion time misbills whenever mobile clients have latency.
- Deduplication is layered: Redis Bloom filter at ingestion for speed, exact GROUP BY dedup in the batch pipeline for billing authority.
- Flink watermarks close 1-minute windows 2 minutes late to absorb out-of-order mobile events without losing late clicks from billing.
- Exactly-once end-to-end requires Chandy-Lamport checkpointing plus an idempotent sink such as ClickHouse ReplacingMergeTree or Pinot upsert.
- Pre-aggregation is the scaling lever: 864 million raw events per day collapse to 14 million aggregate rows, a 60x write volume reduction.
- Lambda beats Kappa for billing-critical systems despite the two-codebase cost; the batch pipeline is your audit trail when advertisers dispute charges.
The naive read of the ad click aggregator system design interview is "count clicks per ad per minute." Simple counter. Done. Fifteen minutes left on the clock. You're feeling great.
Then the interviewer asks how you handle a Kafka consumer crash mid-window. Whether you'll double-charge an advertiser for a retried request. What happens when a mobile click event arrives 90 seconds late because the user was in a tunnel. The room gets quiet fast.
Two genuinely conflicting requirements sit at the heart of this design: speed (advertisers need dashboards that update in near-real-time) and correctness (advertisers pay based on these numbers, so the math has to be exact). No single pipeline can fully optimize for both. That tension is the whole design problem.
What the Ad Click Aggregator Actually Requires
An ad click aggregator does two things: it ingests click events as they happen and serves aggregated metrics against them.
Functional requirements:
- Record every ad click event (ad_id, user_id, timestamp, campaign_id, country, device_type)
- Return the click count for a given ad_id over a time range (last minute, last hour, last day)
- Support grouping by dimensions: campaign, country, device
- Power real-time dashboards and billing reports
Non-functional requirements:
- High write throughput is the dominant constraint. A platform running millions of ads processes roughly 10,000 clicks per second at steady state, spiking to 50,000 during campaign launches or major events. That's 864 million events per day.
- End-to-end latency under 5 seconds for dashboard data
- Billing data must be exactly correct. No double-counting, no missing clicks.
- Events arriving up to 2 minutes late must still be counted correctly
Clarify upfront: are you building the query API too, or just ingestion and aggregation? Is fraud detection in scope? Those are separate deep dives. Get agreement before you draw anything.
Back-of-Envelope
| Metric | Value |
|---|---|
| Sustained click rate | 10,000/sec |
| Peak click rate | 50,000/sec |
| Events per day | ~864M |
| Event size (click_id, ad_id, user_id, ts, country, device) | ~100 bytes |
| Raw event storage per day | ~86 GB |
| Pre-aggregated rows per day (per ad per minute) | ~14M rows |
Pre-aggregation is the key lever here. You go from 864 million raw events down to about 14 million aggregate rows by grouping per ad per minute. That 60x reduction in write volume is why stream-side pre-aggregation exists. Without it, your OLAP database is getting hammered with individual inserts. Your database team will find you. They will have questions.
Two Pipelines, One Kafka Log
 The streaming path (blue) feeds dashboards in near-real-time. The batch path (amber) produces billing numbers once per hour. Both consumers read from the same Kafka log.
The streaming path (blue) feeds dashboards in near-real-time. The batch path (amber) produces billing numbers once per hour. Both consumers read from the same Kafka log.
Both paths read from Kafka as their source of truth. The streaming path (Flink to ClickHouse) gives advertisers their near-real-time dashboard. The batch path (S3 to Spark) produces the authoritative billing numbers once per hour. That shared log is what lets you replay data when something breaks downstream.
This is Lambda architecture. Two codebases to maintain is the cost. Two on-call rotations, two deployment pipelines, two opportunities to quietly diverge in behavior. The payoff is that billing never depends on a stream that might have had processing bugs. Advertisers are very motivated to notice billing bugs.
 Option C. Always Option C.
Option C. Always Option C.
Data Model
The click event schema:
click_events (raw)
click_id UUID -- deduplication key
ad_id bigint
campaign_id bigint
user_id bigint
event_time timestamp -- when the click happened (NOT when we received it)
country varchar(2)
device_type enum(MOBILE, DESKTOP, TABLET)
ip_address varchar(45)
The aggregated table in ClickHouse:
ad_click_counts (aggregated)
ad_id bigint
window_start timestamp -- 1-minute tumbling window
country varchar(2)
device_type enum
click_count bigint
PRIMARY KEY (ad_id, window_start, country, device_type)
Always store and process by event_time, not ingestion_time. If a click fires at 12:00:00 but reaches your ingestion service at 12:00:45 due to a slow mobile connection, it belongs in the 12:00 window. Using ingestion time gets you wrong billing numbers the moment any client has network latency.
API Design
POST /v1/clicks
Body: { ad_id, user_id, campaign_id, country, device_type, client_timestamp }
Response: 202 Accepted
GET /v1/clicks/aggregate
Params: ad_id, start_time, end_time, granularity=MINUTE|HOUR|DAY, group_by=country
Response: { ad_id, buckets: [{ window_start, click_count }] }
The write endpoint returns 202 (Accepted), not 200 (OK). The click is durable once Kafka acknowledges it, not once it appears in the aggregate. Make that explicit to the interviewer. It shows you understand the pipeline.
The Hard Parts
Every Duplicate Costs Someone Money
About 10 to 25% of clicks on major platforms are invalid, either bots, click farms, or accidental double-taps. The bots are very committed. Your system will also generate duplicates internally: mobile retries on timeout, Kafka redelivery after consumer crash, and Flink reprocessing on checkpoint recovery.
 Layer 1 is fast and probabilistic. Layer 2 is slow and exact. Billing only ever uses Layer 2.
Layer 1 is fast and probabilistic. Layer 2 is slow and exact. Billing only ever uses Layer 2.
Two-layer dedup:
-
At ingestion: check click_id against a Redis Bloom filter. If "probably seen," drop it. A 1% false positive rate is acceptable in real-time because the batch pipeline corrects it. This handles the bulk of duplicate traffic.
-
In the batch pipeline: exact deduplication via
GROUP BY click_id, HAVING COUNT(*) > 1. This is the authoritative pass for billing. Never use real-time counts to charge advertisers.
The composite dedup key is (click_id, ad_id, event_time). A UUID click_id generated client-side is stable across retries. If the client doesn't send one, the ingestion service hashes (user_id, ad_id, floor(event_time / 5s)) for a 5-second idempotency window.
Why Your 12:00 Window Closes at 12:03
Flink uses tumbling 1-minute windows based on event_time. The problem is that events arrive out of order. A click from 12:00:15 might reach Kafka at 12:01:45 if the client buffered it during a connectivity drop. Every mobile user has been in exactly that tunnel at exactly the wrong moment.
 All dots shown have an event_time in the 12:00 window. The x-axis is when they arrived. The watermark gives late arrivals a 2-minute grace period.
All dots shown have an event_time in the 12:00 window. The x-axis is when they arrived. The watermark gives late arrivals a 2-minute grace period.
Flink's watermark mechanism handles this. A watermark is a signal that says "I'm confident all events with event_time before T have now arrived." Flink emits a watermark of max(event_time seen) - 2 minutes, meaning it waits 2 minutes past the window end before finalizing results. The window for 12:00 to 12:01 closes at 12:03 wall-clock time.
Events arriving after the watermark are "late." You have two choices: drop them (acceptable for dashboards) or update the window result (required for billing). The batch pipeline handles this automatically since it runs hourly against the complete raw archive.
Exactly-Once Requires an Idempotent Sink
Flink achieves exactly-once end-to-end through distributed snapshots (Chandy-Lamport checkpointing) plus a two-phase commit to the sink. Every 30 seconds, Flink snapshots its window state and current Kafka offsets. A node crash means replaying from the last snapshot. Events re-processed generate the same output, so checkpoint plus idempotent sink = exactly-once.
The sink must be idempotent for this to work. In ClickHouse, a ReplacingMergeTree table engine or an insert_deduplication_token on each Flink checkpoint block achieves this. In Apache Pinot (Uber's choice for this exact use case), the upsert feature merges segments by primary key. Either way, you get the same count regardless of how many times Flink replays a window.
The Batch Pipeline Is Your Audit Trail
The streaming pipeline is fast, but it is not the source of truth. Once per hour, Spark reads the raw events from S3, deduplicates exactly, applies finalized fraud scores (fraud detection runs separately with a 30-minute latency), and writes corrected aggregates back to ClickHouse, overwriting the streaming estimates.
This reconciliation loop is what makes the system auditable. An advertiser disputes a charge. You pull the raw event log, replay the batch pipeline, and show them the exact events they're being billed for.
Tradeoffs Worth Naming Explicitly
Lambda vs. Kappa. Lambda (streaming + batch) gives you billing correctness but two codebases. The speed vs accuracy tradeoff shows up here as concretely as anywhere in distributed systems. Kappa architecture uses a single streaming pipeline and corrects errors by replaying the Kafka log through the same Flink job. Kappa is simpler operationally but requires Kafka to retain events for weeks (expensive), and correction reruns interfere with live traffic unless you partition the job carefully. Lambda is the safer choice for billing-critical systems.
OLAP store selection. ClickHouse is the simplest to operate, handles ad-hoc analytical queries fast, and is the right default. Apache Druid has native streaming ingestion and sub-second query latency on high-cardinality data. Apache Pinot (what Uber uses) has upsert support and star-tree indexes for ultra-low-latency reads. For a 45-minute interview, default to ClickHouse. Pinot is great, but you'll spend twenty minutes explaining star-tree indexes instead of talking about the actual design.
Kafka partition key. Partition by ad_id so all events for a given ad go to the same partition, in order. Flink's stateful window aggregations are co-located by key, so this eliminates cross-partition shuffles. The downside: hot ads (Super Bowl campaigns) can make one partition a hotspot. Mitigation: composite key ad_id % 256 to spread across subpartitions.
The 45-Minute Clock
| Phase | Time | What to Cover |
|---|---|---|
| Requirements | 5 min | Functional scope, scale, latency SLAs, billing vs dashboard distinction |
| Estimation | 5 min | 10K clicks/sec, 86 GB/day raw, 14M aggregate rows/day |
| High-level design | 8 min | Two-pipeline architecture, Kafka as shared log |
| Data model + API | 7 min | click_events schema, event_time vs ingestion_time, 202 vs 200 |
| Deep dives | 15 min | Dedup (Bloom filter + exact batch), watermarks, exactly-once, reconciliation |
| Tradeoffs | 5 min | Lambda vs Kappa, OLAP choice, partition key hotspot |
The requirements phase is the trap. You rush to the whiteboard, start drawing Kafka, and four minutes in you're designing the wrong system. Interviewers at Meta and Google explicitly score whether you scoped the billing vs dashboard distinction. Those are different consistency requirements, and conflating them is the most common mistake on this problem.
Quick Recap
- Two pipelines. Streaming (Kafka + Flink) for dashboards, batch (S3 + Spark) for billing. One log, two consumers.
- Event time, always. Ingestion time gives you wrong billing numbers whenever clients have latency.
- Dedup is layered. Bloom filter at ingestion (fast, 1% FPR), exact GROUP BY in batch (authoritative).
- Watermarks close windows gracefully. Wait 2 minutes past window end; late arrivals beyond that go to batch reconciliation.
- Flink checkpoint + idempotent sink = exactly-once. ClickHouse ReplacingMergeTree or Pinot upsert semantics are the sink requirement.
- Pre-aggregation is the scaling lever. 864M raw events become 14M aggregate rows before hitting the OLAP store.
- Reconciliation is not optional. Run it hourly to overwrite streaming estimates with auditable batch numbers.
Practicing this kind of problem out loud, with someone pushing back on your tradeoffs, is where the real prep happens. SpaceComplexity runs voice-based mock system design interviews with rubric scoring across all four dimensions. Worth a session before your onsite.