Aho-Corasick: Match Every Pattern at Once in One Pass
- Aho-Corasick replaces P separate KMP runs with one pass: O(n + M + k) instead of O(P·n)
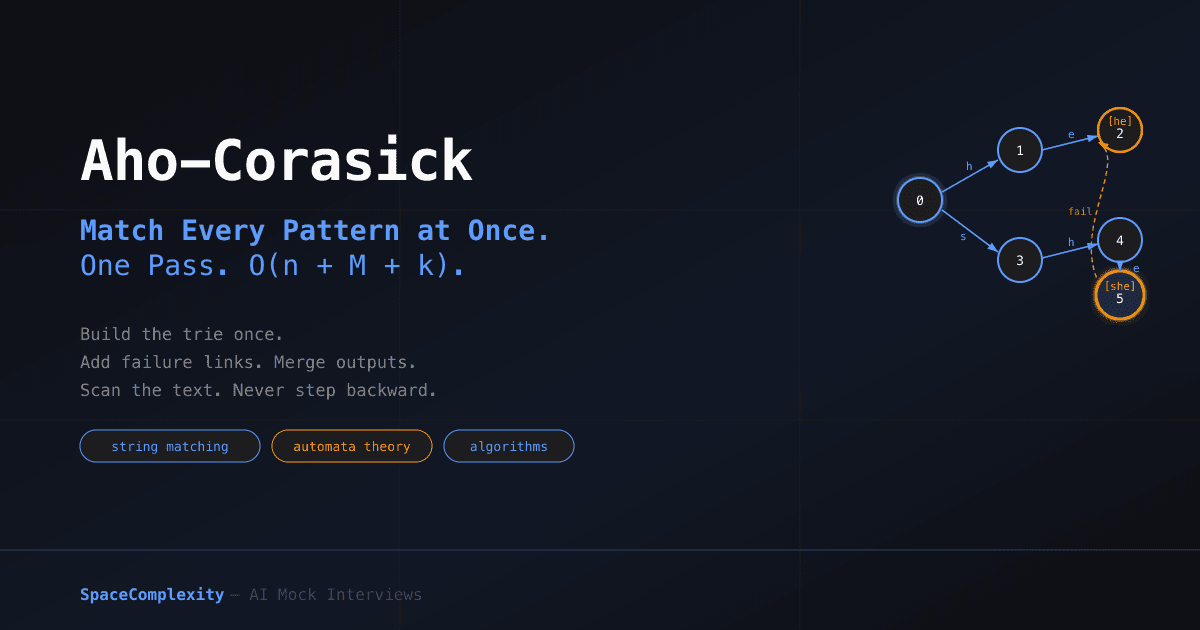
- The goto function is a trie; failure links redirect mismatches to the longest suffix that is also a trie prefix
- Failure links are built in O(M) via BFS, using the same amortized accounting as the KMP failure function
- Output merging during BFS embeds every failure-chain match into each node, so search reports all overlapping matches in O(1) per position
- The text pointer never goes backward: depth increases by at most 1 per character, making search O(n + k)
- A precomputed transition table (used by fgrep and Snort) converts the trie into a complete DFA so search is a single array lookup per character
- Real-world uses include Unix fgrep, Snort IDS, antivirus scanners, genome search, and LeetCode 1032 (Stream of Characters)
Say you need to scan a 10 MB log file for 500 malicious hostnames. The obvious plan: loop over all 500 patterns, run KMP once each. That's O(500n). With 10 million characters per file, you've just scheduled 5 billion operations. Congratulations. Your laptop is now a space heater.
The Aho-Corasick algorithm collapses all 500 patterns into a single finite automaton and scans the text once: O(n + M + k), where M is the total length of all patterns and k is the total number of matches.
This is the algorithm behind the original Unix fgrep, the Snort and Suricata IDS engines, McAfee and Kaspersky signature scanners, and bioinformatics tools that scan entire genomes for thousands of motifs simultaneously. Alfred V. Aho and Margaret J. Corasick published it in "Efficient String Matching: An Aid to Bibliographic Search," Communications of the ACM, June 1975.
The mental model: if KMP is a single-pattern automaton, Aho-Corasick is that automaton built for every pattern at the same time.

Where we start: searching for one pattern at a time. Add 499 more patterns and suddenly you want a different approach entirely.
Three Functions Drive the Algorithm
The original paper defines the algorithm around three functions. Understand each one separately before seeing how they compose.
The Goto Function
Insert every pattern into a trie. Each node is a state. The goto function g(state, char) returns the next state on a given character, or FAIL if no such edge exists. A prefix tree, nothing more.
Patterns: he, she, his, hers
root(0) ──h──▶ 1 ──e──▶ 2[he] ──r──▶ 8 ──s──▶ 9[hers]
└──i──▶ 6 ──s──▶ 7[his]
root(0) ──s──▶ 3 ──h──▶ 4 ──e──▶ 5[she]

The goto function is just a trie. Nodes with gold borders carry a match output. Everything else is an internal state.
The Failure Function
Here's where it gets interesting. When you're at state u and see a character with no goto edge, you can't just reset to root. That would miss overlapping matches. Instead, you jump to the longest proper suffix of u's string that is also a prefix in the trie. That's the failure link.
For state 5 (the string "she"), the longest proper suffix that is also a trie prefix is "he" (state 2). So fail[5] = 2. Think about what this means: after matching "she", the automaton already knows it has matched "he" as a suffix. It doesn't throw that away.
For state 7 ("his"), the longest proper suffix in the trie is "s" (state 3). So fail[7] = 3.
Failure links are computed with a single BFS from the root. Depth-1 nodes all fail to root. For a deeper node v (child of u via character c):
f = fail[u]
while f != root and c not in goto[f]:
f = fail[f]
fail[v] = goto[f][c] if c in goto[f] else root

Solid blue: goto edges. Dashed red: failure links. When the automaton can't make progress forward, the failure link says exactly where to fall back to, preserving the longest useful suffix.
The Output Function
Some states match multiple patterns. State 5 ("she") also contains "he" via its failure chain. The output function collects every pattern that ends at a given state, directly or through the failure chain.
During BFS construction, you merge outputs in one line: output[v] += output[fail[v]]. After this, checking output[cur] during search is sufficient. No failure chain traversal at search time. You paid the cost once, during construction.

The BFS propagates outputs through failure links at construction time. When the search reaches state 5, it reports both "she" and "he" in O(k) time, where k is the number of matches at that position.
Building the Automaton
Phase 1: Build the trie. Insert every pattern character by character. Each new character creates one node. Cost: O(M) time and O(M) nodes, where M is the total length of all patterns.
Phase 2: Compute failure links via BFS. Process level by level so every parent's failure link is ready before you need it. For each node v at depth d (child of u via char c), the while loop traverses failure links starting from fail[u]. Those traversals strictly decrease depth, so they can never loop.
Total BFS cost: O(M). Consider any root-to-leaf path in the trie, corresponding to one pattern of length L. The failure link depths along that path form a sequence that can increase by at most 1 per node and can decrease by any amount but never below zero. By the same amortized accounting as KMP failure function construction, total traversals along the path are O(L). Since each trie node lies on exactly one root-to-leaf path, summing over all paths gives O(M).
Phase 3: Merge outputs. One extra line in the BFS: output[v] += output[fail[v]]. Total cost is O(M + total embedded pattern matches across all states), bounded by the total output size.
Search: O(n + k), Never Backward
With the automaton built, scanning is:
cur = root for each character ch at position i in text: while cur != root and ch not in goto[cur]: cur = fail[cur] if ch in goto[cur]: cur = goto[cur][ch] report output[cur]
The text pointer advances exactly once per character and never goes backward. The depth of cur increases by at most 1 per character (one successful goto). Failure link traversals strictly decrease depth. Since depth is non-negative and bounded by the max pattern length, total failure link traversals across the entire text are bounded by total depth increases = n. Search is O(n + k) where k is the total number of reported matches.
Tracing "ahishers"
Patterns: {he, she, his, hers}. Text: a h i s h e r s (positions 0 through 7).
| i | ch | state | transition | new state | output |
|---|---|---|---|---|---|
| 0 | a | 0 | no goto, stay root | 0 | |
| 1 | h | 0 | goto[0][h] = 1 | 1 | |
| 2 | i | 1 | goto[1][i] = 6 | 6 | |
| 3 | s | 6 | goto[6][s] = 7 | 7 | his |
| 4 | h | 7 | fail[7]=3, goto[3][h]=4 | 4 | |
| 5 | e | 4 | goto[4][e] = 5 | 5 | she, he |
| 6 | r | 5 | fail[5]=2, goto[2][r]=8 | 8 | |
| 7 | s | 8 | goto[8][s] = 9 | 9 | hers |
Four matches in one pass. "she" and "he" at the same end position, both caught because fail[5] = 2 (state for "he") and the outputs were merged during construction.
Notice position 4 (char 'h'): after finding "his" at position 3, the automaton follows fail[7] = 3 (the "s" state), then takes goto[3][h] = 4. It does not reset to root. The trailing 's' from "his" becomes the leading 's' of "she." That is failure links working exactly as designed.
Complexity at a Glance
| Operation | Time | Space |
|---|---|---|
| Build trie | O(M) | O(M) nodes |
| Build failure links | O(M) amortized | O(M) |
| Merge outputs | O(M + total embedded matches) | O(M + total embedded matches) |
| Precompute all transitions (optional) | O(M · |Σ|) | O(M · |Σ|) |
| Search text | O(n + k) | O(1) extra |
M = total pattern length. n = text length. k = total matches. |Σ| = alphabet size.
Why space is O(M · |Σ|) with a fixed children array but O(M) with hash maps. If you use a fixed array of size |Σ| per node (as the C implementation below does), each of O(M) nodes holds |Σ| entries. For |Σ| = 26, that is 26 integers per node. For full ASCII (|Σ| = 256), it is 256. Using a hash map per node reduces this to O(M) total, at the cost of hash overhead on lookups.

Left: hash maps per node, follow failure links lazily at search time. Right: the C approach, filling every missing edge at build time. The tradeoff is O(M) vs O(M·|Σ|) space, with O(n + failure_traversals) vs true O(n) search. Real engines like Snort use the precomputed version.
The C implementation below also demonstrates "precomputed transitions": during BFS, missing goto edges are filled with goto[u][c] = goto[fail[u]][c]. This converts the incomplete trie into a complete DFA. Search becomes truly O(n) with no failure link traversals at runtime. The tradeoff is O(M · |Σ|) construction time and space.
A non-obvious subtlety. The output merging during BFS (output[v] += output[fail[v]]) embeds the entire failure-chain output into each node. This is clean and fast during search, but it inflates memory when many states share suffix matches. The alternative is to store a single "dictionary link" pointer per node pointing to the nearest failure-chain ancestor with non-empty output, and chase that chain at search time. The dictionary link approach uses O(M) extra space but O(matches per position) time per character instead of O(1). For large alphabets with dense overlap, dictionary links win on memory.
One Structure, Every Language
Each implementation below builds the automaton from a list of patterns and provides a search method that returns (end_position, pattern_index) pairs.
from collections import deque from typing import List, Tuple class AhoCorasick: def __init__(self, patterns: List[str]): self.goto: List[dict] = [{}] self.fail: List[int] = [0] self.output: List[List[int]] = [[]] self._build(patterns) def _build(self, patterns: List[str]) -> None: for idx, pattern in enumerate(patterns): cur = 0 for ch in pattern: if ch not in self.goto[cur]: self.goto[cur][ch] = len(self.goto) self.goto.append({}) self.fail.append(0) self.output.append([]) cur = self.goto[cur][ch] self.output[cur].append(idx) queue: deque = deque() for s in self.goto[0].values(): queue.append(s) while queue: u = queue.popleft() for ch, v in self.goto[u].items(): f = self.fail[u] while f and ch not in self.goto[f]: f = self.fail[f] self.fail[v] = self.goto[f].get(ch, 0) if self.fail[v] == v: self.fail[v] = 0 self.output[v] = self.output[v] + self.output[self.fail[v]] queue.append(v) def search(self, text: str) -> List[Tuple[int, int]]: results = [] cur = 0 for i, ch in enumerate(text): while cur and ch not in self.goto[cur]: cur = self.fail[cur] cur = self.goto[cur].get(ch, 0) for idx in self.output[cur]: results.append((i, idx)) return results # Usage ac = AhoCorasick(["he", "she", "his", "hers"]) print(ac.search("ahishers")) # [(3, 2), (5, 1), (5, 0), (7, 3)] # his@3, she@5, he@5, hers@7
What Problems Does Aho-Corasick Solve?
Multi-pattern string matching: you have a fixed set of patterns and need to find all occurrences of all of them in one or more texts.
The canonical use cases:
- Content filtering and moderation. Scan user messages for any of thousands of banned phrases in one pass. The alternative is one regex per phrase. Nobody wants that.
- Network intrusion detection. Snort and Suricata maintain rule sets with hundreds of thousands of byte signatures. Aho-Corasick is the inner loop of their packet inspection engine.
- Antivirus scanning. Every file is scanned against a database of virus signatures. Running each signature as a separate search would be prohibitively slow.
- Bioinformatics. Scan a 3-billion base-pair genome for all known regulatory motifs, restriction enzyme cut sites, or CRISPR guide RNA targets simultaneously.
- Log processing. Find all error codes or known hostnames in a stream of structured log lines.
- Bibliographic search. The original application: find all paper titles matching any of a list of keywords in a single pass over a citation database.
Five Signals This Is the Right Tool
-
Multiple patterns, one text (or stream). You have P patterns and T texts. If P * T is large, pre-processing once into an automaton and scanning each text once is much cheaper than P passes per text.
-
Patterns are static, text changes. If patterns change constantly but text is fixed, consider other structures. Aho-Corasick pays its construction cost O(M * |Σ|) upfront and earns it back over repeated searches.
-
Overlapping matches matter. A naive approach that stops after each match would miss "she" and "he" at the same position. Aho-Corasick catches both.
-
Streaming input. The automaton maintains a single integer (current state) as its only memory. You can feed characters one at a time from a socket or file descriptor without buffering the entire text.
-
The brute force complexity is unacceptable. You have a 100 MB text and 10,000 patterns averaging 20 characters. Naive search runs KMP once per pattern: 10,000 × 100 million = 1 trillion operations. Aho-Corasick: (200K + 100M + k) operations.
Worked Example 1: Classic Multi-Pattern Grep
Problem: given a list of banned words and a user message, report every banned word and where it appears.
Why Aho-Corasick fits: you have many patterns (banned words) and one text (the message). Patterns are static (loaded at startup). Overlapping matches matter ("he" ends inside "she" and both get reported at the same position). A single pass through the message is sufficient.
banned = ["hate", "spam", "scam", "hate crime"] ac = AhoCorasick(banned) message = "this is a hate crime spam operation" for end_pos, pat_idx in ac.search(message): word = banned[pat_idx] start = end_pos - len(word) + 1 print(f"Found '{word}' at [{start}, {end_pos}]") # Found 'hate' at [10, 13] # Found 'hate crime' at [10, 19] # Found 'spam' at [21, 24]
Here "hate" and "hate crime" are matched at different end positions (13 and 19) and don't need output merging. Output merging is what matters for suffix-embedded patterns: if both "he" and "she" were in the set, reaching state 5 ("she") reports both at the same end position, because fail[she_state] points to the "he" state and the outputs were merged during construction.
Worked Example 2: LeetCode 1032, Stream of Characters
Problem: a StreamChecker is initialized with a list of words. You add characters one at a time and after each addition you must report whether any word is a suffix of the stream so far.
The naive solution re-scans the growing suffix after each character. That's O(n^2) for a stream of n characters. With Aho-Corasick, the automaton holds the entire suffix state in a single integer.
class StreamChecker: def __init__(self, words: List[str]): self.ac = AhoCorasick(words) self.state = 0 def query(self, letter: str) -> bool: cur = self.state while cur and letter not in self.ac.goto[cur]: cur = self.ac.fail[cur] cur = self.ac.goto[cur].get(letter, 0) self.state = cur return len(self.ac.output[cur]) > 0
The state is persistent across calls. The automaton remembers the longest suffix of everything seen so far that is a prefix of some word in the dictionary. You never re-read old characters.
Quick Recap
- Aho-Corasick builds a trie of all patterns, adds BFS-computed failure links (longest proper suffix that is a trie prefix), and merges outputs (all patterns ending at each state, including via failure chain).
- Construction: O(M) for failure links plus O(M · |Σ|) if you precompute all transitions, O(M) if you use hash maps and follow failure links lazily at search time.
- Search: O(n + k) where n is text length and k is total matches. Text pointer never goes backward.
- The self-loop guard prevents
fail[v] = vfor depth-1 nodes (which would create a cycle). - Dictionary links (output links) are an alternative to merged outputs that trade memory for per-character work.
- The C implementation's precomputed transition table is what real-world engines (fgrep, Snort) actually ship.
- Canonical problems: any multi-pattern search, LeetCode 1032 (stream of characters), content filtering, network IDS.
If you want to practice explaining this algorithm under interview pressure, not just implementing it in silence, SpaceComplexity runs voice-based mock interviews with rubric feedback on exactly this kind of material. The gap between "I can code it" and "I can explain it in 45 minutes with an interviewer watching" is where most prep falls short.
Further Reading
- Aho-Corasick algorithm on Wikipedia
- Aho-Corasick on cp-algorithms.com
- Aho-Corasick Pattern Searching on GeeksforGeeks
- KMP Algorithm deep dive (the single-pattern foundation this algorithm extends)
- Trie Data Structure (the goto function is a trie)
- Suffix Array (an alternative for offline multi-pattern problems)