Big-O Isn't a Tight Bound. Here's the Difference Between O, Theta, and Omega.
- Big-O is an upper bound: f grows no faster than g, so O(n²) is a valid bound for a linear algorithm.
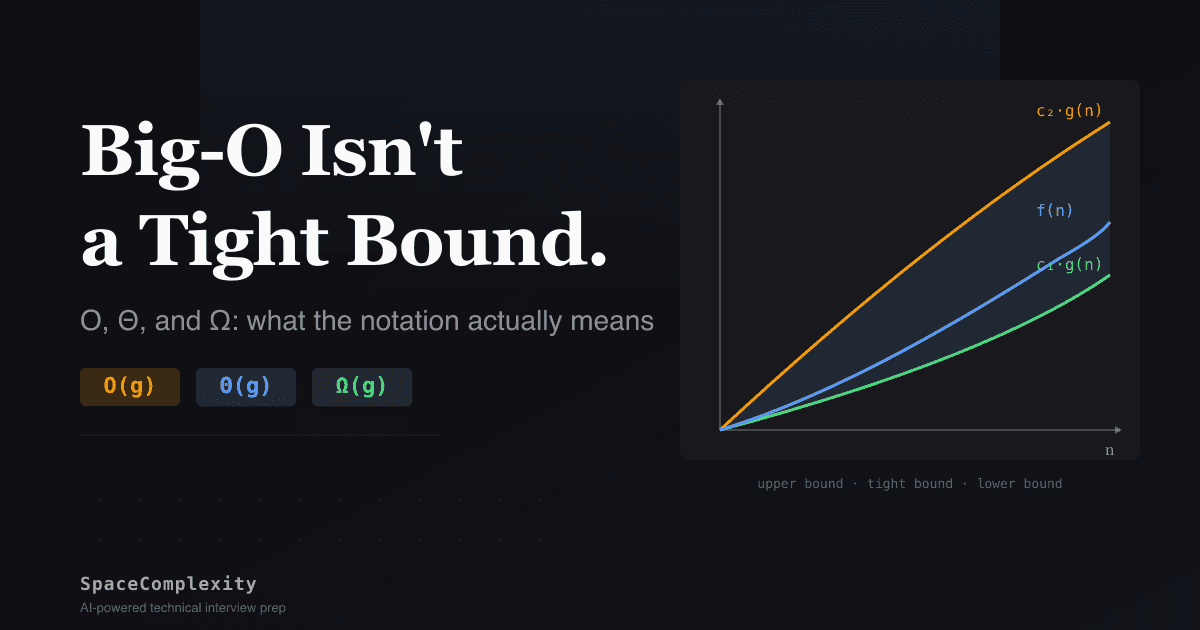
- Theta (Θ) is a tight bound: two constants sandwich f between c₁·g and c₂·g, pinning the exact growth class.
- Omega (Ω) is a lower bound: the comparison sort Ω(n log n) floor holds for every algorithm, including ones not yet invented.
- Merge sort is Θ(n log n) unconditionally; quicksort is Θ(n²) worst case and Θ(n log n) average case.
- The classic interview mistake: saying "quicksort is O(n log n)" when asked about worst case. The correct unconditional upper bound is O(n²).
- Best, worst, and average case pick which function you analyze; O, Theta, and Omega describe how that function grows.
"Merge sort is O(n log n)." You've heard it a thousand times, and you've said it yourself. But that statement is weaker than you probably intend. O(n log n) says merge sort runs in at most n log n time, up to a constant. By that logic, every O(1) algorithm is also O(n log n), and you could write "bubble sort is O(n!)" without being wrong. Your professor would cry. But you'd be right.
What you mean is that merge sort always runs in exactly n log n time, no faster and no slower by more than a constant factor. That's Θ(n log n). The two notations look similar in conversation but mean very different things in precision. Understanding the gap between Big-O, Theta, and Omega is what lets you make airtight complexity claims instead of just repeating the accepted answer.

The course notes your professor hands out. Technically valid O bounds throughout. r/ProgrammerHumor
O, Theta, and Omega: Three Bounds, Three Questions
The three main asymptotic notations each answer a different question about how a function grows.
O(g(n)) asks: does f grow no faster than g? It's an upper bound. f could grow slower, or at exactly the same rate. Both are fine.
Ω(g(n)) asks: does f grow at least as fast as g? It's a lower bound. f could grow faster, or at exactly the same rate. Both are fine.
Θ(g(n)) asks: does f grow at exactly the same rate as g? It's a tight bound. O must hold from above and Ω must hold from below, for the same g.
The cleanest mental model: O is ≤, Ω is ≥, Θ is = (all up to constant factors and large enough inputs). If you can show f(n) is both O(g(n)) and Ω(g(n)), you've proven Θ(g(n)). No extra work needed.

O, Ω, and Θ are three different claims about the same g(n). Θ requires both to hold simultaneously.
What the Definitions Actually Say
Paul Bachmann introduced Big-O in 1894 for number theory. Donald Knuth standardized Ω and Θ for computer science in a 1976 SIGACT News paper titled "Big Omicron and big Omega and big Theta," where he explicitly lobbied for consistent usage of all three.
f(n) = O(g(n)) if there exist positive constants c and n₀ such that:
f(n) ≤ c · g(n) for all n ≥ n₀
f(n) = Ω(g(n)) if there exist positive constants c and n₀ such that:
f(n) ≥ c · g(n) for all n ≥ n₀
f(n) = Θ(g(n)) if there exist positive constants c₁, c₂, and n₀ such that:
c₁ · g(n) ≤ f(n) ≤ c₂ · g(n) for all n ≥ n₀
O and Ω each need one constant. Θ needs two constants that sandwich the function from both sides. That sandwich is what "tight bound" means.
A concrete example: f(n) = 7n + 42.
- f(n) = O(n): pick c = 8, n₀ = 43. Then 7n + 42 ≤ 8n for all n ≥ 43. ✓
- f(n) = Ω(n): pick c = 7, n₀ = 1. Then 7n + 42 ≥ 7n always. ✓
- Therefore f(n) = Θ(n). Both bounds hold with g(n) = n.
Note that f(n) = O(n²) is also valid, as is O(n³), O(2ⁿ). A function has infinitely many valid O upper bounds. Only Θ nails down the exact growth class.

f(n) = 7n+42 is Θ(n): it lives between 7n and 8n forever after n=42. O(n²) is also a valid upper bound, just not a tight one.
O and Θ Are Orthogonal to Best/Worst Case
This is the tangle point. O, Ω, and Θ are mathematical tools that describe the growth rate of a specific function. Best case and worst case are separate functions of n. You have to settle on which function you're analyzing before you reach for the notation.
Take insertion sort. There are (at least) two natural functions to analyze:
- T_worst(n): comparisons made on a reverse-sorted array of length n
- T_best(n): comparisons made on an already-sorted array of length n
These are genuinely different functions. Apply the notation to each:
| Input scenario | Tight bound |
|---|---|
| Insertion sort, worst case | Θ(n²) |
| Insertion sort, best case | Θ(n) |
| Merge sort, worst case | Θ(n log n) |
| Merge sort, best case | Θ(n log n) |
| Binary search, worst case | Θ(log n) |
Merge sort earns an unconditional Θ(n log n) because its structure doesn't vary by input. Every call divides the array in half, every merge touches n total elements, and there are log n levels. Feed it a sorted array; it still does the same work. That structural guarantee is exactly why Θ is the right notation for merge sort regardless of input distribution.
Insertion sort can't make that claim. Its tight bound depends on which function you're analyzing. "Insertion sort is O(n²)" is true for the worst case but incomplete without specifying that context. Notice merge sort occupies only one row in that table. That's not a typo.

Merge sort's tree looks the same for any input. Insertion sort's doesn't. That's why one earns an unconditional Θ and the other needs a qualifier.
Quicksort: Where the Confusion Becomes Concrete
Quicksort is the most instructive example because the cases genuinely differ.
- Best and average case: Θ(n log n). A typical pivot splits the array roughly in half each level, giving log n levels of n work each.
- Worst case: Θ(n²). Picking the minimum or maximum as pivot every time gives n levels of n work, a completely degenerate tree.
So what do you say about quicksort?
- "Quicksort is O(n²)." Correct. The worst case is Θ(n²), so n² is a valid overall upper bound.
- "Quicksort is Θ(n log n)." Misleading without qualification. This only holds for average and best cases.
- "Quicksort worst case is Θ(n²), average case is Θ(n log n)." The full picture.
The common mistake: saying "quicksort is O(n log n)" when the valid upper bound is O(n²). If an interviewer asks for the worst case and you say O(n log n), you've given an upper bound that's too optimistic. The correct worst-case upper bound is O(n²). Saying O(n log n) in that context signals either imprecision or confusion about which case you're analyzing, and interviewers do notice.
This is why the interchangeable use of O and Θ creates actual errors, not just notational sloppiness.
Why Ω Actually Matters: The Sorting Lower Bound
Lower bounds are where Ω earns its place. The most important lower bound in all of algorithm analysis is: any comparison-based sorting algorithm requires Ω(n log n) comparisons in the worst case.
Not for some specific algorithm. For every possible algorithm you could design, including ones nobody has invented yet.
The proof is clean. A sorting algorithm on n elements must distinguish between all n! possible orderings. Each comparison has two outcomes, so you're implicitly building a binary decision tree. A binary tree with n! leaves must have height at least log₂(n!). By Stirling's approximation, log₂(n!) ≈ n log₂ n. So any comparison sort must make at least Ω(n log n) comparisons.
Merge sort and heapsort achieve exactly Θ(n log n), so they're optimal comparison sorts. You cannot beat them asymptotically, ever, using comparisons.
Ω notation lets you make claims about impossibility, not just about specific algorithms. This isn't "we haven't found a faster way." It's "Ω(n log n) proves no comparison sort can." Those are very different things to say at a whiteboard.
![Binary decision tree for sorting three elements [a,b,c] showing two levels of comparisons and 6 leaf nodes for the 3!=6 possible orderings, with annotations showing height ≥ log₂(n!) ≈ n log₂ n comparisons required](https://assets.spacecomplexity.ai/blog/content-images/big-o-theta-omega/1779835416829-decision-tree.png)
With 3 elements there are 6 orderings, so any sorting algorithm needs a decision tree with 6 reachable leaves. Height ≥ log₂(6) ≈ 2.58, meaning at least 3 comparisons. This argument scales to Ω(n log n) for all n.
See the Big-O notation guide for the related proof that comparison sorts have an O(n log n) floor via the same decision-tree argument. And for a related deep dive into recursion complexity, see Recursion Time Complexity.
When "Strictly Faster" Matters: Little-o and Little-ω
Two more members of the family show up in academic papers and sometimes in interviews at companies that push into formal algorithm analysis.
f(n) = o(g(n)) (little-o) means g grows strictly faster than f. Equivalently: lim(n→∞) f(n)/g(n) = 0. The ratio goes to zero, so g eventually buries f completely.
f(n) = ω(g(n)) (little-ω) means f grows strictly faster than g. Equivalently: lim(n→∞) f(n)/g(n) = ∞.
Big-O allows the possibility that f and g grow at the same rate (f could be Θ(g)). Little-o forbids it. n = O(n), but n ≠ o(n). n = o(n²) because n/n² → 0.
You'll see little-o when someone describes an improvement that's genuinely asymptotically better, not just a constant factor. "We reduced the complexity from O(n²) to o(n²)" means the new algorithm grows strictly slower than n². An algorithm running in n² / log n qualifies.
Say Θ When You Mean Θ
Most interviewers use O where Θ would be precise. That's fine; match their register. Correcting your interviewer mid-sentence on notation is not how you win friends or job offers. But have the vocabulary ready for when precision matters:
- If an algorithm runs in the same class for every input, use Θ. "Merge sort is Θ(n log n)."
- If you only know an upper bound, or you want a safe worst-case ceiling, use O. "This can't be worse than O(n²)."
- If you're proving no algorithm can solve a problem faster, use Ω. "Finding the minimum requires Ω(n): you must inspect every element."
- If complexity varies by case, say so explicitly. "Θ(n log n) on average, Θ(n²) worst case."
The one mistake that actually costs you in an interview: saying O(n log n) for quicksort when the interviewer is specifically asking about worst-case bounds. The correct upper bound for all cases is O(n²). Saying O(n log n) signals either imprecision or confusion about which case you're analyzing.
Most of the time, nobody will push back. But if they do, you want to be able to explain: "O(n log n) is valid only as a bound on the average case. The tight worst-case bound is Θ(n²), which makes O(n²) the correct upper bound unconditionally."
For more on how complexity analysis connects to sorting algorithm tradeoffs, see Merge Sort vs Quick Sort.
If you want to practice explaining these distinctions out loud, where an interviewer can actually probe them, SpaceComplexity runs voice-based mock interviews with rubric feedback that covers exactly this kind of technical precision in complexity analysis.
Recap
- O(g(n)): upper bound. f grows no faster than g, up to a constant.
- Ω(g(n)): lower bound. f grows at least as fast as g, up to a constant.
- Θ(g(n)): tight bound. Both O and Ω hold simultaneously. Two constants sandwich f between them.
- o(g(n)) / ω(g(n)): strict versions. The ratio f/g goes to 0 or ∞, ruling out equal growth rates.
- Big-O dates to Bachmann (1894). Knuth formalized Ω and Θ in 1976.
- O, Ω, and Θ describe growth rates of specific functions. Best/worst/average case determines which function you hand them.
- Merge sort is Θ(n log n) unconditionally. Quicksort is Θ(n²) worst case, Θ(n log n) average.
- The comparison sort lower bound is Ω(n log n): proven via decision trees, not algorithm-specific.
- Interviewers often say O when they mean Θ. Understand the distinction; match their register in conversation.