Centroid Decomposition: One Node That Balances Everything
- Centroid decomposition builds a second tree from a tree's balance points by recursively finding the node whose removal splits the tree into halves
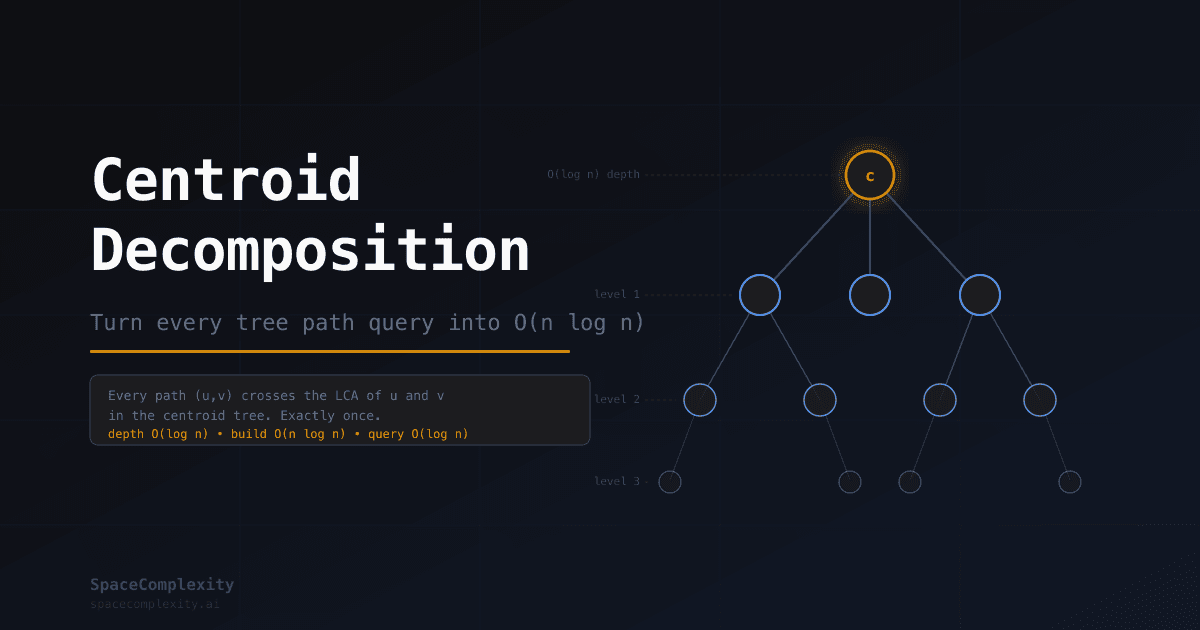
- Every path (u, v) in the original tree passes through the LCA of u and v in the centroid tree — the invariant that makes all path queries decomposable
- Build costs O(n log n): O(n) work per level times O(log n) levels from the n/2 halving guarantee at each centroid
- The
removed[]array is the implementation key — logically delete centroids without touching the adjacency list, so each DFS stays within its current component - Sequential subtree processing avoids counting same-subtree pairs without any explicit inclusion-exclusion step
- Each node belongs to O(log n) centroid ancestors, so paint and nearest-node query operations each cost O(log n)
- Reach for it when a tree problem reduces to computing something over all paths and the naive O(n²) approach is too slow
Your tree has a secret. Somewhere inside it sits a node whose removal splits the whole structure into components where none of them hold more than half the nodes. Remove it, find the same node inside each piece, keep going. You end up with a completely different tree built from those "balance points," and that second tree has one remarkable property: its depth is only O(log n).
That second tree is the centroid decomposition. Every path in the original tree passes through the centroid of exactly one component in the decomposition, which means any path query that costs O(n²) naively becomes O(n log n) or O(n log²n) with this structure underneath it. It is the go-to structure whenever a tree problem reduces to "compute something over all paths."
Nobody taught you this in intro CS because the curriculum was already full. But competitive programmers have been reaching for it since the 1970s, and once you see it, you cannot un-see it.
Jordan's 1869 Discovery (Not the Basketball Player)
A centroid of a tree with n nodes is a node whose removal leaves every connected component with at most ⌊n/2⌋ nodes.
Camille Jordan proved in 1869 that every tree has at least one centroid and at most two. If two exist, they are adjacent (the edge between them splits the tree into exactly two halves of n/2 nodes each), which only happens when n is even.
Finding the centroid requires two passes of DFS, both O(n).
Root the tree at any node. Compute subtree sizes with a standard DFS. For any node v with subtree size sz[v], removing v creates these components:
- Each child subtree c, with size sz[c]
- The "upward" component with size n - sz[v]
Node v is a centroid if and only if max(max(sz[children]), n - sz[v]) ≤ n/2.
The walk-to-centroid algorithm: start at any node. If the largest component after removing it exceeds n/2, walk toward the adjacent node that causes that large component. Repeat. This converges to the centroid in at most n steps because you only move in one direction, and the component sizes strictly decrease.
Tree with 7 nodes, rooted at 1:
1
/ \
2 3
/ \
4 5
/ \
6 7
Subtree sizes (sz[v]):
sz[6]=1, sz[7]=1, sz[4]=3, sz[5]=1
sz[2]=6, sz[3]=1, sz[1]=7
At node 1: children sizes = {6, 1}, upward = 0
max component = 6 > 7/2 = 3. Not the centroid.
Walk toward node 2 (the heavy child).
At node 2: children sizes = {3, 1}, upward = 7-6 = 1
max component = 3 ≤ 3.5. YES. Node 2 is the centroid.
 The walk always terminates in at most n steps. Each step strictly decreases the maximum component size.
The walk always terminates in at most n steps. Each step strictly decreases the maximum component size.
Building the Second Tree (Yes, You Need Two)
Centroid decomposition is a recursive divide-and-conquer on the tree:
- Find the centroid C of the current component
- Mark C as "removed" (logically deleted from the tree)
- For each subtree created by C's removal, recurse and find that subtree's centroid, then set C as its parent in the centroid tree
- Return C
The removed[] array is the implementation key: skip removed nodes in every DFS, and each traversal naturally stays within its current component. No adjacency list modification needed.
 Same nodes, completely different edges. The centroid tree has depth at most ⌊log₂(n)⌋.
Same nodes, completely different edges. The centroid tree has depth at most ⌊log₂(n)⌋.
Same 7-node tree. Step-by-step:
1. get_sz(1) on the whole tree → sz[1]=7
get_centroid → node 2 (as above)
Mark removed[2] = true
Centroid tree root: 2
2. Recurse on subtree {4,6,7} (reached via node 4, since 2 is removed):
get_sz(4) skipping removed → sz[4]=3
get_centroid → node 4 (all children ≤ 1 ≤ 1)
Mark removed[4] = true
cpar[4] = 2
3. Recurse on {6}: centroid = 6. cpar[6] = 4
Recurse on {7}: centroid = 7. cpar[7] = 4
4. Recurse on subtree {5}:
centroid = 5. cpar[5] = 2
5. Recurse on subtree {1,3} (reached via node 1, since 2 is removed):
get_sz(1) skipping removed → sz[1]=2
get_centroid → node 1 (child 3 has sz=1 ≤ 1)
Mark removed[1] = true
cpar[1] = 2
6. Recurse on {3}: centroid = 3. cpar[3] = 1
Centroid tree:
2
/ | \
4 5 1
/ \ \
6 7 3
The centroid tree has the same nodes as the original tree but completely different edges. Its depth is at most ⌊log₂(n)⌋ because each centroid splits its component into pieces of at most n/2 nodes, so sizes halve with each level. After k levels, the maximum component size is at most n/2^k. When n/2^k < 1, there are no more nodes, so the depth cannot exceed log₂(n).
The One Invariant That Justifies All This Work
Here is the meme that perfectly captures what divide-and-conquer feels like from the outside:
 The algorithm: find the center, split, recurse. The feeling: exactly this.
The algorithm: find the center, split, recurse. The feeling: exactly this.
Every path (u, v) in the original tree passes through the centroid of exactly one component in the decomposition. Specifically, it passes through the LCA of u and v in the centroid tree.
Here is why. Let c be the LCA of u and v in the centroid tree. Since c is an ancestor of both u and v, c was processed before any of their descendants in the decomposition. When c was the centroid of its component, that component contained both u and v. After removing c, u and v ended up in different subtrees of c (otherwise their LCA in the centroid tree would be a descendant of c, not c itself). Any path between nodes in different subtrees of c must cross c. So the path u→v in the original tree crosses c.
For any ancestor p of c in the centroid tree: both u and v are in the same subtree of p's component (because c is their LCA, not p), so the path u→v does not cross p.
 Left: the path crosses c in the original tree. Right: c is the LCA of u and v in the centroid tree. These are the same fact, stated two ways.
Left: the path crosses c in the original tree. Right: c is the LCA of u and v in the centroid tree. These are the same fact, stated two ways.
This invariant is everything. To answer any path query, you handle each centroid's component independently. Every node participates in at most O(log n) components across the entire decomposition (one per level of the centroid tree), so total work across all centroids is O(n log n).
The Complexity Report Card
| Operation | Time | Space | Notes |
|---|---|---|---|
| Find centroid of a component of size m | O(m) | O(m) | One DFS for sizes + one walk |
| Build full decomposition | O(n log n) | O(n) | O(n) per level × O(log n) levels |
| Centroid tree depth | O(log n) | At most ⌊log₂(n)⌋ levels | |
| Ancestor walk (one node to root) | O(log n) | Each node belongs to O(log n) components | |
| Paint node + query nearest painted | O(log n) per op | O(n log n) precomputed | Store dist[c][v] or walk ancestors |
| Count paths with property X | O(n log n) typical | O(n) or O(n log n) | Depends on per-centroid work |
Why Build Is O(n log n)
Think of the centroid tree level by level. At level 0 sits the root centroid. At level 1 sit the centroids of the components formed after removing the root. At level 2 sit the centroids of those subcomponents. And so on.
At each level, every original node appears in exactly one component. The total work to find all centroids at any single level is O(n) because each node's DFS contribution is counted once. The number of levels is O(log n) because component sizes halve at every step, giving O(n) × O(log n) = O(n log n) total.
The space for the structure itself is O(n): just the centroid parent array and the removed array. If you precompute and store distances from each node to all of its centroid ancestors (for fast query answering), that reaches O(n log n) because each node has O(log n) ancestors.
Why the Walk to Centroid Is Correct
When get_centroid walks from v to a neighbor u because sz[u] > tree_sz/2, the new "upward" component has size tree_sz - sz[u] < tree_sz/2. So the upward component always shrinks when you take a step. At the node c where no child has sz > tree_sz/2, all child components are ≤ tree_sz/2 by definition, and the upward component is < tree_sz/2 by the previous argument. Every component at c satisfies the ≤ n/2 bound. The walk always terminates at a valid centroid.
Two Things That Will Bite You in Python
The removed[] array approach has a hidden trap for Python users. The centroid tree itself recurses only O(log n) deep, so build() is safe from Python's 1000-frame limit. But get_sz() and get_centroid() recurse O(n) deep on a path graph of length n. If you hand this a bamboo-stick tree with n=2000 nodes, Python will hit its software recursion guard before the OS even gets to say segfault.
For n > 1000 in Python, you must call sys.setrecursionlimit(n + 10) before running the decomposition, or rewrite get_sz iteratively. The implementations below set it to 200010 at the top. This is not paranoia. It is experience.
The sequential subtree trick also deserves attention. The naive approach adds all distances to a frequency table and subtracts same-subtree contributions afterward. The cleaner approach processes each child subtree one at a time: count pairs using only the frequency table built from previous subtrees, then add the current subtree's distances to the table. Same-subtree pairs never enter the count, so no subtraction step is needed. This is both simpler to implement and easier to verify correct.
One Structure, Every Language
The implementations below build the centroid tree (the cpar array, where cpar[v] is v's parent in the centroid tree) and solve the classic "count pairs of nodes at exactly k edge-hops apart" problem to show the decomposition in use.
import sys from collections import defaultdict sys.setrecursionlimit(200010) # get_sz recurses O(n) deep def centroid_decompose(n: int, edges: list[tuple[int, int]]) -> tuple[list[int], int]: """Build centroid tree. Returns (cpar[], root_centroid).""" adj: list[list[int]] = [[] for _ in range(n)] for u, v in edges: adj[u].append(v) adj[v].append(u) sz = [0] * n removed = [False] * n cpar = [-1] * n def get_sz(v: int, p: int) -> int: sz[v] = 1 for u in adj[v]: if u != p and not removed[u]: sz[v] += get_sz(u, v) return sz[v] def get_centroid(v: int, p: int, tree_sz: int) -> int: for u in adj[v]: if u != p and not removed[u] and sz[u] > tree_sz // 2: return get_centroid(u, v, tree_sz) return v def build(v: int, parent_centroid: int) -> int: tree_sz = get_sz(v, -1) c = get_centroid(v, -1, tree_sz) cpar[c] = parent_centroid removed[c] = True for u in adj[c]: if not removed[u]: build(u, c) return c root = build(0, -1) return cpar, root def count_paths_of_length_k(n: int, edges: list[tuple[int, int]], k: int) -> int: """Count unordered pairs (u, v) with exactly k edges on the path u→v.""" adj: list[list[int]] = [[] for _ in range(n)] for u, v in edges: adj[u].append(v) adj[v].append(u) sz = [0] * n removed = [False] * n total = 0 def get_sz(v: int, p: int) -> int: sz[v] = 1 for u in adj[v]: if u != p and not removed[u]: sz[v] += get_sz(u, v) return sz[v] def get_centroid(v: int, p: int, tree_sz: int) -> int: for u in adj[v]: if u != p and not removed[u] and sz[u] > tree_sz // 2: return get_centroid(u, v, tree_sz) return v def collect(v: int, p: int, dist: int, result: list[int]) -> None: result.append(dist) for u in adj[v]: if u != p and not removed[u]: collect(u, v, dist + 1, result) def solve(v: int) -> None: nonlocal total tree_sz = get_sz(v, -1) c = get_centroid(v, -1, tree_sz) removed[c] = True # Process child subtrees one at a time. # freq[d] = number of nodes seen so far (from previous subtrees + centroid) # at distance d from c. Initialized with the centroid at distance 0. freq: dict[int, int] = {0: 1} for u in adj[c]: if not removed[u]: dists: list[int] = [] collect(u, c, 1, dists) # Count pairs: one endpoint in this subtree, one in a previous subtree or c. for d in dists: total += freq.get(k - d, 0) # Add this subtree's distances for future subtrees. for d in dists: freq[d] = freq.get(d, 0) + 1 for u in adj[c]: if not removed[u]: solve(u) solve(0) return total
Four Problems That Suddenly Get Easy
Offline path counting. Count pairs of nodes satisfying a property (distance = k, path sum divisible by p, number of distinct values on path ≥ k). At each centroid, you collect information from nodes in its component and combine contributions across different subtrees. The sequential subtree trick (described above) keeps same-subtree pairs from contaminating the count.
Nearest-node queries. Given a set S of "colored" nodes, find the nearest colored node for each query. Precompute distances from every node to each of its O(log n) centroid ancestors. On a "paint v" operation, walk v's centroid ancestors and update the minimum distance stored at each. On a query for u, walk u's ancestors and take the global minimum. Both operations cost O(log n).
Dynamic path queries with updates. Standard LCA-based distance formulas handle static queries, but updates break them. Centroid decomposition keeps per-centroid data that updates in O(log n) time per painted node, so it handles both operations online.
K-th nearest in the tree. Binary search on the centroid tree combined with sorted distance lists handles "find the k-th closest node" in O(log²n) per query after O(n log n) preprocessing.
Five Signals This Problem Wants Centroid Decomposition
- The problem is about paths in a tree, not arbitrary subgraphs
- You need to count or optimize over all pairs, or handle many queries about paths
- The naive approach is O(n²) or O(nq) and n or q is around 10^5
- The problem says "weighted tree" with path-sum queries, suggesting distances matter
- You've already tried LCA-based approaches but updates break them
Worked Example 1: Count Pairs at Distance Exactly K
Problem: Given a tree with n nodes and an integer k, count unordered pairs (u, v) where the path from u to v has exactly k edges.
Why centroid decomposition? A path between u and v passes through exactly one centroid c in the decomposition (their LCA in the centroid tree). So counting all such paths decomposes into: for each centroid c, count pairs in c's component where dist(c, u) + dist(c, v) = k, with u and v in different subtrees.
Worked trace on a 5-node path: 1-2-3-4-5, k = 2
Step 1: Find centroid of whole tree {1,2,3,4,5}.
get_sz from node 1: sz = [1,2,3,2,1] (1-indexed)
Walk to heavy child: node 3 (sz=3, 5-3=2, max=3≤2.5? No. Walk to 3's heavy child...)
Actually: at node 1, upward=0, children={2: sz=4}. 4 > 5/2. Walk to 2.
At node 2, upward=1, children={3: sz=3}. 3 > 5/2=2. Walk to 3.
At node 3, upward=2, children={4: sz=2}. 2 ≤ 5/2=2. Centroid = node 3.
Step 2: Process centroid 3. freq = {0:1}.
Process subtree {1,2} (via node 2):
dists = [1 (node 2), 2 (node 1)]
d=1: freq[2-1=1] = freq[1] = 0 → total += 0
d=2: freq[2-2=0] = freq[0] = 1 → total += 1 (pair: node 3, node 1, path 3-2-1, length 2 ✓)
Add to freq: freq[1]=1, freq[2]=1
Process subtree {4,5} (via node 4):
dists = [1 (node 4), 2 (node 5)]
d=1: freq[2-1=1] = 1 → total += 1 (pair: node 2, node 4, path 2-3-4, length 2 ✓)
d=2: freq[2-2=0] = 1 → total += 1 (pair: node 3, node 5, path 3-4-5, length 2 ✓)
Add to freq: freq[1]=2, freq[2]=2
After centroid 3: total = 3.
Step 3: Recurse on {1,2}. Centroid = node 2. freq = {0:1}.
Process subtree {1}: d=1, freq[2-1=1]=0. total += 0.
Recurse on {1}: leaf. Contributes 0.
Step 4: Recurse on {4,5}. Centroid = node 4. freq = {0:1}.
Process subtree {5}: d=1, freq[2-1=1]=0. total += 0.
Recurse on {5}: leaf. Contributes 0.
Final total = 3.
Verify by hand: pairs at distance 2 are (1,3), (2,4), (3,5). Count = 3. Correct.
 The sequential subtree scan counts all three pairs through centroid 3 in one pass, with no inclusion-exclusion needed.
The sequential subtree scan counts all three pairs through centroid 3 in one pass, with no inclusion-exclusion needed.
Worked Example 2: Nearest Painted Node After Updates
Problem: You have a tree of n nodes. Initially all are unpainted. Process Q operations: either paint a node, or query the distance from a node u to the nearest painted node.
Why centroid decomposition? Each node v has O(log n) centroid ancestors. For a paint operation on v, update the "minimum distance" stored at each centroid ancestor c: best[c] = min(best[c], dist(c, v)). For a query at u, walk u's O(log n) centroid ancestors and return min over all ancestors c of (dist(c, u) + best[c]).
Why does this work? The path from u to any painted node v passes through some centroid c (the LCA of u and v in the centroid tree), so dist(u, v) = dist(u, c) + dist(c, v) ≥ dist(u, c) + best[c]. The minimum over u's O(log n) centroid ancestors is always the correct nearest-node distance.
Setup cost: Precompute dist[v][i] = distance from node v to its i-th centroid ancestor. At each of the O(log n) levels, a single DFS pass touches O(n) nodes total across all components at that level. So precomputing all ancestor distances costs O(n log n) time and space.
Per operation cost: O(log n). Walk the O(log n) centroid ancestors of the target node.
This pattern (precompute distances to centroid ancestors, then handle updates and queries via ancestor walks) generalizes to many variants: nearest red node, nearest node with value divisible by p, minimum-weight path to any special node.
The Short Version
- A centroid is a node whose removal leaves all components with at most ⌊n/2⌋ nodes. Every tree has 1 or 2 centroids.
- Centroid decomposition builds a second tree by recursively finding centroids. Its depth is O(log n).
- Every path (u, v) in the original tree passes through the LCA of u and v in the centroid tree. This is the invariant that makes path decomposition correct.
- Building the decomposition costs O(n log n): O(n) work per level, O(log n) levels.
- Each node belongs to O(log n) components, so per-node ancestor walks are O(log n).
- Use the
removed[]array to logically delete processed centroids without modifying the adjacency list. - Process child subtrees sequentially (not all at once) to avoid counting same-subtree pairs without explicit inclusion-exclusion.
- Python's 1000-frame recursion limit applies to
get_sz, not justbuild. Increase it withsys.setrecursionlimit(n + 10).
If you want to practice explaining centroid decomposition out loud under time pressure (the way you will in an actual interview), SpaceComplexity runs voice-based mock interviews on exactly this kind of advanced tree problem, with rubric-based feedback on both your reasoning and your communication.
The segment tree covers efficient range queries built on similar decomposition ideas. The binary search tree article covers the BST invariant that underpins the centroid tree structure. For weighted-distance variants, Dijkstra's algorithm is often run from each centroid to precompute exact distances.