Counting Sort vs Radix Sort: One Question Decides Which You Need
- Counting sort is O(n + k): cheap when k is small, unusable when k is 32 bits (16 GB count array).
- Radix sort decomposes k into d passes over base b each costing O(n + b), making large k manageable without a giant count array.
- The decision criterion: k ≤ ~2n favors counting sort; k >> n (like 32-bit integers) means radix sort wins by orders of magnitude.
- Radix sort requires a stable counting sort subroutine; the right-to-left fill is what makes counting sort stable, and the entire LSD correctness proof depends on it.
- Base 256 is the practical sweet spot: the 1 KB count array fits in L1 cache, giving four fast passes over 32-bit integers with no cache thrashing.
- Both algorithms bypass Ω(n log n) by reading values as array indices rather than making any comparisons.
You have a million random integers between 0 and 120. Counting sort handles this in a single pass. You have a million random 32-bit integers. Now counting sort would need a count array with 4 billion entries. That's 16 gigabytes just to track occurrences.
Turns out O(n) has a footnote.
The counting sort vs radix sort decision comes down to one question: how large is k, the range of possible values, relative to n? Small k means counting sort. Large k means radix sort. The reasoning falls out of how each algorithm spends its time.
Why These Two Algorithms Belong Together
Counting sort was invented by Harold Seward in 1954 as part of his MIT master's thesis on applying computers to business data. Radix sort is older: Herman Hollerith used a column-by-column sorting scheme for his 1890 US Census punch-card tabulators. Sorting was literally how IBM got its start.
Seward's 1954 paper also described using counting sort as an efficient subroutine inside radix sort. One invented the subroutine. The other needed it.
Radix sort does not work without a stable subroutine, and counting sort is the canonical stable subroutine. Understand one deeply and you get the other almost for free.
Counting Sort: Values as Indices
Counting sort skips comparisons entirely. It reads values as indices into a count array, tallies occurrences, then reconstructs the sorted output.
The algorithm runs in three phases. Given integers in [0, k):
def counting_sort(arr, k): count = [0] * k for x in arr: count[x] += 1 # phase 1: tally for i in range(1, k): count[i] += count[i - 1] # phase 2: prefix sum output = [0] * len(arr) for x in reversed(arr): # phase 3: place right-to-left count[x] -= 1 output[count[x]] = x return output
Phase 1 counts each value. Phase 2 converts those counts into output positions: after the prefix sum, count[v] equals the index just past the last slot reserved for value v. Phase 3 fills the output.
The right-to-left iteration in phase 3 is not a style choice. Change it to left-to-right because it reads more naturally, and you have just introduced a bug that only appears on inputs with repeated values, which is every real dataset. Stable means equal elements appear in the output in the same relative order as the input. If two records share a sort key, the one that came first in the input comes first in the output. For a plain integer sort this seems like a footnote. For radix sort it is the whole proof.

Three phases on arr = [3, 1, 2, 1, 0, 3], k = 4. Colors track each value through the count array. Right-to-left fill in phase 3 is what makes it stable.
Complexity: O(n + k) time and O(n + k) space. You touch each of n elements in phases 1 and 3, and walk the count array of size k in phase 2. Total work: O(2n + k + n) = O(n + k).
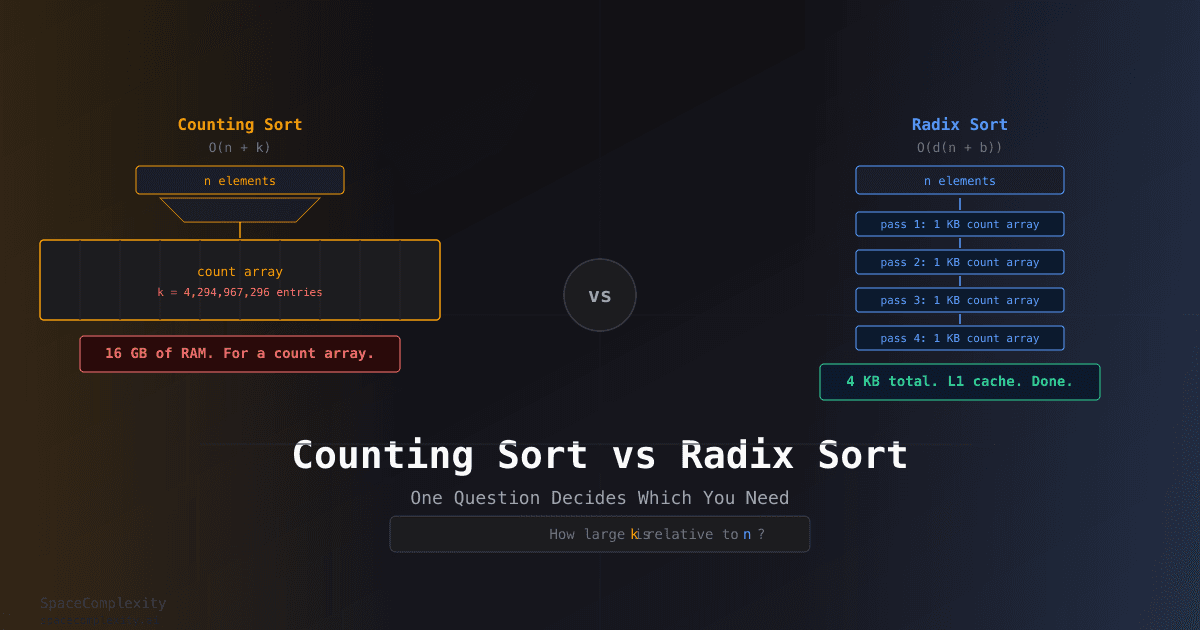
The constraint is that k must be manageable. For k up to about 10^6, counting sort is fast and the count array is small (4 MB). For k = 2^32, the count array is 16 GB. That's where radix sort comes in.
Radix Sort: Counting Sort, Applied Per Digit
Radix sort solves the large-k problem by refusing to sort on the full value. Instead it sorts on one digit at a time, making many cheap passes rather than one expensive pass.
LSD (Least Significant Digit) radix sort processes digits right to left. For 32-bit integers in base 256 (one byte per digit), four passes suffice:
def radix_sort(arr): for shift in range(0, 32, 8): # passes on bytes 0, 1, 2, 3 key = lambda x: (x >> shift) & 0xFF arr = stable_counting_sort_by_key(arr, key=key, k=256) return arr
Each pass uses counting sort over the range [0, 256). The count array is 256 entries, or 1 kilobyte. That fits comfortably in an L1 cache line. Every access during a pass is a cache hit. Your profiler is quiet. Enjoy it.

Sorting [32, 13, 31, 22]. After pass 1, 32 appears before 22 (both have ones digit 2, 32 came first). After pass 2, 31 appears before 32 (both have tens digit 3, 31 came first). Stability carries the ordering forward each pass.
The LSD order matters. You must process from least significant to most significant. The stability of each pass is what preserves the work done by earlier passes. After sorting by the ones digit, the array has correct ones-digit order. When you sort by the tens digit, equal tens-digit values must stay in their ones-digit order. Stable counting sort does that. Unstable counting sort scrambles the order.
CLRS Lemma 8.3 formalizes this as an induction: assume the low-order d-1 digits are correctly sorted, show that a stable sort on digit d preserves that. The induction holds because stability guarantees exactly the preservation property you need.
MSD radix sort works the opposite direction (most significant digit first), partitioning into buckets recursively. It does not need a stable subroutine because each subproblem is handled independently. The tradeoff is significantly more complex implementation and overhead managing recursive subproblems.
The Complexity, Derived
Counting sort on integers in [0, k) costs O(n + k).
Radix sort with d digit positions and base b costs O(d(n + b)). Each of d passes runs counting sort with key range [0, b). One pass costs O(n + b). Multiply by d.
For 32-bit integers in base 256:
d = 32 / 8 = 4
b = 256
Total: O(4(n + 256)) = O(n) when n >> 256
Counting sort on the same integers would cost O(n + 2^32). That's O(n + 4 billion). For n = 10 million, the k term dominates by 400x. You wanted O(n). You got O(please no).
The base b is a tuning parameter with a real tradeoff. The expression O(d(n + b)) = O(log_b(k) * (n + b)) is minimized (ignoring cache) when b ≈ n, giving O(n log(k) / log(n)). At n = 10 million, that means a 40 MB count array that thrashes the cache on every access. b = 256 gives a 1 KB count array that lives in L1. Four passes at cache-friendly speeds beats two passes with constant cache misses. Going higher (b = 65536) cuts the pass count but the 256 KB count array spills into L2 or L3, and the miss penalty erases the gain. A trade only a theoretician would make.

b = 256 keeps the count array at 1 KB, L1-resident, and delivers four fast passes. Larger bases save passes but thrash the cache. Smaller bases avoid cache pressure but multiply the work.
Counting Sort vs Radix Sort: When Each Wins
The decision is quick once you know the numbers. The pivot is roughly k = 2n.
| Condition | Algorithm | Reason |
|---|---|---|
| k ≤ n | Counting sort | One pass, no subroutine overhead |
| k between n and n^2 | Radix sort | Decomposition beats blowup |
| k > n^2 | Radix sort | Counting sort would cost O(k) > O(n log n) |
| 32-bit or 64-bit integers | Radix sort | Fixed digit count, bounded base |
| Fixed-length strings | Radix sort | One pass per character position |
| k small constant (ages, grades, coin values) | Counting sort | Simplest, fastest |
Concretely: sort 10 million employee records by department code 0 to 49. That's n = 10^7, k = 50. Counting sort finishes in a single O(n + 50) = O(n) sweep. Radix sort would run multiple passes for no gain.
Flip it: sort 10 million 32-bit IP addresses. k = 2^32. Counting sort requires a 16 GB count array that won't even fit in RAM. Radix sort base-256 needs 1 KB per pass, runs 4 passes, and finishes in O(n). No contest.
Both algorithms escape the Ω(n log n) lower bound for comparison-based sorting by the same mechanism: they read values as indices, not as comparison inputs. The lower bound proof assumes comparisons. Neither algorithm makes any.
The Stability Trap
When you implement radix sort, something will tempt you to skip the right-to-left fill. "It's the same count," you'll say. "Just easier to read." Here's what that looks like:
# Left-to-right fill: O(n+k), but unstable. Breaks inside radix sort. def unstable_counting_sort(arr, key, k): count = [0] * k for x in arr: count[key(x)] += 1 for i in range(1, k): count[i] += count[i - 1] # same prefix sum output = [None] * len(arr) for x in arr: # LEFT to right reverses equal elements v = key(x) count[v] -= 1 output[count[v]] = x # last equal element lands leftmost return output
The prefix sum records ending positions. Iterating left to right places the first equal element at the rightmost slot for that key and the last at the leftmost. That reverses the relative order of equal-key elements, which is the definition of unstable. One iteration direction looks like an implementation detail. Inside LSD radix sort, it's a correctness bug.
The bug is subtle because the output looks nearly sorted. On random inputs the reversal is hard to notice. It becomes obvious on inputs where many records share a digit value, which is common: sort n=1000 records by their ones digit and roughly 100 will share each value. The fix is always the right-to-left fill. Not sometimes. Always.
This is why stable sort is worth understanding on its own. Stability in the subroutine is what the entire LSD correctness proof depends on.
The Picture at a Glance

Counting sort needs a single count array the full size of k. Radix sort pays for d small arrays of size b instead. For 32-bit integers, that is the difference between 16 GB and 4 KB.
- Counting sort: O(n + k). One pass. Direct. Fast when k is small. Blows up when k is large.
- Radix sort: O(d(n + b)). Multiple passes. Each pass is cheap. Handles large k by decomposing it.
- Radix sort calls counting sort. The two are not alternatives at the implementation level, only at the problem level.
- Base 256 is the practical sweet spot for integers. Count array = 1 KB per pass, fits in L1 cache.
- Stability in counting sort is what makes LSD radix sort provably correct. It's not optional.
- For n = 10^7 and 32-bit integers: counting sort needs 16 GB, radix sort needs 4 × 1 KB.
If you want to practice explaining these tradeoffs under interview pressure, SpaceComplexity runs voice-based mock interviews with rubric-scored feedback on exactly this kind of complexity reasoning.
Further Reading
- Counting sort (Wikipedia)
- Radix sort (Wikipedia)
- Radix Sort (GeeksforGeeks)
- Counting Sort (GeeksforGeeks)
- IBM card sorter (Wikipedia)
See also: Counting Sort Algorithm, Radix Sort Algorithm, Why Stable Sort Matters.