Distributed Lock System Design: The 45-Minute Interview Walkthrough
- Efficiency vs correctness is the first clarifying question: Redis SETNX is fine for efficiency locks (wasted work is recoverable) but wrong for correctness locks (data corruption isn't).
- Redis SETNX with a Lua release script is the simplest approach: sub-millisecond latency, hundreds of thousands of ops per second, single point of failure.
- Redlock quorums across five independent Redis masters for high availability but still exposes the GC pause problem and provides no fencing tokens.
- ZooKeeper and etcd use consensus to issue globally monotonic fencing tokens, the only implementation that survives a paused client resuming after its TTL has expired.
- Fencing tokens require the storage service to reject stale writes; the lock service alone cannot prevent a paused client from corrupting data after its lease expires.
- Thundering herd on release is solved with pub/sub notifications plus exponential jitter, not polling.
- Redlock and Redis Cluster are incompatible because Cluster shards by hash slot, which can place two nominally independent masters on the same physical node.
Two services want to write to the same database row at the same time. Your first instinct is a mutex. Smart. Now try that across five Kubernetes pods on three availability zones. It does nothing.
A distributed lock solves this. The distributed lock system design interview is deceptively hard because the naive answer, Redis SETNX, is correct for one use case and dangerously wrong for another. Everything that follows lives in the gap between those two.
What You're Actually Designing
Start by pinning down the use case. There are exactly two reasons to use a distributed lock, and they need completely different implementations.
Efficiency locks prevent wasted work. Two cron jobs both regenerating the same cache entry is annoying but recoverable. If one occasionally runs twice because of a race, nobody notices. Redis SETNX is fine here.
Correctness locks prevent data corruption. Two payment processors both debiting an account, two workers both sending a confirmation email, two inventory services both decrementing stock below zero. A failure here corrupts data. Redis SETNX is not fine here. You need consensus.
Your first clarifying question in the interview: which one are we building? The answer shapes every subsequent decision.
What the API Has to Guarantee
Three operations: acquire(resource, ttl_ms) returns a token or fails, release(resource, token) releases it (only the current holder can), and renew(resource, token, ttl_ms) extends the lease while still holding it.
The TTL is load-bearing. It is the only thing that saves you from deadlock when a lock holder crashes before calling release. Set it too short and you create the GC pause problem (more on that shortly). Set it too long and a crashed holder blocks everyone for minutes.
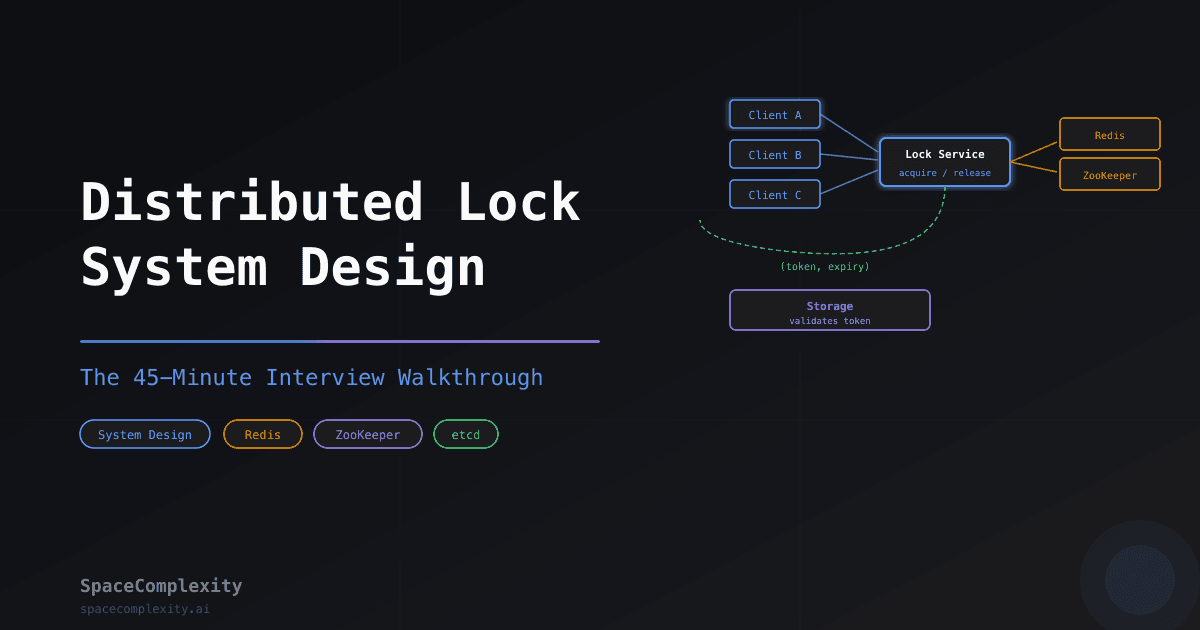
The Five-Box Sketch
Five boxes: clients, a lock service layer, the backing store cluster, a heartbeat/renewal path, and the storage system that the locks protect.
[Client A] ──┐
[Client B] ──┼──► [Lock Service] ──► [Redis / ZooKeeper / etcd cluster]
[Client C] ──┘ │
└──► returns (token, expiry)
│
Client presents token
│
[Storage Service]
checks token before write
 The storage service checking the token is not optional. Skip it and the safety guarantee collapses.
The storage service checking the token is not optional. Skip it and the safety guarantee collapses.
The storage service checking the token is not optional. This is the fencing token pattern, and skipping it breaks the entire safety guarantee. More on this below.
What Lives in the Lock Entry
A single lock entry needs four fields:
| Field | Type | Purpose |
|---|---|---|
resource | string | what is being locked (primary key) |
token | string / int64 | who holds it (UUID or monotonic counter) |
owner | string | client identifier for debugging |
expires_at | timestamp | when the lock auto-releases |
For Redis, this maps to a single key:
SET lock:payment:order_123 "token=abc123;owner=worker-7" NX PX 30000
For ZooKeeper and etcd, the token is built into the data model: ZooKeeper's zxid and etcd's revision are both globally monotonic counters, which makes them fencing tokens out of the box.
Implementation 1: Single-Node Redis
The simplest approach that actually works. Two atomic operations cover the full lifecycle.
Acquire (one command, atomic):
# SET key value NX PX ttl -- only if Not eXists, expires in milliseconds token = str(uuid4()) acquired = redis.set(f"lock:{resource}", token, nx=True, px=ttl_ms)
Release (Lua script, must be atomic):
-- Run as single Lua script to avoid check-then-act race if redis.call("get", KEYS[1]) == ARGV[1] then return redis.call("del", KEYS[1]) else return 0 end
The Lua script is not a nicety. Without it, a client whose lock just expired could delete the lock a second client legitimately holds. GET and DEL are two separate operations. Someone will fall through that window.
Latency: sub-millisecond. Throughput: hundreds of thousands of operations per second. Failure model: single point of failure. If Redis goes down, all lock acquisition fails.
This is enough for efficiency locks. The Ticketmaster system design uses exactly this pattern: Redis SET NX EX as a first-pass soft hold, backed by a database UNIQUE constraint as a second guard. For correctness locks, keep reading.
Implementation 2: Redlock (Multi-Node Redis)
Redlock, described in the official Redis documentation, spreads the lock across N independent Redis masters (typically five). The lock is acquired only when a quorum (at least three of five) grants it, and only if the total acquisition time is less than the TTL.
The validity window is:
MIN_VALIDITY = TTL - (T_acquire_end - T_acquire_start) - CLOCK_DRIFT
If MIN_VALIDITY is negative, abort and release all partial locks.
Redlock handles single-node failures. Three of five masters can go down and the service keeps working. But Redlock still has the GC pause problem, and Martin Kleppmann's 2016 analysis explains exactly why.
The Failure That Breaks Both Redis Approaches
This is the non-obvious insight that separates a strong answer from a weak one.
 Debugging race conditions. Fun every time.
Debugging race conditions. Fun every time.
Client 1 acquires the lock. Then it pauses. This pause can be:
- A stop-the-world garbage collection run (your JVM has opinions about when to pause, and they do not coincide with your SLA)
- A VM being live-migrated to another host (your cloud provider is just moving furniture)
- A network packet stuck in a congested router for 90 seconds (this happened to GitHub, and yes, they wrote about it)
While Client 1 is paused, the TTL expires. Client 2 acquires the lock. Client 1 resumes, has no idea time passed, and proceeds to write. Both clients believe they hold the lock. Both write. Data is corrupted.
 The GC pause problem. Client 1 wakes up blissfully unaware that 30 seconds passed and two other services took over.
The GC pause problem. Client 1 wakes up blissfully unaware that 30 seconds passed and two other services took over.
No TTL value prevents this. If the pause is longer than the TTL, you lose. Shorter TTLs just make the window smaller, not zero.
The Actual Fix: Fencing Tokens
The fix requires the storage service to participate. Every time a lock is granted, the lock service issues a fencing token: a number that strictly increases with each acquisition. Client 1 gets token 33, pauses, expires. Client 2 gets token 34, writes successfully. Client 1 resumes with stale token 33. Storage sees it is lower than 34. Rejected.
The fencing token pattern requires the storage service to check and reject stale tokens. The lock service alone cannot enforce this.
 Token 33 walks up to storage. Storage says "I've seen 34, you're done." Token 33 cannot argue.
Token 33 walks up to storage. Storage says "I've seen 34, you're done." Token 33 cannot argue.
ZooKeeper's zxid and etcd's revision are fencing tokens. Every write to either system atomically increments a global counter. You pass this counter to your storage service as the token. Redis does not generate monotonically increasing tokens by default (UUIDs have no order). This is why Kleppmann recommends ZooKeeper or etcd for correctness locks.
Implementation 3: ZooKeeper / etcd
ZooKeeper implements fair locking via sequential ephemeral nodes. To acquire the lock on payment/order_123:
- Create an ephemeral sequential znode:
/locks/payment_order_123/lock-gets a suffix likelock-0000000007. - List all children, sort by sequence number.
- If you have the lowest number, you hold the lock.
- If not, watch the node with sequence number just below yours. When it disappears (owner released or crashed), re-check.
 Everyone watches only the person ahead of them in the queue. One release, one wakeup.
Everyone watches only the person ahead of them in the queue. One release, one wakeup.
Ephemeral nodes auto-delete when the session disconnects. A crashed holder never leaves a zombie lock. Watching only the immediate predecessor avoids the herd effect: a single release triggers one notification, not a broadcast to all waiters.
etcd uses a lease plus revision approach. PUT a key attached to a TTL-bound lease, compare revision numbers to determine winner, run a keepalive loop to hold it. If the keepalive stops, the lease expires and the key disappears. Both systems guarantee their token (zxid / revision) is globally monotonic. Safe for correctness locks.
Where This Breaks Under Load
Hot locks. A single heavily-contested resource (say, the lock for account user_12345) serializes all writes for that account. You cannot shard a single lock. The mitigation is to design the resource namespace so hot locks do not exist: lock at a finer granularity, or use optimistic concurrency (CAS).
Thundering herd on release. If 500 clients are waiting and one lock releases, polling sends 500 simultaneous re-acquisition attempts. Use pub/sub notifications (Redis SUBSCRIBE, ZooKeeper watches, etcd watches) with exponential jitter instead. The push vs pull tradeoff is the same pattern.
Redlock and Redis Cluster are incompatible. Redis Cluster shards keys by hash slot. Redlock requires five independent masters. Run Redlock against a Redis Cluster and the same key can land on the same physical node in two "independent" masters, breaking the majority guarantee. The key-value store design covers hash slot sharding in detail. This is the kind of subtle trap that makes or breaks a strong system design answer.
Lock service as a bottleneck. For millions of locks per second, partition the namespace: order: locks to shard A, inventory: locks to shard B. Each shard is an independent cluster.
The 45-Minute Clock
0- 5 min Clarify: efficiency vs correctness? TTL? Renewal? Scale (QPS)?
5-12 min High-level: 5-box diagram (clients → lock service → backing store → storage)
12-20 min Data model + API (acquire/release/renew, token structure)
20-32 min Implementation depth: Redis → Redlock → ZooKeeper/etcd, with tradeoffs
32-40 min Failure modes: GC pause, clock skew, network delay; fencing token fix
40-45 min Scaling: hot locks, thundering herd, Redlock + Cluster incompatibility
Distributed Lock System Design: Tradeoffs at a Glance
| Single Redis | Redlock (5 nodes) | ZooKeeper / etcd | |
|---|---|---|---|
| Latency | <1ms | 5-50ms | 1-10ms |
| Safety | probabilistic | probabilistic | strong (consensus) |
| Fencing tokens | no | no | yes (built-in) |
| Complexity | low | medium | high |
| Right for | efficiency locks | efficiency + HA | correctness locks |
Google's Chubby (OSDI 2006) is essentially ZooKeeper's design: a five-node Paxos cluster issuing sequencers (fencing tokens) with every lock grant. Bigtable and GFS use Chubby for master election. When Google needs correctness, they use consensus.
Recap
- Decide efficiency vs correctness before designing anything.
- Single-node Redis: fast, simple, single point of failure, good for efficiency locks.
- Redlock: survives node failures, still has the GC pause problem, still no fencing tokens.
- ZooKeeper / etcd: consensus-based, strong safety, built-in fencing tokens, higher complexity.
- The fencing token pattern requires the storage layer to reject stale writes. The lock service cannot do this alone.
- Thundering herd: use pub/sub notifications, not polling.
- Redlock and Redis Cluster are incompatible.
If you want to rehearse explaining this under interview pressure, with someone asking follow-up questions about failure modes and tradeoffs, SpaceComplexity runs voice-based mock interviews on exactly this class of system design problem.
Further Reading
- How to do distributed locking: Martin Kleppmann's foundational analysis, with the GC pause problem and fencing token solution
- Distributed Locks with Redis (Redlock): Official Redis documentation on the Redlock algorithm
- The Chubby lock service for loosely-coupled distributed systems: Mike Burrows, OSDI 2006, the blueprint for production distributed lock services
- ZooKeeper: Wait-free coordination for internet-scale systems: USENIX ATC 2010, the original ZooKeeper paper
- Distributed lock manager: Wikipedia overview of distributed lock managers