Design a Distributed Unique ID Generator: System Design Interview Guide
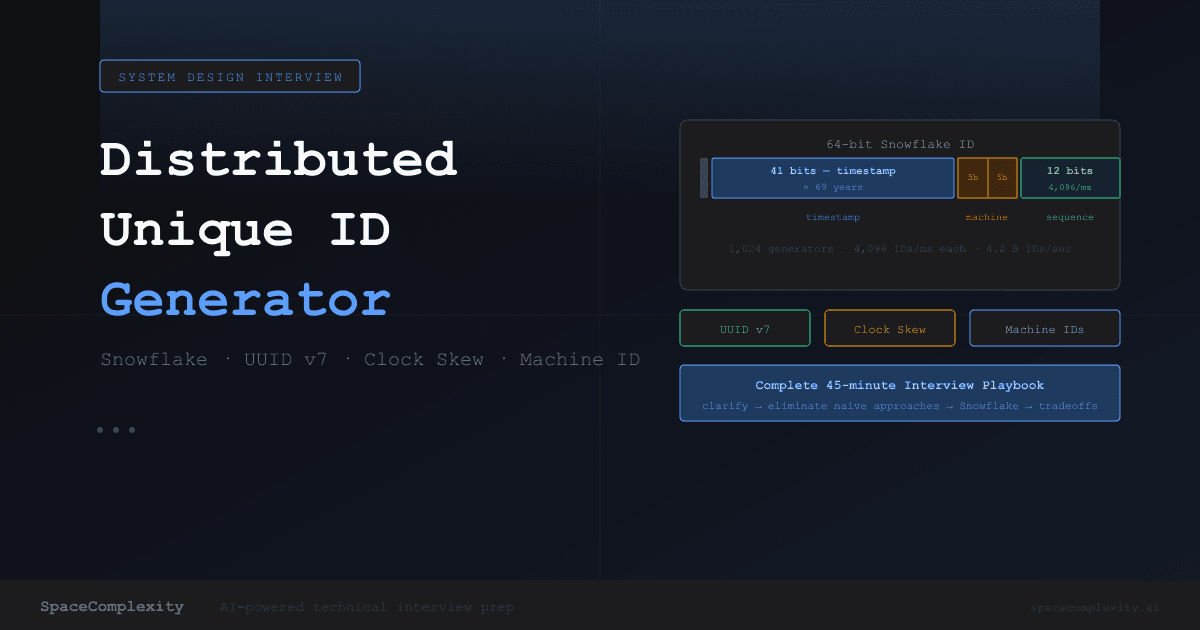
- Snowflake IDs pack a 41-bit timestamp, 10-bit machine ID, and 12-bit sequence into 64 bits, delivering 4B+ IDs per second without any coordination overhead.
- UUID v4 destroys B-tree performance at scale because random keys cause page splits and cache misses; UUID v7 fixes this with a time-ordered high-bit prefix.
- Clock skew is Snowflake's main failure mode: refuse ID generation when time moves backward, wait for the clock to catch up, and alert loudly.
- Machine ID assignment via etcd or ZooKeeper with TTL leases is the production solution for dynamic auto-scaling fleets.
- JavaScript truncation is the most commonly missed gotcha: 64-bit Snowflake IDs exceed
Number.MAX_SAFE_INTEGER, so always serialize them as strings in API responses. - UUID v7 is the pragmatic default for moderate-throughput systems in 2026: time-ordered, 128-bit, coordination-free.
- The real interview signal is not memorizing the bit layout but naming which tradeoff you're making between coordination cost and ordering guarantees.
You have fifty application servers. Every one of them needs to mint a unique ID for a new row. The row appears in one of thirty database shards. Nothing can coordinate with anything else in real time. Go.
This is the distributed unique ID generator problem, and it shows up in system design interviews at virtually every company that runs at scale. It looks deceptively simple until you start pulling on the threads: ordering requirements, clock drift, machine identity, database insert performance. It tests whether you understand the tension between coordination (slow, reliable) and decentralization (fast, tricky).
Here is the complete walkthrough. Requirements to architecture to tradeoffs to the 45-minute clock. The theme is the same one that shows up in every distributed system: every design is a tradeoff, and the interview tests whether you can name which one you're making.
First, Clarify What "ID" Actually Means
Before touching the whiteboard, ask five questions. The answers determine the architecture.
1. Does ordering matter? "Roughly time-ordered" versus "strictly sequential" are completely different constraints. Roughly time-ordered is achievable without coordination. Strictly sequential requires a centralized counter.
2. What is the maximum throughput? 1,000 IDs per second is trivial. 10 million per second per datacenter changes everything.
3. Are these IDs user-visible? Public URLs that expose sequential integers leak business metrics (your competitor can count your orders). Opaque IDs matter for business reasons, not just security.
4. What is the ID's storage type? 64-bit integer or 128-bit string? This affects storage cost, join performance, and whether languages handle it safely. JavaScript's Number.MAX_SAFE_INTEGER is 2^53, which truncates 64-bit Snowflake IDs. JavaScript is helpful like that.
5. Is the system multi-region? Single datacenter is one problem. Cross-region is a much harder problem because clock skew between regions can reach seconds.
The canonical interview answer lands somewhere like: unique globally, 64-bit integer, time-ordered within a reasonable window, 100K IDs per second per service, single region.
Why the Obvious Answers Break
Three approaches seem obvious. All three fail at scale.
Auto-Increment Requires a Single Primary
Every SQL database has AUTO_INCREMENT. You insert a row, the database assigns the next integer. Simple.
The problem: in a distributed system, this approach requires funneling every ID request through a single primary. That primary becomes a write bottleneck and a single point of failure. Even with replicas, the coordination overhead caps you at thousands of IDs per second, not millions. When the primary goes down, the entire write path stops.
Some teams have run two ticket servers in a hot-standby configuration, like Flickr did in 2010: one generates odd IDs, the other generates even IDs, both using MySQL's auto_increment_offset and auto_increment_increment. This eliminates the single point of failure. It doesn't eliminate the throughput ceiling or the cross-datacenter latency.
UUID v4 Destroys B-Tree Performance
A UUID is 128 bits of random data. No coordination. No clock. Very low collision probability (the birthday problem at 2^122 is forgiving). Every machine generates its own.
The problem: random primary keys destroy B-tree performance. A B-tree index is most efficient when new keys land at the right edge of the tree, because that is where the hot page is cached. A random UUID lands at a random position inside the tree, forcing a page lookup, a potential page split, and a cache miss. At scale, benchmarks consistently show 5-10x worse insert throughput with UUIDv4 versus sequential keys, and 30-60% index fragmentation. On a 100-million-row table, this is catastrophic. You will notice during your 3am alert.
 Sequential keys always land at the right edge, keeping the hot page in cache. Random UUID keys scatter across all pages, causing cache misses and page splits on every insert.
Sequential keys always land at the right edge, keeping the hot page in cache. Random UUID keys scatter across all pages, causing cache misses and page splits on every insert.
The modern fix: UUID v7 (RFC 9562, finalized 2024) embeds a 48-bit Unix timestamp in the high bits, making it time-sortable. This recovers the sequential-insert property while keeping the 128-bit coordination-free structure. If you're starting a new system in 2026, UUID v7 is the right default for most use cases. Use it. Know it. Mention it.
The Standard Interview Answer: Snowflake
Twitter open-sourced Snowflake in 2010 to generate IDs for tweets. It remains the canonical answer for distributed unique ID generation in interviews because its design clearly expresses the tradeoffs.
A Snowflake ID is a 64-bit integer. That fits in a database bigint and safely in most language primitives (except raw JavaScript, which needs BigInt).
| 0 | 41 bits timestamp | 10 bits machine ID | 12 bits sequence |
^ ^ ^
sign bit datacenter + worker counter per ms
(always 0) (5 + 5 bits) (max 4096/ms)
Each field does a specific job:
Timestamp (41 bits). Milliseconds since a chosen epoch. Twitter uses November 4, 2010 UTC. At 41 bits, this gives you 2^41 milliseconds, roughly 69 years. After that, the IDs wrap. Someone will have to deal with this in 2079. It won't be you.
Machine ID (10 bits). Identifies the node generating the ID, split into 5 bits of datacenter ID and 5 bits of worker ID. This gives you 32 datacenters times 32 workers = 1,024 unique generators, each operating without coordination. If you need more than 1,024 generators, you have a different problem.
Sequence number (12 bits). A counter that resets every millisecond. With 12 bits, each machine can generate 2^12 = 4,096 unique IDs per millisecond. If you hit 4,096 within the same millisecond, you wait until the millisecond flips.
The total capacity: 1,024 machines times 4,096 IDs per millisecond = roughly 4.2 billion IDs per second system-wide. That is more than any real system needs.
Snowflake ID example (decimal): 1683680476235038720
Decoded:
Timestamp: 1683680476235 ms (May 9, 2023)
Machine ID: 1
Sequence: 0
Because the timestamp is in the most significant bits, IDs are naturally sorted by creation time within a millisecond window. Inserts into a B-tree go to the right edge. Cache locality is preserved. You get the performance of sequential IDs without a central counter.
 The 64-bit Snowflake ID broken into its four fields. Timestamp takes the high bits, which is what makes IDs time-ordered and B-tree friendly.
The 64-bit Snowflake ID broken into its four fields. Timestamp takes the high bits, which is what makes IDs time-ordered and B-tree friendly.
Snowflake Has Two Problems Hiding Underneath
The bit layout is clean. Two problems live underneath it.
Clocks Go Backward
This sounds like a solved problem. It is not.
Snowflake assumes every machine's clock moves forward. But clocks drift. NTP can synchronize clocks to within a few milliseconds on a local network, but under load, during a network partition, or across datacenters, skew can reach seconds.
If machine A's clock jumps backward by 500ms, it will mint IDs with timestamps earlier than IDs it already generated. Those IDs are no longer ordered. Worse, they might duplicate IDs from 500ms ago if the sequence numbers align.
The standard defense: if the current time is before the last recorded timestamp, refuse to generate IDs and wait until the clock catches up. Log an alert. For small skews (a few milliseconds), you stall briefly. For large skews, you have a bigger infrastructure problem. Some implementations add a generation counter to the machine ID field instead of relying purely on physical time, but that departs from the original Snowflake model.
 When NTP corrects the clock backward, the ID generator stalls and waits. It never mints an ID with a timestamp in the past.
When NTP corrects the clock backward, the ID generator stalls and waits. It never mints an ID with a timestamp in the past.
Who Hands Out Machine IDs?
Who assigns the machine ID? This is where the happy path ends. Snowflake was statically configured: each server was given a machine ID at deployment. That works for a stable fleet but breaks the moment you have auto-scaling.
The practical solutions, in order of complexity:
Manual configuration. Each machine gets a machine ID in its config file. Works at small scale. Falls apart when machines spin up automatically.
Zookeeper or etcd. Each generator requests a machine ID from a coordination service on startup, which hands out the next available ID and records which IDs are live. When the machine shuts down, the ID is returned to the pool. This is what large systems use.
IP address or MAC address hashing. Hash the machine's IP into the 10-bit field. Cheap, no coordination, but hash collisions become possible as the fleet grows. With 1,024 slots and a decent hash function, collision probability is low until you pass several hundred machines, at which point the birthday bound applies exactly as it does in hash tables.
Machine ID assignment via coordination service (etcd):
Worker starts
|
Requests machine ID from etcd
|
etcd atomically assigns next available slot (0-1023)
|
Worker stores ID in memory, registers TTL lease
|
On shutdown: etcd lease expires, slot returned to pool
What You Draw on the Whiteboard
 The full architecture. Workers are stateless and horizontally scalable. The only coordination happens at startup when a worker requests its machine ID from etcd.
The full architecture. Workers are stateless and horizontally scalable. The only coordination happens at startup when a worker requests its machine ID from etcd.
Workers hold no persistent storage. Each worker keeps its machine ID in memory (obtained at startup) and a monotonic last-timestamp counter to detect clock skew. ID generation is entirely in-process. No network call happens during normal operation.
ID generation in Snowflake is a memory operation, not a network operation. Latency is nanoseconds, not milliseconds. You can serve 100K requests per second from a single small worker without breaking a sweat.
The Service Needs Two Endpoints
The API is minimal by design.
POST /id
Response: { "id": 7258012948234567680 }
POST /ids?count=100
Response: { "ids": [7258012948234567680, 7258012948234567681, ...] }
Batch generation is worth raising in an interview. If a client needs to generate 1,000 IDs to bulk-insert rows, making 1,000 individual HTTP calls is absurd. The batch endpoint generates a range of IDs atomically within the worker and returns them in one response. Sequence numbers handle this naturally: generate 100 IDs by incrementing the sequence 100 times within a single millisecond bucket.
The service is stateless and horizontally scalable. Add workers as needed. Put them behind a load balancer with health checks. No coordination between workers during normal operation.
Where It Breaks Down
Throughput ceiling. A single Snowflake worker can generate ~4M IDs per second before hitting the sequence number ceiling. In practice, you add workers for fault tolerance before you add them for throughput.
The JavaScript problem. 64-bit integers exceed Number.MAX_SAFE_INTEGER (2^53). Sending a raw integer in JSON silently corrupts IDs in JavaScript clients. No error. No warning. Your order ID quietly becomes a slightly different order ID. Serialize Snowflake IDs as strings in API responses and parse them back to BigInt in the client. Raise this proactively in the interview. Do it before the interviewer does. Silence about the JS bug signals you've never shipped this to production.
Datacenter expansion. You have 10 bits for machine ID split 5+5. If you outgrow 32 datacenters or 32 workers per datacenter, you can rebalance the split (say, 3 datacenter bits + 7 worker bits), or add bits by shrinking the sequence number field. Changing the layout requires a migration and a new epoch.
Multi-region. If you run generators across geographic regions, clock skew becomes harder to manage. Some systems add a region prefix to the ID, making it 128 bits, and accept that IDs from different regions aren't interleaved by time. Others use GPS-disciplined clocks or cloud-provider time services (AWS Time Sync Service uses GPS and atomic clocks, typically accurate to within a microsecond) to reduce skew to negligible levels.
What to Reach for Instead
UUID v7. If your throughput is moderate and you don't want the machine ID management overhead, UUID v7 gives you time-ordered 128-bit IDs with no coordination. The cost is 16 bytes versus 8 bytes per ID, and slightly worse throughput per machine due to the larger size. For most systems in 2026, this is the pragmatic default.
ULID. Universally Unique Lexicographically Sortable Identifier. 128 bits, time-ordered, Crockford Base32 encoded. Similar properties to UUID v7. No widely agreed standard for the machine ID component; relies on randomness to avoid collisions. Good for small-scale systems.
MongoDB ObjectID. 12 bytes: 4-byte timestamp + 5-byte machine identifier + 3-byte incrementing counter. Similar idea to Snowflake but with fewer bits for throughput. ObjectIDs are not safe for high-cardinality event streams.
How to Run the Clock in 45 Minutes
This is where most candidates fall apart. They describe Snowflake correctly but can't time-box themselves.
| Time | What to do |
|---|---|
| 0-5 min | Ask the five clarifying questions. Write down the answers. Agree on scale. |
| 5-10 min | List the three naive approaches (auto-increment, UUID v4, ticket server) and eliminate each with one sentence. This shows you understand the problem space. |
| 10-25 min | Draw the Snowflake bit layout. Explain each field. State the two hard problems (clock skew, machine ID assignment). Propose the etcd solution for machine ID. |
| 25-35 min | Draw the architecture: worker pool, load balancer, coordination service. Describe the API. |
| 35-45 min | Handle follow-ups: JavaScript truncation bug, multi-region, UUID v7 comparison, capacity math. |
The capacity math. When the interviewer asks "can this scale to our needs," do the calculation out loud: 1,024 workers times 4,096 IDs per millisecond times 1,000 milliseconds per second = 4.19 billion IDs per second. Even at 1% of that (10 workers generating), you have 40 million IDs per second. That is enough for any realistic system.
Mention the JavaScript bug unprompted. This signals production awareness. Very few candidates bring it up.
If they push on multi-region, acknowledge the tradeoff directly: true global time-ordering requires global clock synchronization, which is hard. The pragmatic choices are either to use region-prefixed IDs (losing global ordering) or to rely on GPS-disciplined clocks and accept occasional skew-driven gaps.
The Short Version
- UUID v4: coordination-free, no ordering, B-tree performance disaster at scale
- Ticket server: simple, one or two nodes, throughput ceiling, SPOF risk
- Snowflake: 64-bit, time-ordered, fully decentralized generation, machine ID assignment needs a coordination service, JavaScript truncation is a production gotcha
- UUID v7: modern default for moderate-throughput systems, 128-bit, no coordination needed, worse storage cost than Snowflake
- Clock skew: refuse to generate IDs when time moves backward, wait it out, alert loudly
- Machine ID assignment: etcd or ZooKeeper with TTL leases for dynamic fleets
The real signal in this interview is not knowing the Snowflake bit layout by heart. It is knowing that every approach trades coordination cost for some other property, and being able to tell the interviewer which trade is right for their constraints.
Talking through those tradeoffs out loud under pressure, in real time, is a skill. If you want to practice it, SpaceComplexity runs voice-based system design interviews with rubric scoring across every dimension, including how clearly you communicate exactly this kind of layered tradeoff. Worth a session before the real thing.
Further Reading
- Snowflake ID (Wikipedia), canonical description of the 64-bit layout and Twitter's original design
- Ticket Servers: Distributed Unique Primary Keys on the Cheap (Flickr Engineering), the original Flickr ticket server post, the oldest public description of the problem
- RFC 9562: UUID v7, the IETF specification for time-ordered UUIDs, finalized 2024
- UUID v4 vs UUID v7 (GeeksforGeeks), practical breakdown of the database performance difference
- Design a Unique ID Generator (System Design Handbook), structured walkthrough of the problem in interview context