Dropbox System Design Interview: File Storage, Sync, and Conflicts
- Content-defined chunking (CDC) finds stable boundaries via rolling hash so only 1-2 chunks change per edit, not the whole file
- Content-addressable storage uses the SHA-256 chunk hash as the storage key, enabling cross-user deduplication that reportedly saved Dropbox 25% storage
- Presigned URLs route blob traffic directly from client to S3, keeping upload servers thin and stateless
- Shard metadata on owner_id so all of a user's files live on one shard; cache the chunk registry in Redis to avoid repeated DB hits
- Long polling beats WebSockets for file sync: server-to-client only, stateless enough to load-balance, and far simpler to operate at scale
- Conflict resolution is a product decision: Dropbox creates a "conflicted copy" instead of merging automatically, preserving both versions without distributed consensus
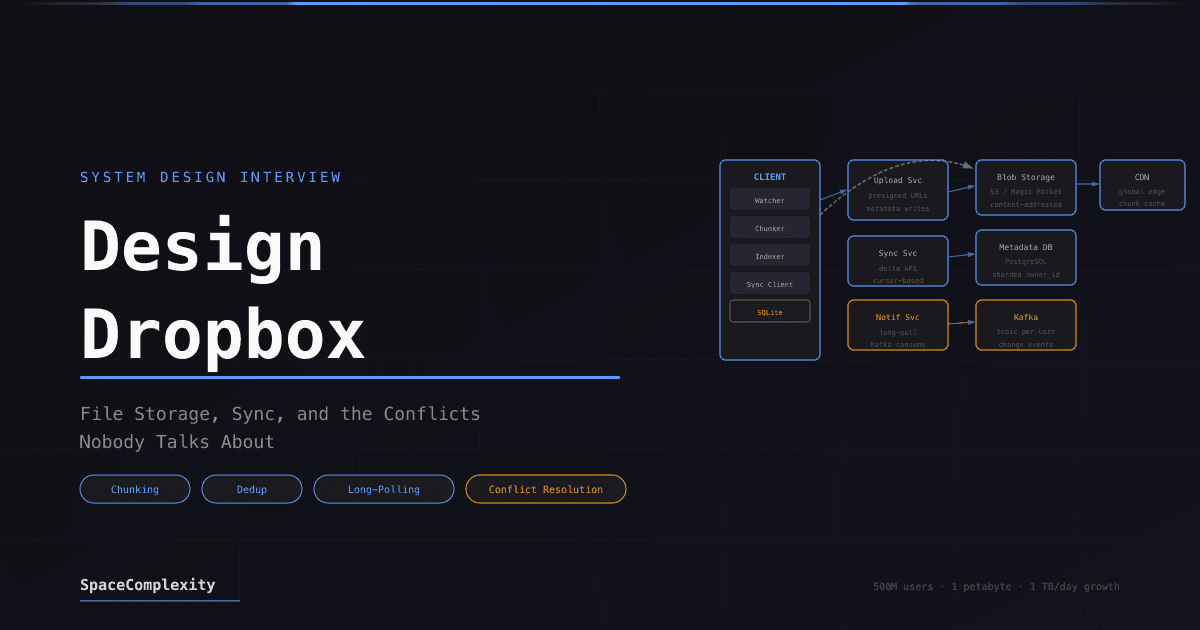
- The client is half the system: Watcher, Chunker, Indexer, and Sync client run locally to minimize what actually gets uploaded
Everyone can describe what Dropbox does in one sentence. Almost nobody can explain how it works without waving their hands at "the cloud." That gap is exactly where system design interviews live.
Your first instinct when someone says "design Dropbox" is to draw a box labeled Client, an arrow pointing right, and another box labeled S3. Understandable. Wrong. The storing-files part is almost trivial. The hard part is sync: two laptops, one file, both offline, one internet connection restored first. What happens to the file? That question, and a handful like it, is what the interviewer is actually waiting for.
Lock Down Requirements Before You Draw a Single Box
Before anything else, spend the first three to five minutes here. The interviewer wants to see that you don't start sketching architecture before you've read the spec. Every interviewer who has watched a candidate burn 15 minutes designing the wrong system knows why.
Functional requirements (agree on these):
- Users can upload and download files from any device
- Files sync automatically across a user's connected devices
- Users can share files and folders with other users
- File versioning: at least the last 30 days of history
- Folder hierarchy with nested directories
Out of scope (say this explicitly):
- Real-time collaborative editing (that's Google Docs, a different problem, a different interview, a different decade of engineering pain)
- Full-text search over file contents
- Video streaming
Non-functional requirements:
- Durability: no data loss, ever. Files are irreplaceable.
- Availability: 99.99% uptime. Sync can lag; data loss cannot happen.
- Consistency: eventual consistency for sync is acceptable. If you update a file on your laptop, your phone sees it within a few seconds, not instantly.
- Scale: 500 million users, 100 million daily active. Average 2 GB of stored data per user.
Run the Numbers Before You Draw Anything
Don't skip this. It forces you to size your system correctly, and interviewers watch whether you do it.
- 100M DAU, each uploading roughly 1 file per day on average
- Average file size: 500 KB (skewed by documents; the median is much smaller than the mean, and a single unoptimized Photoshop file will wreck the whole distribution)
- Upload traffic: 100M files/day at 500 KB = ~580 GB/day = ~7 MB/s sustained
- Peak is maybe 3x that: ~20 MB/s inbound
- Storage: 500M users × 2 GB = 1 petabyte total. Growing at ~1 TB/day.
- Reads dwarf writes: file downloads are 10x more frequent than uploads. Design the download path for scale.
The Two-Plane Architecture
 Two planes run through this system. The data plane moves bytes. The control plane moves events. If your upload servers are touching file bytes, you've collapsed the planes.
Two planes run through this system. The data plane moves bytes. The control plane moves events. If your upload servers are touching file bytes, you've collapsed the planes.
Two planes run through this design. The data plane moves bytes: upload to blob storage, download through CDN. The control plane moves metadata: what exists, where it lives, who changed what. Keep them separate. The upload path should never touch the metadata database for the actual bytes. Your application servers should never see a single file byte.
The Client Is Half the System
This is the insight most candidates miss. If you draw one box labeled "Client," fire an arrow at S3, and move on to talking about sharding, you've skipped the most interesting half of the design. The client is a sync engine with four distinct components.
Watcher monitors the local filesystem for changes using OS APIs: inotify on Linux, FSEvents on macOS, ReadDirectoryChangesW on Windows. When a file changes, it queues the event.
Chunker splits changed files into fixed-size blocks, typically 4 to 8 MB each. It also computes a SHA-256 hash for each chunk.
Indexer maintains a local SQLite database of files and their chunk hashes. When the chunker finishes, the indexer diffs the new hashes against its local state to determine which chunks actually changed.
Sync client coordinates uploads and downloads. It sends chunk hashes to the metadata service, receives a list of which chunks the server doesn't already have, and uploads only those.
This client-side intelligence is what makes sync efficient. Without it, editing a single byte in a 1 GB file would re-upload the whole thing. With it, only the changed chunk goes over the wire.
Chunking and Deduplication: The Core Trick
Every chunk is identified by its content hash. If the hash exists on the server, the chunk doesn't need to be uploaded. This is content-addressable storage.
The SHA-256 hash of a chunk is its storage key. Two users who have the same popular PDF share the same underlying chunks in blob storage. Dropbox reportedly achieved 25% storage savings from cross-user deduplication alone.
Fixed-size chunking (always 4 MB boundaries) has a problem. Insert a byte at the start of a file and every chunk boundary shifts. Suddenly all hashes are different even though almost nothing changed.
 Fixed chunking: one byte inserted, five chunks change. CDC: same edit, one chunk changes. This is why Dropbox uses Rabin fingerprinting instead of fixed offsets.
Fixed chunking: one byte inserted, five chunks change. CDC: same edit, one chunk changes. This is why Dropbox uses Rabin fingerprinting instead of fixed offsets.
Content-defined chunking (CDC) solves this by using a rolling hash (Rabin fingerprinting) to find chunk boundaries based on the content itself. The boundaries are stable across small edits. Insert a byte in the middle of a file, and only the one or two surrounding chunks change.
Mentioning CDC in an interview signals you've thought about the problem at a deeper level than most candidates. Bring it up before you leave the chunking section.
The hashes drive the hash table lookup at the heart of deduplication. Before any upload, the client sends a list of chunk hashes to the server. The server checks which ones are already in the chunk store and returns only the missing ones. The client uploads only those. For a typical re-save of a document you just edited, this is zero chunks for all but the modified section.
How a File Gets to the Server
 The presigned URL pattern. Steps 1-4 are tiny metadata requests through your servers. Step 5 is the actual bytes, going directly from the client to blob storage. Your fleet never sees them.
The presigned URL pattern. Steps 1-4 are tiny metadata requests through your servers. Step 5 is the actual bytes, going directly from the client to blob storage. Your fleet never sees them.
The upload sequence:
- Client chunker splits the file, computes SHA-256 hashes for each chunk
- Client sends chunk hashes to the Upload Service via POST
/upload/initiate - Upload Service queries Metadata DB: which of these hashes are new?
- Server returns presigned URLs for each new chunk (signed S3 or equivalent URLs with a 15-minute TTL)
- Client uploads chunks directly to blob storage using those presigned URLs (bypasses your servers entirely for the heavy bytes)
- Client confirms to Upload Service: "all chunks uploaded"
- Upload Service writes file metadata to Metadata DB and publishes a change event to the message queue
- Notification Service delivers the event to all other connected devices owned by this user
The presigned URL pattern keeps your upload servers thin. They handle small metadata requests, not gigabytes of file data. The bandwidth-intensive work happens directly between the client and blob storage. Your servers never see the bytes. If you're running your file bytes through application servers, you're paying to be a man-in-the-middle for no reason.
Five Tables and One Right Sharding Key
Four core tables, plus a junction. Keep it simple.
-- Users users ( user_id UUID PRIMARY KEY, email TEXT UNIQUE NOT NULL, quota_bytes BIGINT DEFAULT 2147483648 ) -- Files and folders (unified; is_folder distinguishes them) files ( file_id UUID PRIMARY KEY, owner_id UUID REFERENCES users, parent_id UUID REFERENCES files, -- NULL = root name TEXT NOT NULL, is_folder BOOLEAN DEFAULT FALSE, created_at TIMESTAMPTZ, deleted_at TIMESTAMPTZ -- soft delete ) -- Each save creates a new version file_versions ( version_id UUID PRIMARY KEY, file_id UUID REFERENCES files, created_at TIMESTAMPTZ, created_by UUID REFERENCES users, size_bytes BIGINT ) -- Chunk registry (content-addressable) chunks ( chunk_hash CHAR(64) PRIMARY KEY, -- SHA-256 hex size_bytes INT, storage_key TEXT -- path in blob storage ) -- Maps a version to its ordered chunks file_version_chunks ( version_id UUID REFERENCES file_versions, chunk_order INT, chunk_hash CHAR(64) REFERENCES chunks, PRIMARY KEY (version_id, chunk_order) )
Shard the metadata database on owner_id. Almost every query is "show me the files belonging to user X." Sharding on owner puts all of one user's data on one shard, which means single-shard queries for the common case and no cross-shard joins for normal operations.
The chunk registry is shared across all users and doesn't shard by owner. It's an append-only lookup table. Cache it aggressively; a chunk hash lookup that hits Redis never touches the DB.
Sync and Notifications: The Hard Problem
When you save a file on your laptop, your phone needs to know about it. The question is how.
Both options map directly to the push vs. pull tradeoff.
Long polling: the client connects, the server holds the connection open until there's a change (up to 30-60 seconds), then returns the change and the client immediately reconnects. This is what Dropbox actually does for their /files/list_folder/longpoll API. It's simple, stateless enough to load-balance, and doesn't require persistent TCP connections.
WebSockets: persistent bidirectional connection. Server pushes changes instantly. Better latency, but stateful (each connection is pinned to a server), and you don't actually need bidirectional here. The server talks; the client listens.
The right answer for an interview: long polling as the default, with an honest tradeoff discussion. WebSockets are better for latency but harder to operate at scale. Long polling adds one extra round trip per notification but is much simpler to manage.
 Client B's long-poll connection sits open waiting. When Client A saves a file, the event travels Upload Service → Kafka → Notification Service → Client B in under a second.
Client B's long-poll connection sits open waiting. When Client A saves a file, the event travels Upload Service → Kafka → Notification Service → Client B in under a second.
The notification flow:
- File change event published to a message queue (Kafka topic per user)
- Notification Service, which holds the user's long-poll connections, consumes the event
- Server responds to the open long-poll connection with "changes available"
- Client calls the sync API: GET
/sync/changes?cursor=<last_known_cursor> - Server returns changed files since that cursor
- Client downloads only the new/changed chunks
The cursor is the key to idempotency. Clients that miss a notification (dropped connection, backgrounded app) will catch up on next reconnect. The cursor is monotonically increasing, so "give me everything after cursor X" is always correct.
What Happens When Two Devices Both Edit Offline
Two devices, both offline, both edit the same file, one reconnects first. Two incompatible realities now exist, and your system has to pick a policy.
Dropbox's actual approach: last writer wins on metadata, but creates a "conflicted copy" for the user. The first upload goes through. When the second device reconnects and tries to upload, the metadata service detects a version conflict (the base version the client built on no longer matches the current version). Instead of silently overwriting, it saves the second device's version as "filename (Bob's conflicted copy 2026-05-27).pdf" and syncs both to all devices.
This is the pragmatic choice for a general-purpose file store. It preserves data, gives the user visibility, and doesn't require distributed consensus to resolve conflicts. The downside: users have to manually merge sometimes. For code files, this is mildly annoying. For most files (documents, photos, spreadsheets), it's fine and nobody notices.
A vector clock or operational transform approach would allow automatic merging, but that's essentially building Google Docs. Scope it out unless the interviewer explicitly asks.
Where This Breaks Under Load
Metadata DB read load. Reads are 10x writes. Add read replicas. Cache the hot path (file list, version list) in Redis with a short TTL. Shard by owner_id to keep each shard manageable.
Notification Service is stateful. Each long-poll connection lives on a specific server. You can't randomly route connections. Options: consistent hashing to route users to servers, or use a pub/sub layer (Redis pub/sub or Kafka) where any notification server can consume events for any user and wake its held connections.
Chunk deduplication at scale is a database query. The "which of these 50 hashes do you already have?" query hits the chunk registry millions of times per day. This table should live entirely in memory-backed storage (Redis or a fast KV store). It's read-heavy and append-only, so caching is safe.
Blob storage. Dropbox started on S3, then built Magic Pocket when the economics of S3 at petabyte scale became untenable. Magic Pocket uses erasure coding (instead of 3x replication) to store data durably at roughly 1.3x storage cost instead of 3x. In an interview, you don't need to design Magic Pocket. Say you'd start on S3, note that at exabyte scale you'd consider owned storage with erasure coding, and move on.
CDN for downloads. After the first download of a popular chunk, the CDN caches it. Subsequent downloads hit the CDN edge, not your origin. This is especially valuable for shared files: if 1,000 users have access to the same presentation, only the first download pulls from blob storage.
The Decisions That Define the System
| Decision | Choice | Why |
|---|---|---|
| Consistency model | Eventual | Durability > real-time sync. Lag is fine. |
| Chunking | Content-defined (CDC) | Stable boundaries after edits |
| Notification | Long polling | Simpler than WebSocket at scale |
| Conflict resolution | Create conflicted copy | Preserves data, avoids distributed consensus |
| Chunk identity | Content hash (SHA-256) | Enables deduplication, content-addressable |
| Upload path | Presigned URLs to blob storage | Keeps upload servers stateless |
| DB sharding key | owner_id | Queries are per-user; avoids cross-shard joins |
Pacing the 45-Minute Interview
Here's how to pace it:
- Minutes 0-5: requirements, functional and non-functional, explicit out-of-scope
- Minutes 5-10: back-of-envelope: users, storage, bandwidth, read/write ratio
- Minutes 10-20: high-level architecture, name every component, explain how data flows
- Minutes 20-30: deep dive on the two or three hardest parts (chunking + deduplication, sync + notifications, conflict resolution). The interviewer will redirect if they want different depth.
- Minutes 30-38: data model, APIs
- Minutes 38-45: scaling bottlenecks, tradeoffs, what you'd do differently with 10x more scale
The most common mistake is spending 20 minutes on the happy-path upload, producing a thorough design for an expensive S3 wrapper, and never getting to sync. Sync is the interesting problem. Front-load it.
If the interviewer interrupts to go deeper on something, that's a gift. It tells you what they care about. Follow their lead.
The Short Version
- The client-side sync engine (Watcher, Chunker, Indexer) is half the system, not a box you label and move past
- Content-defined chunking minimizes re-uploads after edits; fixed-size chunking breaks on insertions
- Content-addressable storage (SHA-256 chunk hash as key) enables both deduplication and incremental sync
- Upload flow uses presigned URLs so blob traffic bypasses your servers
- Shard metadata on owner_id; keep chunk registry in fast KV storage
- Long polling beats WebSockets here: server-to-client only, simpler to scale
- Conflict resolution is a product decision; Dropbox chose "conflicted copy" to preserve data
- Eventual consistency is the right call; sync lag is acceptable, data loss is not
If you want to practice walking through this out loud before your actual interview, SpaceComplexity runs realistic voice-based system design sessions with rubric feedback. Talking through a design under time pressure is a different skill from understanding it. Most candidates discover that gap the hard way.
Further Reading
- GeeksforGeeks: Design Dropbox - thorough breakdown of components and APIs
- Dropbox Tech: Inside the Magic Pocket - how Dropbox's actual exabyte-scale blob storage works
- Dropbox Tech: Low-latency notification of file changes - the real long-polling implementation
- Wikipedia: Content-addressable storage - the theory behind chunk deduplication
- Wikipedia: Erasure code - why 1.3x overhead beats 3x replication at scale