You Found the Linked List Cycle. Now Find Where It Starts.
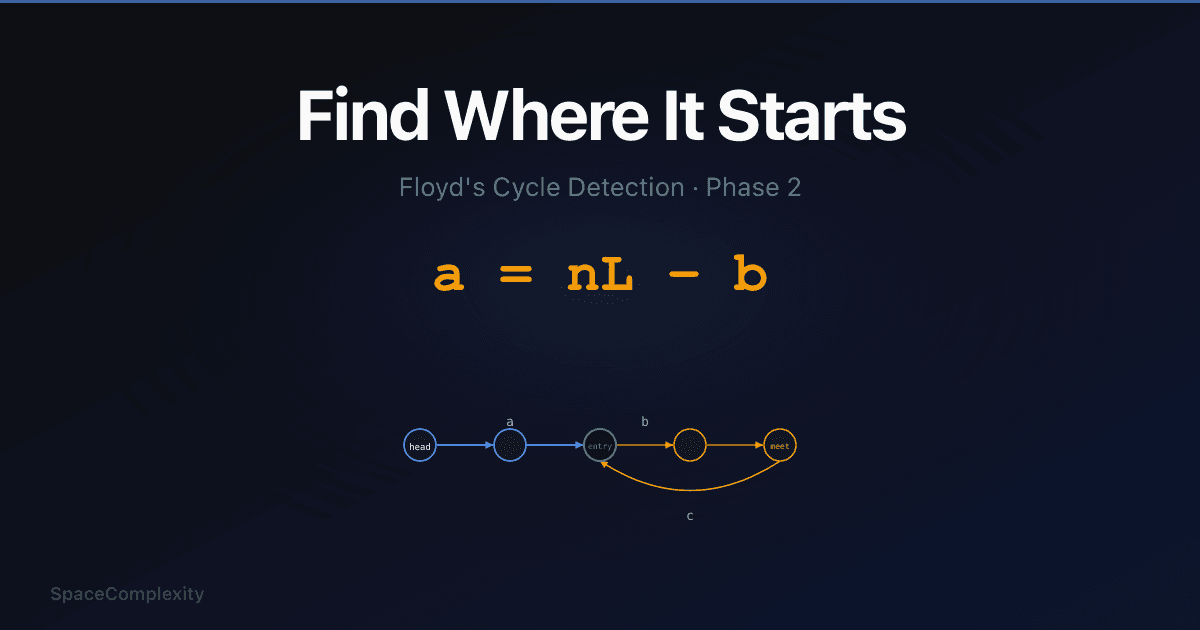
- Floyd Phase 2 resets one pointer to head after detection; advancing both at equal speed leads them to meet at the cycle entry node.
- The core identity
a = nL - bproves it: tail length equals forward distance from the meeting point to the cycle entry, padded by extra laps. - Identity comparison (
is,===,ReferenceEquals,equal?) is mandatory; value comparison produces false positives when distinct nodes share a value. - Both pointers must initialize at
head, nothead.next, to handle a = 0 (cycle at head) and single-node self-loops correctly. - LeetCode 142 (Linked List Cycle II) is the canonical form; LeetCode 287 (Find the Duplicate Number) is the same algorithm disguised as an array problem.
- The LeetCode 287 mapping works because the duplicate value equals the cycle entry index in the functional graph
i -> nums[i].
Part 1 got you to "yes, there is a cycle." Two pointers, one running at double speed, guaranteed to meet somewhere inside the loop. Your interviewer nods. Then leans forward: "Great. Now where does it start?"
That is the harder question. The answer fits in four lines of code. The proof takes a little more.
The Naive Fix You'll Immediately Think Of
Your first instinct is probably a hash set. Walk the list, record each node's address, and return the first node you see twice.
def detect_cycle_naive(head): seen = set() node = head while node: if node in seen: return node seen.add(node) node = node.next return None
This works. It's O(n) time and O(n) space. The hash set is the problem. In a constrained environment (embedded system, an interview where the interviewer just asked "can you do it with constant space?"), O(n) space is a dealbreaker. Floyd's Phase 2 eliminates it.

The hash set approach, if it had feelings. It works. But the cycle never ends.
Before the Proof: Name Three Distances
Precise names make the algebra workable. Three variables. That is the whole setup.

a is the tail, b and c split the cycle, L is the full loop. Everything else follows.
- a: nodes from head to cycle entry (the "tail length")
- L: total cycle length, where L = b + c
- b: distance from cycle entry to where slow and fast met
When Phase 1 ends, slow sits at the meeting point, b steps past the cycle entry. The cycle entry is somewhere behind it. We do not know a.
Phase 2: Four Steps to Find the Cycle Start
Phase 2 is almost insultingly simple:
- Keep one pointer at the meeting point.
- Reset the other pointer to head.
- Advance both one step at a time.
- Where they meet next is the cycle start.
No speed difference. No tricks. Two pointers crawling at the same pace until they collide. The place they collide is always the cycle entry. Yes, really. Here is why.
Why It Works: The Algebra
The key equation comes from Phase 1. When slow and fast meet:
- Slow has traveled:
a + bsteps - Fast has traveled:
a + b + nLsteps for some integer n ≥ 1 (at least one extra full loop around the cycle) - Fast moves twice as fast, so:
2(a + b) = a + b + nL - Subtract
a + bfrom both sides:a + b = nL - Rearrange:
a = nL - b
That last line is everything. Commit it to memory. Tattoo it somewhere if you have to.
After Phase 1, we reset one pointer to head. Both pointers now advance one step at a time. After a steps:
- The reset pointer has walked
asteps from head. It is exactly at the cycle entry. - The meeting-point pointer has walked
a = nL - bsteps from the meeting point. It startedbsteps past the cycle entry, so it is nowb + (nL - b) = nLsteps from the cycle entry: exactly n complete laps, landing back at the cycle entry.
Both pointers arrive at the cycle entry after exactly a steps. That is where they meet. That is the answer.

ptr walks a steps from the left. slow walks nL−b = a steps around the cycle. Same destination, same arrival time.
For n = 1 this simplifies: a = L - b = c. The tail length equals the forward distance from the meeting point to the cycle entry going around the long way. Two different paths, same length, same destination.
For n = 2, the meeting-point pointer makes one extra full lap before arriving. It does not matter. It still lands on the cycle entry at exactly the same moment as the reset pointer.
Walking Through an Example
Take this list, where node 6 connects back to node 3:
1 -> 2 -> 3 -> 4 -> 5 -> 6
^ |
|______________|
- a = 2 (nodes 1, 2 before the cycle entry at node 3)
- L = 4 (nodes 3, 4, 5, 6)
- b + c = 4
Phase 1 trace:
| Step | Slow | Fast |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 2 | 3 |
| 2 | 3 | 5 |
| 3 | 4 | 3 |
| 4 | 5 | 5 |
They meet at node 5. So b = 2 (entry at 3, then 4, then 5), c = 2 (5 → 6 → 3).
Check: a = nL - b = 1(4) - 2 = 2. The tail is 2 nodes. ✓
Phase 2 trace:
Reset ptr to node 1, keep slow at node 5. Advance one step each:
| Step | ptr | slow |
|---|---|---|
| 0 | 1 | 5 |
| 1 | 2 | 6 |
| 2 | 3 | 3 |
They meet at node 3. The cycle entry. After exactly a = 2 steps. ✓
Edge Cases That Will Bite You
Cycle starts at head (a = 0). The equation gives b = nL, meaning the meeting point is the cycle entry. In Phase 2, both pointers start at the same node. They agree before taking a step. Return head.
Single-node self-loop. The node's next points to itself. Both pointers initialize at head. After one step: slow = head.next = head, fast = head.next.next = head. They meet. Phase 2: ptr = head, slow = head, the while condition is false immediately. Return head. This is why initializing both pointers to head (not head.next) matters.
No cycle. Fast reaches null in Phase 1. Return null without running Phase 2. No drama.
Comparing by value instead of identity. If two separate nodes hold the same .val, a value comparison produces a false positive. Phase 2's meeting condition must compare node references (object identity), not values. This is the most common bug in interview implementations. Nothing is more demoralizing than watching your solution pass 61 out of 62 test cases.
One Structure, Every Language
Each implementation below takes the head of a singly linked list (which may or may not contain a cycle) and returns the node where the cycle begins, or null if there is no cycle. Identity comparison is used throughout.
from __future__ import annotations from typing import Optional class ListNode: def __init__(self, val: int = 0, next: Optional['ListNode'] = None): self.val = val self.next = next def detect_cycle(head: Optional[ListNode]) -> Optional[ListNode]: slow = fast = head while fast and fast.next: slow = slow.next fast = fast.next.next if slow is fast: # identity, not equality ptr = head while ptr is not slow: ptr = ptr.next slow = slow.next return ptr return None
Where Floyd Phase 2 Shows Up
Finding the entry node of a loop in a linked list. The canonical form. Any time a linked structure might have a back edge and you need the node that back edge leads to, Phase 2 is the tool.
Finding a duplicate value under strict constraints. LeetCode 287 looks nothing like a linked list problem. That is the point. The constraints: n+1 integers each in [1, n], one value appears more than once, no extra space, do not modify the array. The trick is treating index i as a node and nums[i] as its "next" pointer. The duplicate creates a cycle, and the cycle entry is the duplicate value. Floyd Phase 2 extracts it in O(n) time and O(1) space.
Re-entry in a functional sequence. Any deterministic function f where repeated application might loop (the digit-square sequence in the "Happy Number" problem, hash chain collisions, pseudo-random generators) can be modeled as a linked structure. Phase 2 finds the first element repeated in the sequence.
How to Spot a Phase 2 Problem
You need Floyd Phase 2 when:
- A sequence exists where each element deterministically maps to the next (linked list, array-as-graph, mathematical iteration)
- The sequence might loop
- You need the entry point of the loop, not just confirmation that one exists
- O(1) extra space is required (if O(n) is fine, a set is simpler)
Signal 1: "return the node where the cycle begins." This is LeetCode 142 word-for-word. Run Phase 1, then Phase 2. The implementation above is the complete solution.
Signal 2: "find the repeated value, O(1) space, do not modify the array." When the array's values are bounded indices into itself, the values form a functional graph. The bounded range guarantees a cycle exists. The repeat constraint guarantees the cycle has exactly one entry point. Floyd Phase 2 finds it.
Worked Example: LeetCode 142 (Linked List Cycle II)
Problem: Given the head of a linked list that may contain a cycle, return the node where the cycle begins. Return null if there is no cycle.
Why this structure fits: Phase 1 confirms a cycle and pins down a meeting point satisfying a = nL - b. That is exactly the property Phase 2 exploits. No other constant-space algorithm achieves this.
Solution: detectCycle as implemented above. Return the node object, not its value. Identity comparison in Phase 2 is mandatory.
Input: 3 -> 2 -> 0 -> -4
^ |
|_________|
Output: node with val = 2
- a = 1 (node 3 before cycle entry at node 2)
- L = 3 (cycle: 2, 0, -4)
Phase 1 trace:
| Step | Slow | Fast |
|---|---|---|
| 0 | 3 | 3 |
| 1 | 2 | 0 |
| 2 | 0 | 2 |
| 3 | -4 | -4 |
Meeting point is node -4. b = 2 (entry at 2, then 0, then -4), c = 1 (-4 back to 2).
Check: a = nL - b = 1(3) - 2 = 1. ✓
Phase 2 trace (ptr at node 3, slow at node -4):
| Step | ptr | slow |
|---|---|---|
| 0 | 3 | -4 |
| 1 | 2 | 2 |
They meet at node 2. The cycle entry. ✓
Worked Example: LeetCode 287 (Find the Duplicate Number)
Problem: Array nums of n+1 integers where each element is in [1, n]. Exactly one value repeats. Find it without modifying the array and using O(1) extra space.
Why this structure fits: Map index i to nums[i]. Index 0 is the head (nums[0] is always in [1, n], so it always points into the valid range). The duplicate value d appears at two indices i and j, meaning both nums[i] = d and nums[j] = d: two nodes both have "next" pointing to index d. Index d is the cycle entry. The duplicate value equals the cycle start index.
def find_duplicate(nums: list[int]) -> int: # Phase 1: detect meeting point slow = fast = 0 while True: slow = nums[slow] fast = nums[nums[fast]] if slow == fast: break # Phase 2: find cycle entry (the duplicate) slow = 0 while slow != fast: slow = nums[slow] fast = nums[fast] return slow
Note: We compare integer indices here, not object references. == is correct. There are no separate node objects; positions in the array are our "nodes."
nums = [3, 1, 3, 4, 2]
Graph: 0->3, 1->1, 2->3, 3->4, 4->2
Path from 0: 0 -> 3 -> 4 -> 2 -> 3 -> 4 -> 2 -> ...
Cycle: 3 -> 4 -> 2 -> 3 (entry at index 3)
Duplicate: 3 ✓
![Functional graph for nums=[3,1,3,4,2]. Index 0 maps to 3, index 2 maps to 3 (two arrows into index 3), creating a cycle 3→4→2→3. Index 3 is the cycle entry and the duplicate value.](https://assets.spacecomplexity.ai/blog/content-images/floyd-cycle-detection-find-cycle-start/1779659279607-diagram-lc287.png)
Two nodes pointing to index 3 is exactly what creates the cycle. The cycle entry IS the duplicate.
The Six Things to Remember
- Phase 1 places slow and fast at a meeting point inside the cycle. Phase 2 locates the cycle entry.
- The core identity:
a + b = nL, soa = nL - b. The tail length equals the forward distance from the meeting point to the cycle entry, padded by (n-1) extra full laps. - Reset one pointer to head, advance both one step. They meet at the cycle entry after exactly
asteps. - Use identity comparison (
is,===, pointer==,ReferenceEquals,equal?), not value comparison. Wrong comparison gives wrong answers whenever distinct nodes share a value. - Initialize both pointers to
head, nothead.next. This handles a = 0 (cycle at head) and single-node self-loops. - LeetCode 142 is the canonical linked list form. LeetCode 287 is the same algorithm disguised as an array problem.
If you want to practice walking through a proof like this out loud under interview pressure, SpaceComplexity runs voice-based mock interviews where you explain the reasoning, not just write the code. The rubric checks whether you can articulate the a = nL - b argument, not just paste a working solution.
For more on two-pointer traversal patterns, see how the sliding window algorithm collapses nested loops into a single pass. If the constraint-satisfaction flavor of LeetCode 287 catches your interest, the dynamic programming framework covers the complementary class of problems where subproblem results can be cached.