The Greedy Choice Property: One Test Separates Greedy from DP
- Greedy choice property holds when locally optimal choices always lead to the global optimum, with no backtracking needed.
- Both greedy and DP require optimal substructure, but only greedy additionally needs the greedy choice property.
- The exchange argument is the proof: swap the greedy choice into any optimal solution; if the result is never worse, greedy is correct.
- Weighted interval scheduling breaks greedy (exchange argument fails once weights are added), while unweighted activity selection does not.
- 0/1 knapsack requires DP with reverse iteration (high-to-low capacity) to prevent an item being reused within one pass.
- Dijkstra is greedy: non-negative weights guarantee finalized vertices can't improve; one negative edge breaks the invariant.
- Decision protocol: confirm optimal substructure, spend two minutes on the exchange argument, then fall back to DP state design.
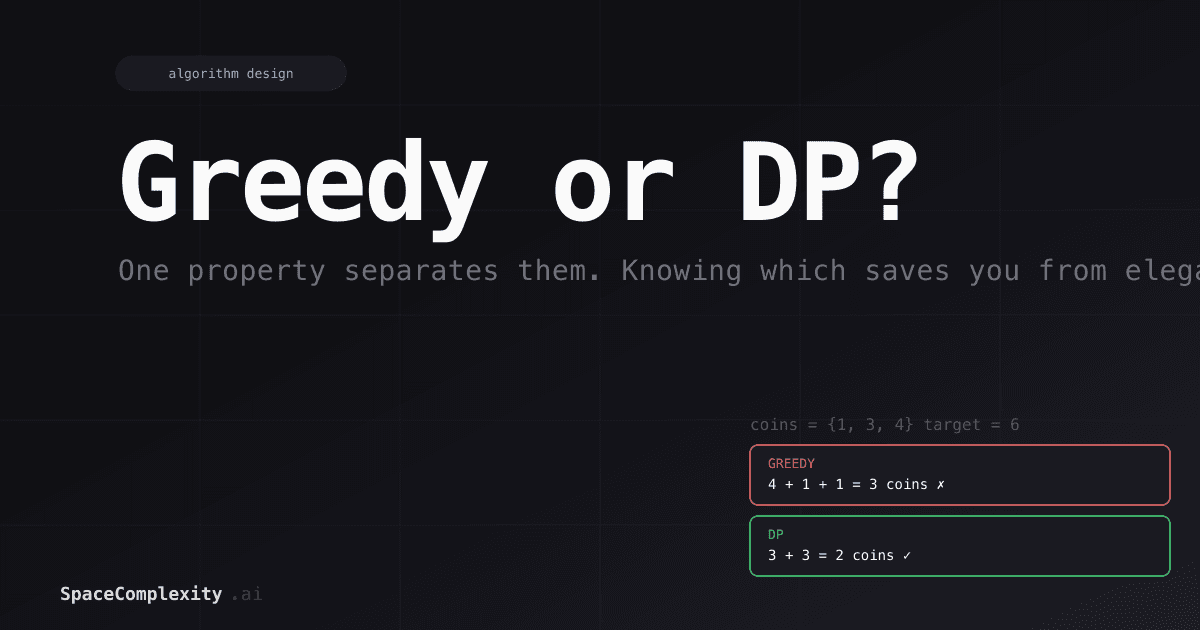
You have coins worth 1, 3, and 4. You owe 6 cents. The greedy approach grabs the biggest coin that fits. You take 4, then 1, then 1. Three coins. Reasonable. Very confident. Wrong.
Dynamic programming tries everything. It finds [3, 3]. Two coins.
Greedy committed to 4 like someone who sees a parking spot and takes it without reading the sign. DP drove around the entire block, checked every option, and found a legal spot. The real question isn't which algorithm is faster. The question is which one is allowed to produce the correct answer. That comes down to a single property called the greedy choice property, and knowing it before you code saves you from shipping thirty lines of confident, elegant, provably wrong algorithm.
They Both Need the Same Foundation
Before the split, both approaches share one requirement: optimal substructure.
A problem has optimal substructure when an optimal solution to the whole contains optimal solutions to each of its subproblems. The proof is a cut-and-paste argument. Suppose your solution uses a non-optimal answer for some subproblem. Cut it out and paste in the true optimal for that subproblem. The result is better or equally good. Contradiction. So every piece of an optimal solution must itself be optimal.
Both greedy and DP rely on this. The divergence is what happens next.
The Greedy Choice Property Is the Dividing Line
DP is the default when you only have optimal substructure. It solves every subproblem, stores the results, and combines them. The call graph becomes a DAG, not an exponential tree. It doesn't commit to anything early. Every decision gets revisited until you know the global answer. It's pathologically indecisive. That's the whole point.
Greedy adds one more requirement: the greedy choice property. This holds when a globally optimal solution can always be found by making locally optimal choices, with no backtracking needed.
If the greedy choice property holds, you don't need a table. Pick the locally best option, recurse on what remains, done. If it doesn't hold, committing to the local best can paint you into a corner, exactly as the 4-cent coin did above.
The formal way to verify the greedy choice property is the exchange argument.
How You Prove Greedy Won't Betray You
The exchange argument is the proof technique: show you can swap any other choice for the greedy choice without making things worse.
The recipe:
- Let O be any optimal solution and G be the greedy solution. They differ somewhere.
- Find the first position where they differ.
- Swap O's choice at that position for G's choice.
- Show the result is no worse than O.
If swapping the greedy choice in never hurts, you can transform any optimal solution into the greedy solution without losing quality. That means G is optimal.
Activity selection is the canonical demonstration. You have n jobs with start and end times. No weights. Maximize the count of non-overlapping jobs.
The greedy choice: always pick the job that finishes earliest.
Proof: let O be any optimal solution, sorted by finish time. Let o1 be O's first job and g1 be greedy's first job (earliest overall finish time). Since g1 has the globally earliest finish time, f(g1) ≤ f(o1). Replace o1 with g1 in O, getting O'. O' has the same number of jobs. Is it valid? Every job after o1 in O starts at or after f(o1). Since f(g1) ≤ f(o1), g1 is compatible with all of them. O' is feasible and optimal. Greedy's first pick is always safe.
Apply the argument recursively to the remaining jobs. Greedy is correct.

Swap g1 in for o1. It finishes no later, so everything after o1 is still compatible. The freed gap [3,5] is a bonus.
Adding One Number Breaks Everything
Now add a weight to each job and maximize total weight instead of job count.
Three jobs:
- A: interval [0, 5], weight 100
- B: interval [0, 2], weight 1
- C: interval [3, 5], weight 1
Greedy by earliest end time picks B first (ends at 2), then C (compatible, ends at 5). Total weight: 2.
The optimal is A alone. Weight: 100.
The exchange argument fails here. Swap A in for B and you lose C's compatibility. There is no consistent local choice that leads to the global best. One weight field. One hundred units of regret.
When a problem has optimal substructure but no greedy choice property, DP is the correct tool. Weighted interval scheduling runs in O(n log n) by sorting jobs, computing p(j) (the latest compatible predecessor for each job j using binary search), and filling a DP table:
# jobs sorted by finish time # p[j] = index of last job compatible with job j def weighted_interval_scheduling(jobs): n = len(jobs) jobs.sort(key=lambda x: x[1]) # sort by end time p = compute_predecessors(jobs) # binary search, O(n log n) dp = [0] * (n + 1) for j in range(1, n + 1): include = jobs[j-1][2] + dp[p[j]] # weight + best without conflicts exclude = dp[j-1] dp[j] = max(include, exclude) return dp[n]
The key is dp[p[j]]: the table carries the memory of every past decision, so choosing to include job j doesn't blindly discard the value of incompatible predecessors. Greedy has no such memory.
![Weighted interval scheduling diagram: three job bars A=[0,5] weight=100, B=[0,2] weight=1, C=[3,5] weight=1. Greedy picks B+C for total weight 2. Optimal picks A alone for weight 100.](https://assets.spacecomplexity.ai/blog/content-images/greedy-choice-property/1780000011937-weighted-interval-failure.png)
The earliest-finish heuristic picks B and C for a combined weight of 2. A alone is worth 100. Greedy left 98 on the table.
Knapsack: The Controlled Experiment
The knapsack problem offers a clean laboratory. Same items, one rule change, completely different algorithm.
Fractional knapsack: you can take any fraction of an item. Sort by value-per-weight and take as much of each item as fits. Greedy is provably optimal. The exchange argument holds: any solution not taking the highest-ratio item first can be improved by a fractional swap. You can always replace a sliver of a lower-ratio item with the same weight of a higher-ratio item without violating any constraint.
0/1 knapsack: items are indivisible. Consider three items with capacity W = 50:
items = [ (10, 60), # (weight, value), ratio = 6.0 (20, 100), # ratio = 5.0 (30, 120), # ratio = 4.0 ] capacity = 50
Greedy by ratio: take item 1 (ratio 6.0, weight 10), take item 2 (ratio 5.0, weight 20). Total weight 30. Item 3 needs 30 more but we only have 20 left. Skip. Total value: 160.
DP checks all combinations. Items 2 and 3 together weigh exactly 50. Value: 220. That's the answer. Greedy was proud of its 160 and never looked back.
The greedy choice committed 10 units of capacity to item 1 and blocked the better combination. When items are indivisible, there is no fractional fix. The exchange argument fails because you cannot make an infinitesimal swap. The DP table is:
dp = [0] * (capacity + 1) for weight, value in items: for w in range(capacity, weight - 1, -1): # iterate high to low: 0/1 knapsack dp[w] = max(dp[w], dp[w - weight] + value) # dp[50] == 220
The reverse iteration (high to low) is not cosmetic. Iterating low to high would let you reuse the same item multiple times, turning it into unbounded knapsack. Getting this direction wrong is the single most common knapsack bug. It's subtle enough to pass code review.

dp[50] = 220 comes from including item 3 (weight 30) then item 2 (weight 20). The greedy pick of item 1 first made that combination impossible.
Why Greedy Fails on Coin Change
Back to the opening puzzle. Coins {1, 3, 4}, target 6.
DP computes dp[i] = minimum coins to reach amount i for every i from 0 to 6:
def coin_change(coins, amount): dp = [float('inf')] * (amount + 1) dp[0] = 0 for i in range(1, amount + 1): for c in coins: if c <= i: dp[i] = min(dp[i], dp[i - c] + 1) return dp[amount]
Filling the table:
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| dp[i] | 0 | 1 | 2 | 1 | 1 | 2 | 2 |
dp[3] = 1 (use coin 3). dp[6] = min(dp[5]+1, dp[3]+1, dp[2]+1) = min(3, 2, 3) = 2.
The answer is dp[3] + dp[3] = [3, 3].
Greedy never computed dp[3]. It committed to 4 immediately and was emotionally done with the problem. The greedy choice failed because 4 is not a "building block" for 6 in this denomination system. Whether a denomination set is "canonical" (greedy-safe) depends on a number-theoretic property you almost never know in advance. When coins are arbitrary, always use DP.
![Coin change DP array showing dp values 0,1,2,1,1,2,2 for amounts 0 through 6. Two arrows from dp[6] point back to dp[3], labeled +1 coin each, showing the optimal [3,3] path.](https://assets.spacecomplexity.ai/blog/content-images/greedy-choice-property/1780000012956-coin-change-dp.png)
dp[6]=2 via two uses of coin 3. Greedy picked 4 first and never saw this path.
What You Pay for Each Approach
Greedy is usually faster by a full dimension.
Activity selection: O(n log n) for sorting, O(n) scan. Weighted interval scheduling: O(n log n) but with DP overhead. Coin change DP: O(n * A) where A is the target amount. 0/1 knapsack DP: O(n * W).
DP trades memory and computation for the ability to revisit decisions greedy can't. Greedy trades those for speed, and the trade is only valid when the greedy choice property holds.
| Problem | Greedy? | DP needed? | Complexity |
|---|---|---|---|
| Activity selection (unweighted) | Yes | No | O(n log n) |
| Weighted interval scheduling | No | Yes | O(n log n) |
| Fractional knapsack | Yes | No | O(n log n) |
| 0/1 knapsack | No | Yes | O(n * W) |
| Coin change (US denominations) | Yes | No | O(n) |
| Coin change (arbitrary) | No | Yes | O(n * amount) |
| Huffman coding | Yes | No | O(n log n) |
| Shortest path, non-negative weights (Dijkstra) | Yes | No | O(E log V) |
| Shortest path, negative weights (Bellman-Ford) | No | Yes | O(V * E) |
Dijkstra is a greedy algorithm. It always expands the unvisited vertex with the smallest current distance. The greedy choice property holds because non-negative weights guarantee that once you finalize a vertex, no future path through unvisited vertices can improve it. Add one negative edge and that guarantee vanishes. Dijkstra gives wrong answers and you need Bellman-Ford's DP relaxation. One negative edge. Whole algorithm down.
Which One Do You Grab First
When you face an optimization problem, run this sequence.
Step 1: Confirm optimal substructure. Most selection, interval, and sequence problems have it. If you can't see how to express the answer in terms of subproblem answers, neither approach applies directly.
Step 2: Spend two minutes on the exchange argument for greedy. Name the greedy choice. Try to swap it into any other optimal solution. Is the result still feasible? Is it no worse? If yes, greedy is safe. If the swap breaks feasibility or costs value, stop. You just saved yourself a table.
Step 3: Fall back to DP. Identify the minimum state that fully determines the subproblem output. That state becomes your table dimensions. For interval scheduling that's the job index. For knapsack it's (item index, remaining capacity). For coin change it's the remaining amount.
Interval scheduling is the sharpest example in the subject. Same structure, same inputs, weights added, completely different algorithm required. Once you see that boundary, the rest of the taxonomy organizes itself.
For more on reading the signals before you code, the pattern recognition guide on greedy vs DP walks through five problem types you can classify in under a minute. For DP specifically, when to use dynamic programming covers the referential transparency test and the overlapping subproblem check in detail. And five problems where your first solution isn't optimal shows both approaches head to head on real interview problems.
If you want to practice explaining why an algorithm is correct under live interview conditions, SpaceComplexity runs voice-based mock interviews where the follow-up "why does greedy work here?" is a scored dimension on its own. Getting the answer right and being able to articulate the exchange argument are two different skills.
Recap
- Both greedy and DP require optimal substructure. An optimal solution must contain optimal subsolutions.
- Greedy additionally needs the greedy choice property: locally optimal choices always lead to the global optimum.
- Verify with the exchange argument. Swap the greedy choice into any optimal solution. If it never makes things worse, greedy is correct.
- Activity selection (unweighted): greedy works. Add weights and the exchange argument breaks.
- Fractional knapsack: greedy works. Make items indivisible (0/1) and DP is required.
- Coin change on arbitrary denominations: greedy fails silently. DP always finds the optimum.
- Dijkstra is greedy and correct with non-negative weights. One negative edge breaks the invariant.
- Greedy is typically O(n log n). DP pays a polynomial cost proportional to the state space.
- Protocol: confirm optimal substructure, attempt exchange argument, fall back to DP state design.