Heap Sort: Build-Heap Is O(n). Every Other Step Is O(n log n).
- Build-heap runs in O(n) because most nodes are leaves doing zero work; the height-sum proof converges to 2n via the geometric series.
- Sift-down, not sift-up is the key to O(n) construction: sift-down on n/2 nodes costs far less than sift-up on all n.
- Heap sort is Θ(n log n) in every case (best, average, worst) with no adaptive behavior for sorted or nearly-sorted input.
- O(1) auxiliary space makes it unique among comparison sorts; the heap is built directly inside the input array.
- Introsort uses heap sort as a fallback: C++
std::sortswitches to heap sort when quicksort recursion depth exceeds 2×log₂(n). - Top-k extraction costs O(n + k log n): build once, extract k times, which beats a full sort when k is small.
- Cache misses make it 5-8x slower than quicksort in practice despite identical asymptotic complexity.
If you've ever said "heap sort is O(n log n)" in an interview and felt proud, great. You're right. You're also missing the interesting part.
The build step is O(n). The extraction step is O(n log n). Same algorithm, two completely different complexities, and most engineers mash them together into one vague "O(n log n)" and move on. Floyd figured this out in 1964. We've had six decades to absorb it. Still catches people off guard.
The short version: convert your array into a max-heap in O(n) using Floyd's bottom-up algorithm, then extract the maximum n-1 times in O(n log n). The sort is in-place with O(1) auxiliary space and guaranteed O(n log n) in every case, including worst case. That last property is why it exists. Quicksort degrades to O(n²) on bad pivots. Merge sort needs O(n) extra memory. Heap sort does neither, which is why every standard library's sort function falls back to it when things go sideways.
 A binary heap is just an array in a tree costume. No pointers. No malloc. Pure index arithmetic.
A binary heap is just an array in a tree costume. No pointers. No malloc. Pure index arithmetic.
The Binary Heap Hiding in Your Array
Here is the trick: there is no tree. There is only an array.
A binary heap is a complete binary tree stored in a flat array. "Complete" means every level is full except possibly the last, which fills left to right. That guarantee keeps the tree balanced and gives it exactly floor(log₂ n) height.
No pointer structure is needed. For a zero-indexed array, parent and child positions follow simple arithmetic:
- Parent of node i:
floor((i - 1) / 2) - Left child of node i:
2i + 1 - Right child of node i:
2i + 2
A max-heap adds one rule: every node is at least as large as both its children. The root always holds the maximum element. This rule says nothing about the ordering of siblings. Node 3 can be smaller or larger than node 4 without violating any property. That sibling freedom is why heap sort is not stable: two equal elements may swap positions during extraction.
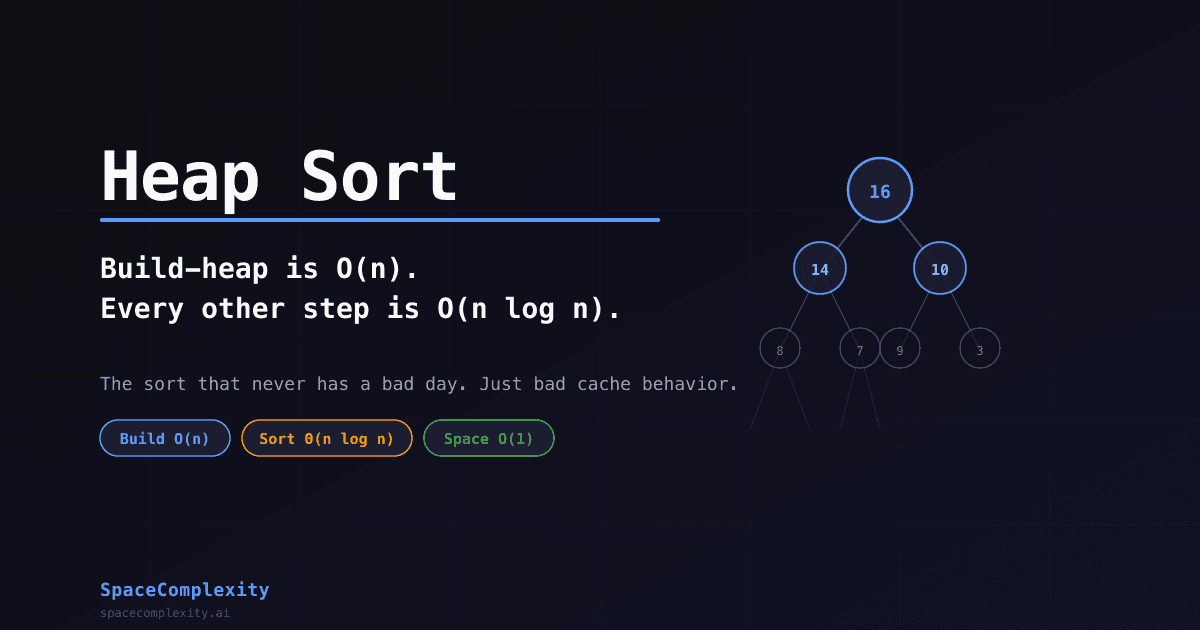
Array: [16, 14, 10, 8, 7, 9, 3]
Index: 0 1 2 3 4 5 6
16 (i=0)
/ \
14(i=1) 10(i=2)
/ \ / \
8(i=3) 7(i=4) 9(i=5) 3(i=6)
The last non-leaf is at index floor(n/2) - 1. For n=7 that's index 2. Indices floor(n/2) through n-1 are all leaves. Every leaf is trivially a valid max-heap of size one.
Sift-Down: The One Move That Runs Everything
Sift-down is the only algorithm you need to understand. Everything else in heap sort is just "call sift-down a bunch of times."
Sift-down (also called max-heapify) takes a single node that might violate the heap property and pushes it downward until the property is restored. The algorithm assumes both of the node's subtrees are already valid max-heaps. It runs in O(h) time where h is the height of the node, so O(log n) from the root.
Algorithm:
- Compare the node against its left and right children
- If the node is the largest, stop
- Swap with the larger child, then recurse from the new position
def sift_down(arr, heap_size, i): while True: largest = i left = 2 * i + 1 right = 2 * i + 2 if left < heap_size and arr[left] > arr[largest]: largest = left if right < heap_size and arr[right] > arr[largest]: largest = right if largest == i: break arr[i], arr[largest] = arr[largest], arr[i] i = largest
The iterative version above is preferable to a recursive one for large arrays. A heap of one billion elements has height ~30, so even a recursive sift-down won't blow the stack on any input. The iterative version eliminates call-frame overhead and makes the O(log n) depth limit obvious from reading the loop.
 Each swap moves the violating node one level down. It stops when it's the largest in its local trio. Three steps here; O(h) in general.
Each swap moves the violating node one level down. It stops when it's the largest in its local trio. Three steps here; O(h) in general.
Phase 1: Build-Heap Is O(n), Not O(n log n)
There are two ways to build a heap from an unsorted array. The naive approach inserts elements one at a time and sifts each one upward. That's O(n log n) total: you run sift-up on n elements, and elements near the top of the tree cost O(log n) each.
Floyd's 1964 bottom-up approach is O(n). The insight is to start from the last non-leaf and work backward to the root, calling sift-down on each node.
for i in range(n // 2 - 1, -1, -1): sift_down(arr, n, i)
This is the entire build-heap implementation. One loop, backward. No tree construction. No allocations. You look at it and think something must be missing. Nothing is missing.
Why is this correct? When you call sift-down on node i, its children need to already be valid max-heaps. Since you process nodes in reverse index order, any child of node i has a higher index and was already processed. By the time you reach node i, both subtrees are valid max-heaps. Sift-down then produces a valid max-heap rooted at i. Leaves are skipped entirely and are trivially valid max-heaps of size one.
7-node array: [3, 9, 7, 8, 14, 4, 16]
Last non-leaf: index 2
Processing order:
i=2 (value 7) → sift-down with children 4 and 16 → 16 rises
i=1 (value 9) → sift-down with children 8 and 14 → 14 rises
i=0 (value 3) → sift-down with children 14 and 16 → 16 rises, then 9 rises
Result: [16, 14, 7, 8, 9, 4, 3]
16
/ \
14 7
/ \ / \
8 9 4 3
Valid max-heap. Root is the maximum.
 Yellow nodes are being processed. Green nodes are already settled. Notice how each sift-down call only has to fix a small subtree because the bottom half was handled first.
Yellow nodes are being processed. Green nodes are already settled. Notice how each sift-down call only has to fix a small subtree because the bottom half was handled first.
The build-heap direction matters. Sift-down benefits from the fact that most nodes are near the bottom with small height. Sift-up goes the other way and pays full price: leaves at height log n each cost O(log n).
Why Build-Heap Is O(n): The Height Distribution Proof
A complete binary tree of n nodes has at most ceil(n / 2^(h+1)) nodes at height h.
Sift-down on a node at height h costs O(h). Total build-heap cost:
T(n) = sum over h from 0 to floor(log n) of:
ceil(n / 2^(h+1)) * O(h)
= O(n) * sum over h from 0 to ∞ of:
h / 2^h
The sum Σ h/2^h for h from 0 to infinity is a standard result. Start from the geometric series Σ x^h = 1/(1-x) for |x| < 1. Differentiate both sides with respect to x: Σ h*x^(h-1) = 1/(1-x)^2. Multiply by x: Σ h*x^h = x/(1-x)^2. Substitute x = 1/2:
Σ h/2^h = (1/2) / (1 - 1/2)^2 = (1/2) / (1/4) = 2
So T(n) = O(n * 2) = O(n).
The geometric series converges to 2 because the tree has exponentially many nodes near the bottom doing almost no work, and exponentially few nodes near the top doing O(log n) work each.
Visualized for a 15-node heap:
Height 3 (root): 1 node × O(3) work → 3 operations
Height 2: 2 nodes × O(2) work → 4 operations
Height 1: 4 nodes × O(1) work → 4 operations
Height 0 (leaves): 8 nodes × O(0) work → 0 operations
Total: 11 operations = O(n) for n=15
Compare to the sift-up approach, where those 8 leaves each cost O(3) work: 8 × 3 = 24 operations just from the leaves, already more than the full sift-down cost. The bottom of the tree is where the nodes live. Sift-down lets them do almost nothing. Sift-up charges them the full rate.
Phase 2: Extraction Builds the Sorted Suffix
Once the heap is built, the maximum sits at index 0. To sort the array in ascending order:
- Swap index 0 (maximum) with the last element in the heap
- Shrink the heap by one (the maximum is now in its final position)
- Restore the heap property by calling sift-down on index 0
Repeat n-1 times. The sorted array grows from the right.
for i in range(n - 1, 0, -1): arr[0], arr[i] = arr[i], arr[0] # move max to final position sift_down(arr, i, 0) # i is the new heap size
Each sift-down costs O(log i) where i is the current heap size. Summing:
log(n-1) + log(n-2) + ... + log(1) = log((n-1)!) ≈ n log n [by Stirling]
More precisely, this is Θ(n log n).
 Swap the root to the end, shrink the heap, sift-down the new root. Repeat n-1 times. The sorted portion (green) grows rightward with every extraction.
Swap the root to the end, shrink the heap, sift-down the new root. Repeat n-1 times. The sorted portion (green) grows rightward with every extraction.
The invariant holds at each step: after k extractions, the k largest elements occupy the last k positions in sorted order, and the remaining elements form a valid max-heap.
Heap Sort Time Complexity at a Glance
| Operation | Time | Space | Notes |
|---|---|---|---|
| Sift-down | O(log n) | O(1) | O(h) where h = node height |
| Build-heap | O(n) | O(1) | Floyd's bottom-up, tighter than O(n log n) |
| Extraction | O(n log n) | O(1) | n-1 sift-downs, summed via Stirling |
| Heap sort | Θ(n log n) | O(1) | Best, average, and worst case identical |
| Best case | Θ(n log n) | O(1) | No adaptive behavior for sorted input |
| Worst case | Θ(n log n) | O(1) | Unlike quicksort's O(n²) on bad pivots |
Every input case produces the same Θ(n log n) running time. Heap sort is not adaptive. A sorted array, a reverse-sorted array, and a random array all take the same number of comparisons. There is no early-exit path and no benefit from pre-existing order.
The O(1) auxiliary space is genuine. The heap is built directly inside the input array. No copy is made, no auxiliary array is allocated.
The Cache Miss Problem Quicksort Avoids
Heap sort is the sorting algorithm with the infuriating property of being theoretically superior and practically slower. Same Big-O. Five to eight times slower on large inputs. The culprit is cache behavior.
Quicksort partitions around pivots and recursively sorts contiguous subarrays. Memory accesses are sequential within each partition. The hardware prefetcher detects the sequential stride and pre-loads cache lines before the CPU needs them. Most accesses hit L1 or L2 cache, which costs 2-10 nanoseconds per access.
Heap sort jumps around. Sift-down on a node at index i reads indices 2i+1 and 2i+2. Starting from the root at index 0, the access sequence is 0, 1 or 2, then 3-5, then 7-11, then 15-23. For a heap of one million elements, those indices are hundreds of kilobytes apart. The prefetcher can't predict these jumps. Each access misses the cache and hits DRAM at 80-100 nanoseconds. That's a 40-50x latency penalty per access.
On large inputs, heap sort makes roughly n log n DRAM fetches. Quicksort makes n log n cache-warm reads. Same asymptotic count, wildly different latency per access.
 Quicksort's prefetcher is happy. Heap sort's prefetcher gave up. At n=1M, sift-down jumps are megabytes apart.
Quicksort's prefetcher is happy. Heap sort's prefetcher gave up. At n=1M, sift-down jumps are megabytes apart.
This is why C++ std::sort uses introsort: it runs quicksort by default, and switches to heap sort only when the recursion depth exceeds 2 × floor(log₂ n). At that point quicksort has degraded to nearly O(n²) behavior, and heap sort's guaranteed O(n log n) is worth the cache cost. You call heap sort every time std::sort triggers this fallback on an adversarial input. You just never know it's happening.
For the cache miss mechanics in depth, see Array vs Linked List Performance: Same Big-O, Completely Different Speed.
 @tenderlove in 2019, accidentally describing heap sort's entire value proposition.
@tenderlove in 2019, accidentally describing heap sort's entire value proposition.
One Structure, Every Language
Every implementation below uses iterative sift-down to eliminate call-stack overhead on large inputs. The logic is identical across all languages: one build loop going backward from n/2 - 1 to 0, then one extraction loop going backward from n-1 to 1.
def heap_sort(arr: list) -> list: n = len(arr) def sift_down(heap_size: int, i: int) -> None: while True: largest = i left = 2 * i + 1 right = 2 * i + 2 if left < heap_size and arr[left] > arr[largest]: largest = left if right < heap_size and arr[right] > arr[largest]: largest = right if largest == i: break arr[i], arr[largest] = arr[largest], arr[i] i = largest for i in range(n // 2 - 1, -1, -1): sift_down(n, i) for i in range(n - 1, 0, -1): arr[0], arr[i] = arr[i], arr[0] sift_down(i, 0) return arr
What Problems Heap Sort Solves
Guaranteed worst-case O(n log n) with O(1) space. This is the specific combination no other common sort provides. Quicksort needs O(n) space in the worst case for the call stack and can degrade to O(n²). Merge sort is O(n log n) in all cases but needs O(n) auxiliary space. Heap sort gives you both properties simultaneously.
The introsort safety net. GCC's libstdc++ and LLVM's libc++ both implement std::sort as introsort. Quicksort runs until the recursion depth exceeds 2 × floor(log₂ n), then heap sort takes over. Any C++ developer calling std::sort on adversarial input (sorted arrays, many duplicates, carefully crafted permutations) silently benefits from heap sort's worst-case guarantee.
Top-k extraction. If you need the k largest elements from n unsorted values, build the heap in O(n), then extract k times in O(k log n). Total cost: O(n + k log n). For small k this beats a full O(n log n) sort. For k = n you've just run heap sort. For k = 1 you've just found the maximum in O(n), the same as a linear scan.
Real-time and embedded systems. Systems with hard latency deadlines can't risk quicksort's O(n²) worst case. Heap sort delivers predictable O(n log n) regardless of input. Combined with O(1) extra memory, it fits in environments where both time and space are constrained.
Recognizing the Pattern
Heap sort is the right tool when three signals appear together: you need a sort, the worst-case complexity matters (not just average), and you cannot allocate extra memory proportional to input size.
The stronger signal is often the heap itself, not the full sort. For the k largest elements, a sliding minimum, or merging k sorted streams, use a heap directly. The Heap Data Structure: A Complete Binary Tree Hiding in an Array covers that family of problems.
Signal 1: The problem requires in-place sorting with no auxiliary allocation. malloc is unavailable or forbidden. Merge sort is out.
Signal 2: Input can be adversarial or pathological. You cannot accept O(n²) worst case. Quicksort alone is out.
Signal 3: You need the k largest or smallest elements without sorting the full array.
Worked Example 1: Sort Without Heap or Recursion Budget
Problem: sort an array of 10 million integers. You are inside a kernel module where heap allocation is prohibited and the stack is limited to 64 KB. Standard quicksort uses O(log n) stack frames, about 240 frames for 10 million elements, each potentially holding 100+ bytes of locals. That's 24 KB for the stack alone, pushing limits. A pathological input could push recursion to O(n) depth, triggering a stack overflow.
Why heap sort fits: the iterative sift-down above uses O(1) stack space. No recursion, no auxiliary array. The build-heap and extraction loops are flat. You can sort 10 million integers with a fixed stack footprint of a few hundred bytes.
Worked Example 2: Finding the k-th Largest Element (LeetCode 215)
Problem: given an unsorted array of n integers, find the k-th largest in O(n log n) time.
Naive approach: sort the array fully in O(n log n), return index n-k.
Heap sort insight: you don't need to finish the sort. Build the max-heap in O(n). Extract the maximum k times, each costing O(log n). The last value extracted is the k-th largest. Total: O(n + k log n).
For k much smaller than n, this beats a full sort. At one extreme, k = 1 is just build-heap plus one extraction: O(n), the same as a linear scan. At the other, k = n means you've run the full sort: O(n log n).
def find_kth_largest(nums: list, k: int) -> int: n = len(nums) def sift_down(heap_size: int, i: int) -> None: while True: largest = i left = 2 * i + 1 right = 2 * i + 2 if left < heap_size and nums[left] > nums[largest]: largest = left if right < heap_size and nums[right] > nums[largest]: largest = right if largest == i: break nums[i], nums[largest] = nums[largest], nums[i] i = largest for i in range(n // 2 - 1, -1, -1): sift_down(n, i) for i in range(n - 1, n - k - 1, -1): nums[0], nums[i] = nums[i], nums[0] sift_down(i, 0) return nums[n - k]
Build heap, extract k times, return. The k-th largest ended up at index n-k after k swaps.
Quick Recap
- Heap sort has two distinct phases: build-heap in O(n) and extraction in O(n log n)
- Build-heap is O(n) because most nodes are near the leaves and do almost no work; the height-sum proof converges to 2n via geometric series
- The sift-up approach (top-down insertion) would make build-heap O(n log n), not O(n); always use sift-down from the last non-leaf
- Every case (best, average, worst) is Θ(n log n); heap sort is not adaptive
- Auxiliary space is O(1); the sort happens inside the input array
- Heap sort is not stable; equal elements may swap during extraction
- In practice, heap sort is 5-8x slower than quicksort on large inputs because every sift-down step produces cache misses
- C++
std::sortuses heap sort as a fallback inside introsort when quicksort recursion depth exceeds 2 × log₂(n) - The build-heap + k extractions pattern runs in O(n + k log n), which beats a full sort when k is small
These concepts come up constantly in technical interviews, and explaining the build-heap proof out loud is harder than it looks on paper. SpaceComplexity runs voice-based mock interviews with rubric-based feedback on exactly this kind of complexity analysis. Practice narrating it. That's the version that gets you hired.
For the broader heap family and priority queue patterns, see The Heap Data Structure: A Complete Binary Tree Hiding in an Array. For the cache performance mechanics behind why identical Big-O produces very different wall-clock times, Array vs Linked List Performance: Same Big-O, Completely Different Speed has the full breakdown.
Further Reading
- Heapsort, Wikipedia, history, variants, and the bottom-up heapsort improvement
- Binary Heap, Wikipedia, the data structure underpinning both build-heap and the priority queue
- Heap Sort, GeeksforGeeks, worked examples and visualizations
- Introsort, Wikipedia, the hybrid algorithm where heapsort serves as the guaranteed worst-case fallback
- std::sort, cppreference, the C++ standard specification and its complexity guarantee, which heapsort makes possible