Interpolation Search Algorithm: O(log log n) When Your Data Plays Fair
- Interpolation search estimates the probe index from the key value instead of always picking the midpoint, achieving O(log log n) average vs O(log n) for binary search.
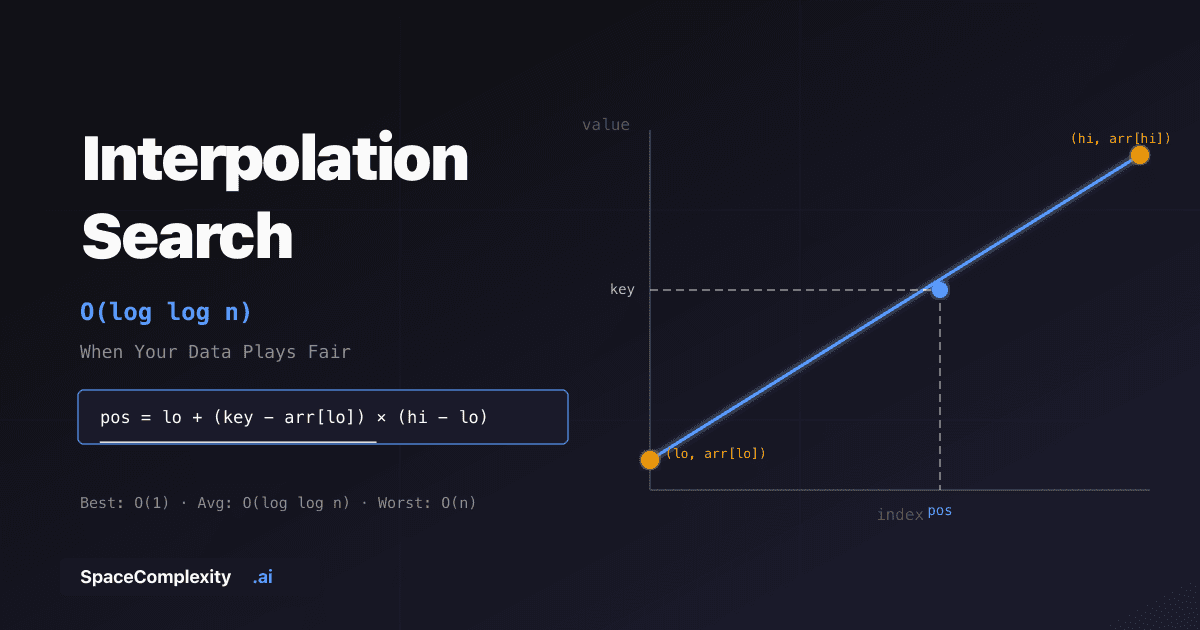
- The formula
pos = lo + (key - arr[lo]) * (hi - lo) / (arr[hi] - arr[lo])is a linear interpolation through the array endpoints—no clamping required when the loop guard holds. - Uniform distribution is the prerequisite: each probe reduces the search space from n to ~√n, producing doubly logarithmic convergence proved by Perl, Itai, and Avni (1978).
- Worst case O(n) occurs with exponentially distributed values where the formula underestimates position and advances one slot per probe.
- Integer overflow is the most common bug: cast the numerator to 64-bit before multiplying in Java, C, C++, C#, and Kotlin.
- Skip it when the distribution is non-uniform, unknown, or adversarially controlled; binary search's O(log n) guarantee is unconditional.
Open a dictionary to find "xylophone." You don't open to page 500. You flip near the end, because the value of the word tells you roughly where it lives. Binary search opens to page 500 every time. It ignores the key value completely and only cares about order. Very principled. Also kind of dense.
Interpolation search is the algorithm that does what your hands do. Given a sorted array with numerically valued keys, it estimates where the target sits using a linear formula, then narrows from there. Under a uniform distribution, it reaches the target in O(log log n) probes where binary search takes O(log n). For a million-element array, that is roughly 4 probes versus 20 for binary search.
Reach for interpolation search when your array is sorted, numerically keyed, and approximately uniformly distributed. Sequential customer IDs, evenly spaced sensor readings, Unix timestamps under steady traffic. When larger index reliably means proportionally larger value, the formula shines. When the distribution is skewed or unknown, binary search is the safer choice.
W. W. Peterson described the algorithm in 1957 in his IBM Journal paper "Addressing for Random-Access Storage." Yehoshua Perl, Alon Itai, and Haim Avni proved the O(log log n) average-case bound in their 1978 CACM paper.
 Both searches require a sorted array. Interpolation search also needs values that actually mean something numerically.
Both searches require a sorted array. Interpolation search also needs values that actually mean something numerically.
The Formula Is Just a Line
The algorithm assumes the array values grow approximately linearly with the index. If that holds, the value at any index lies on a straight line through two known points: (lo, arr[lo]) and (hi, arr[hi]).
 Fit a line through the two known endpoints. Read off the index where value equals the target. That's the probe.
Fit a line through the two known endpoints. Read off the index where value equals the target. That's the probe.
The line's equation: value = arr[lo] + slope * (index - lo) where slope = (arr[hi] - arr[lo]) / (hi - lo).
Invert it to find the index where value = key:
key = arr[lo] + slope * (pos - lo)
pos = lo + (key - arr[lo]) / slope
= lo + (key - arr[lo]) * (hi - lo) / (arr[hi] - arr[lo])
This formula is the entire algorithm. Compute pos, compare arr[pos] to key, shrink the window as you would in binary search. The only difference is where you probe.
The probe is always in [lo, hi]. The while condition enforces arr[lo] <= key <= arr[hi], so:
(key - arr[lo])is non-negative(hi - lo)is non-negative(arr[hi] - arr[lo])is positive (handled separately when zero)- The offset is in
[0, hi - lo], soposis in[lo, hi]
No clamping needed after the formula.
The one edge case: if arr[lo] == arr[hi], the denominator is zero. But the while condition implies key == arr[lo] in that case. Check for equal endpoints before dividing and return lo immediately.
One Probe on Perfectly Uniform Data
The best case is a single probe. Here it is, traced step by step.
index: 0 1 2 3 4 5 6 7 8 9
value: 10 20 30 40 50 60 70 80 90 100
Searching for 70. Bounds: lo=0, hi=9.
pos = 0 + (70 - 10) * (9 - 0) / (100 - 10)
= 0 + 60 * 9 / 90
= 0 + 6
= 6
arr[6] = 70 -- found in one probe
 Uniform data means the estimate is accurate enough to land near the target immediately. Binary search doesn't know or care.
Uniform data means the estimate is accurate enough to land near the target immediately. Binary search doesn't know or care.
Binary search on the same array needs four probes: midpoint 4 (value 50, go right), midpoint 7 (value 80, go left), midpoint 5 (value 60, go right), midpoint 6 (value 70, found). The formula hit exactly because the data is perfectly linear. Real data is not perfectly linear, but near-uniform data brings the first probe close enough that one or two more resolve the position.
When the Formula Lies
Now search for 9 in this array:
index: 0 1 2 3 4 5 6 7 8 9
value: 1 2 3 4 5 6 7 8 9 1,000,000,000
Probe 1:
pos = 0 + (9 - 1) * 8 / (1,000,000,000 - 1) = 0 + 0 = 0
arr[0] = 1 < 9 -> lo = 1
Probe 2:
pos = 1 + (9 - 2) * 7 / (1,000,000,000 - 2) = 1 + 0 = 1
arr[1] = 2 < 9 -> lo = 2
Probe 3: pos = 2 + 0 = 2 -> lo = 3
Probe 4: pos = 3 + 0 = 3 -> lo = 4
...
The massive outlier forces the formula to underestimate position on every probe, turning the search into a linear scan.
At that point you have reinvented sequential search, just with extra arithmetic on each step.
 The formula assumes linear growth between the endpoints. One exponential outlier invalidates that assumption permanently.
The formula assumes linear growth between the endpoints. One exponential outlier invalidates that assumption permanently.
This is the worst case. It appears with any exponentially distributed values: powers of 2, prices with extreme outliers, timestamps with one enormous gap at the end. The formula assumes linear growth. Exponential growth consistently fools it. Binary search is immune, since it ignores key values and always cuts in half.
Why O(log log n) Holds on Uniform Data
The average-case analysis is due to Perl, Itai, and Avni (1978). Their result rests on one key observation: under a uniform distribution, each probe reduces the expected search space from n elements to O(√n).
The intuition: with uniformly distributed keys, the formula's error is statistically bounded. The expected remaining search space after one good probe is proportional to the standard deviation of the uniform distribution over the remaining interval, which scales as √n. The 1978 paper bounds the probability that the probe falls more than √n positions from the true location and sums these error probabilities to show the expected total probes is O(log log n) with constant approximately 2.42.
Follow the geometric shrinkage:
| Probes | Expected search space |
|---|---|
| 0 | n |
| 1 | ~√n = n^(1/2) |
| 2 | ~n^(1/4) |
| k | ~n^(1/2^k) |
We stop when the space reaches 1: n^(1/2^k) ≈ 1, so 2^k ≈ log n, giving k ≈ log(log n).
 Each interpolation probe does more work than a binary probe. That compounds into a qualitative gap for large n.
Each interpolation probe does more work than a binary probe. That compounds into a qualitative gap for large n.
Contrast: binary search reduces to n/2 per probe, taking log₂(n) probes. Each doubling of the exponent in interpolation search is qualitatively faster than each halving of the count in binary search. That gap between log n and log log n is the algorithm's prize.
A practical note: the formula's arithmetic (one multiplication, one division) costs more per probe than binary search's (one comparison, one bit shift). For small arrays held entirely in cache, binary search often wins on wall time despite more probes. The log log n advantage pays off when n is large enough that the probe count, not the per-probe arithmetic, dominates. And it pays off most clearly when each probe incurs an expensive operation like a disk seek or a cache miss.
The Operations and Their Costs
| Operation | Best Case | Average Case | Worst Case | Space |
|---|---|---|---|---|
| Search | O(1) | O(log log n) | O(n) | O(1) |
Best case O(1): the formula places the first probe exactly on the target. Happens with perfectly uniform data.
Average case O(log log n): proved under the assumption that n keys are drawn from a uniform distribution. The expected probe count is bounded by approximately 2.42 · log log n.
Worst case O(n): exponentially distributed values cause one-step advancement per probe, degrading to linear search.
Space O(1): the algorithm uses a constant number of variables regardless of input. A recursive implementation would use O(log log n) stack space on average and O(n) in the worst case, with no algorithmic benefit. Write the iterative version. Nothing good lives down the recursive path here.
Interpolation search has no insert or delete. It is a read-only operation on a static sorted array. For dynamic data, reach for a balanced BST or a skip list.
One Structure, Every Language
The algorithm is identical across languages: a while loop with a bounds guard, the interpolation formula, three-way branching on the comparison. The one language-specific concern is integer overflow in the numerator (key - arr[lo]) * (hi - lo), which can overflow 32-bit arithmetic when key values span a large range and the array is large.
def interpolation_search(arr: list[int], key: int) -> int: lo, hi = 0, len(arr) - 1 while lo <= hi and arr[lo] <= key <= arr[hi]: if arr[lo] == arr[hi]: return lo pos = lo + (key - arr[lo]) * (hi - lo) // (arr[hi] - arr[lo]) if arr[pos] == key: return pos if arr[pos] < key: lo = pos + 1 else: hi = pos - 1 return -1
Python integers have arbitrary precision. No overflow possible. // gives floor division, which keeps pos in [lo, hi]. The chained comparison arr[lo] <= key <= arr[hi] is valid Python and requires no extra parentheses.
Where Interpolation Search Wins
Large uniformly distributed numeric datasets. Customer IDs assigned sequentially, prices in a narrow band, sensor readings at fixed intervals. Peterson designed the algorithm for exactly this scenario in 1957: random-access storage systems where the key distribution was known and approximately uniform.
Time-series log lookup. Log files indexed by Unix timestamp. If your service handles steady traffic, timestamps are approximately uniform over a time window, and retrieving entries for a specific second takes 4 to 5 probes where binary search would take 23 (for 10 million entries). If each probe is a disk read, that is 40ms versus 230ms at 10ms per seek.
Database index pages. Within a B-tree leaf node, integer primary keys are sorted and often approximately uniform when they are auto-incremented. Some storage engines use interpolation-style probing within a page to reduce comparisons per node traversal, especially for wide leaf pages.
Any read-heavy static dataset where probes are expensive. The advantage is clearest when each probe costs something significant: a disk seek, a cache miss from a cold L3, a remote key-value lookup. When probes are cheap (small array in L1 cache), binary search's simpler arithmetic often wins on wall time despite more comparisons.
How to Recognize the Pattern
Five signals suggest interpolation search over binary search:
- Numeric keys with meaningful distance. Not just orderable: integers, floats, timestamps, anything where
key - arr[lo]represents a real quantity. String keys, enums, and custom comparables do not apply. - Approximately uniform distribution. You know or can reasonably assume values spread evenly across the range. Uniform random draws, sequential IDs, fixed-rate sensor data.
- Large n. The O(log log n) advantage requires n in the thousands before it outpaces binary search's simpler arithmetic. For n under a few hundred, binary search is usually faster.
- Static or append-only data. Interpolation search offers no insert or delete. The array must remain sorted.
- Expensive probes. Disk I/O, network calls, or any inner loop where the number of comparisons (not the per-comparison arithmetic) is the bottleneck.
When to skip it: non-uniform or unknown distributions, string keys, small arrays, frequently modified data, or any context where an adversary controls the input (exponential-distribution attack degrades to O(n)).
Worked Example 1: Sequential Customer ID Lookup
You have a sorted array of 500,000 customer IDs assigned uniformly from 1 to 1,000,000. A query arrives for ID 725,000.
Binary search: log₂(500,000) ≈ 19 probes.
First interpolation probe:
pos = 0 + (725,000 - 1) * 499,999 / (1,000,000 - 1) ≈ 362,499
The first probe lands near index 362,499. ID 725,000 sits around index 362,500. One more probe resolves the exact slot. Expected total: 3 to 4 probes, versus 19 for binary search. This is the ideal case. Uniform distribution, large n, numeric keys, static dataset.
Worked Example 2: Steady-Traffic Log File
You have 10 million log lines stored in order by Unix timestamp. The application generates roughly uniform traffic (a monitoring daemon polling every 10ms). You want all entries for timestamp 1716825600.
The timestamps span a 100,000-second window over 10 million entries. Approximately 100 events per second, roughly uniform. Binary search: log₂(10,000,000) ≈ 23 probes. Interpolation search estimates the position directly from the timestamp value and converges in 4 to 5 probes.
What breaks this scenario: a batch job that fires 200,000 events at midnight creates a dense cluster. The timestamps around midnight are no longer uniform, and the formula overestimates how far to jump into that cluster on the first probe, adding extra iterations. Binary search's O(log n) guarantee is indifferent to clustering. Know your traffic pattern before choosing.
The Bugs That Bite
Overflow in the numerator. In Java, C, C++, C#, and Kotlin, (key - arr[lo]) * (hi - lo) uses 32-bit arithmetic by default. If key - arr[lo] is 2,000,000 and hi - lo is 100,000, the product is 2 * 10^11, well past INT_MAX (about 2.1 * 10^9). The result wraps silently, placing pos far outside [lo, hi] and causing an out-of-bounds access. Always cast the numerator to 64-bit before multiplying. Most developers write this bug once. Some write it twice.
Float truncation in JavaScript and PHP. Division of two integers returns a float in these languages. Math.floor in JS and intval() in PHP truncate toward zero. Using Math.round is wrong: it would round up when pos is between two integers, pushing the probe one slot past the correct position.
Division by zero on equal endpoints. If all remaining elements are the same value, arr[lo] == arr[hi]. The while condition arr[lo] <= key <= arr[hi] guarantees key == arr[lo] in that case. Return lo before dividing.
usize underflow in Rust. If you track hi as a usize and set hi = pos - 1 when pos = 0, you get usize::MAX, which is an out-of-bounds index. Use i64 for both indices, or guard with if pos > 0 { hi = pos - 1 } else { break }. The mathematical guarantee that pos >= lo + 1 when we enter the arr[pos] > key branch holds only after you've verified arr[lo] <= key in the loop guard -- easy to break if you restructure the code.
Assuming you need to clamp. You do not. When the while condition holds, pos is provably in [lo, hi]. Adding pos = max(lo, min(hi, pos)) is harmless but misleading: it implies the formula can produce an out-of-range value, which it cannot under the correct while condition.
Recap
- What it is: binary search with a linear-interpolation probe instead of a fixed midpoint.
- Formula:
pos = lo + (key - arr[lo]) * (hi - lo) / (arr[hi] - arr[lo]), derived by fitting a line through the endpoints and solving for the target's index. - Origin: Peterson 1957 (IBM Journal); average-case proof by Perl, Itai, Avni 1978 (CACM).
- Average O(log log n): each probe shrinks the search space to ~√n under uniform distribution; doubly logarithmic convergence follows.
- Worst O(n): exponentially distributed values cause one-step advancement per probe.
- Space O(1): iterative, constant extra variables.
- Critical guards: cast numerator to 64-bit before multiplying (Java, C, C++, C#, Kotlin); check
arr[lo] == arr[hi]before dividing; useMath.floororintval()for languages where division returns a float. - Use when: large array, numeric keys, approximately uniform distribution, read-heavy workload, expensive probes.
- Skip when: non-uniform or unknown distribution, string keys, small arrays, dynamic data, adversarial inputs.
If you want to practice explaining the O(log n) versus O(log log n) tradeoff out loud under interview pressure, SpaceComplexity runs voice-based mock interviews with rubric feedback. Knowing the formula is the easy part. Articulating when uniform distribution holds and when it doesn't is where most candidates stumble.
The invariants that make interpolation search correct are the same ones that underlie all sorted-array search. The binary search invariant is worth reading first if any of the boundary logic above felt shaky. And if off-by-one errors in search loops have caused trouble before, binary search off-by-one errors maps out exactly where they hide.