Kruskal's Algorithm: The Cheapest Edge That Doesn't Form a Cycle
- Kruskal's algorithm sorts all edges by weight and greedily adds each one that doesn't form a cycle, stopping at V-1 edges.
- Correctness follows from the cut property: the minimum-weight edge crossing any graph cut belongs to some minimum spanning tree.
- The Union-Find structure with path compression and union by rank reduces cycle detection to O(α(V)) amortized, making the main loop nearly linear.
- Total complexity is O(E log E) time and O(E+V) space, with the edge sort as the sole bottleneck.
- Use Kruskal's for sparse graphs with an explicit edge list; use Prim's for dense graphs or adjacency matrix inputs.
- Beyond MST, the same pattern covers single-linkage clustering, maximum-minimum-distance partitioning, and a 2-approximation for TSP on metric graphs.
You have a network of cities. You want to connect every city with cables. Cable is expensive (have you priced fiber lately?), so you want to minimize the total length. You do not care about routing, redundancy, or any other real-world engineering concern. You just need every city reachable from every other city.
This is the minimum spanning tree problem, and Kruskal's algorithm solves it with one of the most satisfying greedy strategies in computer science. Sort every edge by weight. Walk down the list. Take each edge if and only if it doesn't create a cycle. Stop when you have n-1 edges. Every edge you took belongs to a minimum spanning tree, and you can prove it.
Joseph Kruskal published this algorithm in 1956. It now shows up in roughly a dozen interview patterns, underpins single-linkage clustering, and runs inside image segmentation algorithms used in production today.
 Kruskal's is proof that sometimes the greedy approach is the correct approach.
Kruskal's is proof that sometimes the greedy approach is the correct approach.
The Setup: What Is a Minimum Spanning Tree?
A spanning tree of a connected undirected graph G = (V, E) is a subgraph that:
- includes all V vertices
- has exactly V-1 edges
- is acyclic (it is a tree)
A graph with V vertices and E edges has many possible spanning trees. The minimum spanning tree (MST) is the one where the sum of edge weights is smallest. If edge weights are all distinct, the MST is unique. When weights tie, multiple valid MSTs exist, and any of them is an acceptable answer. Interview problems usually guarantee distinct weights to avoid this ambiguity, so you can stop worrying about it.
An MST on V vertices always has exactly V-1 edges. Add one more edge and you get a cycle. Remove one more edge and you disconnect the graph.
The Algorithm Step by Step
Sort all edges by weight (ascending).
Initialize a Union-Find structure over all V vertices.
for each edge e = (u, v, weight) in sorted order:
if find(u) != find(v): # different components
add e to the MST
union(u, v) # merge components
if |MST| == V - 1:
break # done
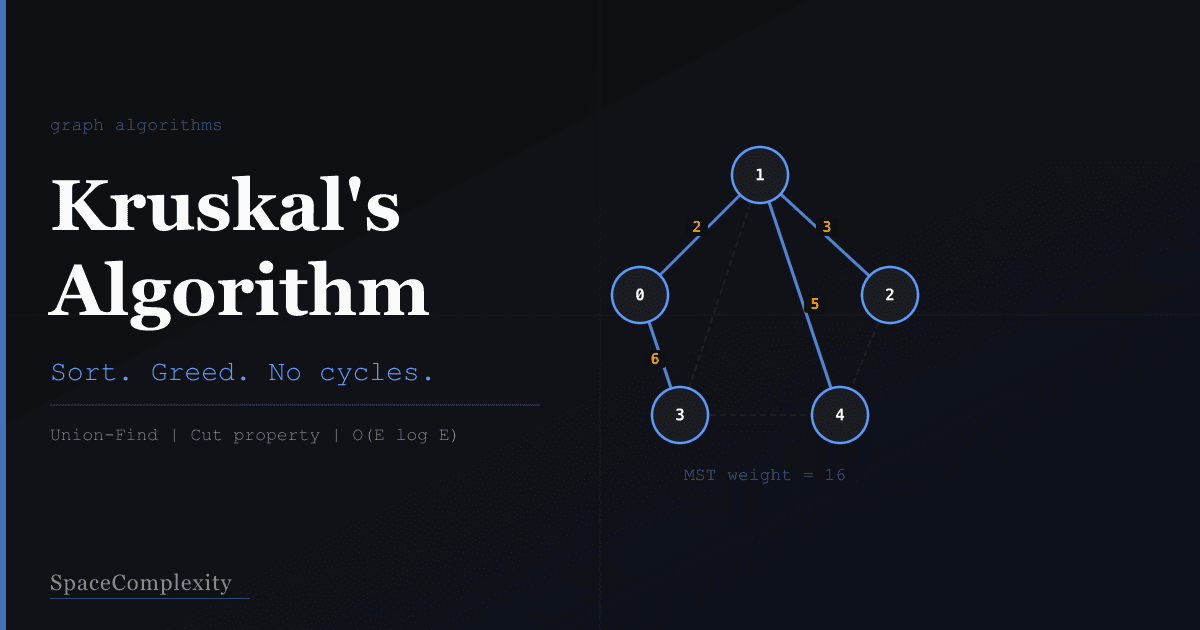
Walk through a concrete example. Five cities (0 through 4), seven possible cable routes:
Edge Weight
0 -- 1 2
1 -- 2 3
1 -- 4 5
0 -- 3 6
2 -- 4 7
1 -- 3 8
3 -- 4 9
 All 7 candidate edges, labeled by weight. Kruskal's will sort these and walk down the list.
All 7 candidate edges, labeled by weight. Kruskal's will sort these and walk down the list.
Sorted: (0-1, 2), (1-2, 3), (1-4, 5), (0-3, 6), (2-4, 7), (1-3, 8), (3-4, 9).
| Step | Edge | Action | Components |
|---|---|---|---|
| 1 | 0-1 (2) | Add | {0,1}, {2}, {3}, {4} |
| 2 | 1-2 (3) | Add | {0,1,2}, {3}, {4} |
| 3 | 1-4 (5) | Add | {0,1,2,4}, {3} |
| 4 | 0-3 (6) | Add | {0,1,2,3,4} |
| 5 | -- | Stop (4 edges = V-1) | -- |
MST weight: 2 + 3 + 5 + 6 = 16. Edges (2-4, 7), (1-3, 8), (3-4, 9) are never even tested. They sorted, they waited, they were never called.
 The four MST edges (solid) vs the three discarded edges (dashed). Adding any discarded edge would form a cycle.
The four MST edges (solid) vs the three discarded edges (dashed). Adding any discarded edge would form a cycle.
How It Works Internally
Two data structures do all the work.
The Edge List
Every edge is a triple: (weight, u, v). You collect all E edges into an array and sort by the first field. That sort is the dominant cost of the algorithm.
Memory layout: a contiguous array of structs, each typically 12 bytes on a 64-bit machine (4 bytes each for weight, u, v). Sorting is cache-friendly because elements are adjacent.
 Seven structs laid out contiguously in memory. The sort walks this array once: sequential access, cache-friendly, no pointer chasing.
Seven structs laid out contiguously in memory. The sort walks this array once: sequential access, cache-friendly, no pointer chasing.
The Union-Find Structure
Union-Find maintains a partition of vertices into disjoint sets (the connected components). It supports two operations:
find(x): returns the "root" representative of x's component.union(x, y): merges x's component with y's component.
The implementation uses two integer arrays of size V:
parent[i]: the parent of vertex i in its component's tree. Initiallyparent[i] = i.rank[i]: an upper bound on the height of i's subtree. Initially 0.
 Left: initial state, five components. Right: after four union operations, one component with node 0 as root. Path compression keeps future find() calls to a single hop.
Left: initial state, five components. Right: after four union operations, one component with node 0 as root. Path compression keeps future find() calls to a single hop.
Path compression keeps the trees flat. Every time you chase a chain of parent pointers up to the root, you rewire each visited node to skip directly to the root. The tree wants to be a linked list. Path compression says no. The iterative path-halving version (each node skips to its grandparent instead) achieves the same amortized bound without recursion:
def find(x): while parent[x] != x: parent[x] = parent[parent[x]] # point to grandparent x = parent[x] return x
Union by rank keeps trees from becoming chains. Without it, you could end up with a Union-Find tree that looks fine in theory and runs like a linked list in practice. Always attach the smaller-rank root under the larger-rank root. Rank only increases when two trees of equal rank merge:
def union(x, y): rx, ry = find(x), find(y) if rx == ry: return False if rank[rx] < rank[ry]: rx, ry = ry, rx parent[ry] = rx if rank[rx] == rank[ry]: rank[rx] += 1 return True
Without path compression: O(log n) per find. Without union by rank: O(log n) per find with path compression (specifically O(log n / log log n)). With both together, Tarjan proved in 1975 that each operation costs amortized O(α(V)), where α is the inverse Ackermann function, a value that never exceeds 4 for any input you will ever encounter in practice.
Why It's Correct: The Cut Property
The correctness of Kruskal's follows from exactly one theorem. Not a collection of lemmas. Not a 40-page chapter. Just this.
Cut Property. Let G be a weighted undirected graph with distinct edge weights. Let S be any proper non-empty subset of vertices. Let e be the minimum weight edge with one endpoint in S and one endpoint in V \ S. Then e belongs to every minimum spanning tree of G.
Proof by contradiction. Suppose T is an MST that does not contain e = (u, v), where u ∈ S and v ∉ S. Since T is a spanning tree, there exists a path P in T from u to v. This path must cross the cut (S, V \ S) somewhere, so it contains some edge f with one endpoint in S and one in V \ S. Since e is the minimum weight edge crossing the cut and edge weights are distinct, w(e) < w(f).
Now form T' = T - {f} + {e}. Adding e to T creates exactly one cycle (the path P plus edge e), and removing f breaks that cycle. So T' is still a spanning tree. Its weight is w(T') = w(T) - w(f) + w(e) < w(T). But T was supposed to be an MST. Contradiction. So e must be in every MST. □
How Kruskal's triggers this theorem at every step. When the algorithm considers edge e = (u, v), vertices u and v are in different components. Let S be u's current component. Every edge with weight smaller than w(e) that crosses the cut (S, V \ S) was processed earlier. Those earlier edges either:
- Connected two vertices already in the same component (skipped), or
- Connected two different components (added to MST, growing S or growing some other component).
If case 2 had ever applied to an edge crossing (S, V \ S) specifically, it would have merged v into S, but v is currently not in S. So case 2 never applied across this cut for a lighter edge. Therefore e is the minimum weight edge crossing (S, V \ S). By the cut property, e is safe to add.
This argument fires once per edge added to the MST, and always succeeds. The algorithm produces a valid MST.
When edge weights are not distinct, the MST may not be unique. The cut property still holds: the minimum weight crossing edge is safe, and Kruskal's finds some valid MST. Which one you get depends on tie-breaking in the sort.
Disconnected graphs produce a minimum spanning forest. The algorithm adds edges until no more can be added without a cycle. Each connected component of the graph contributes one spanning tree to the forest.
O(E log E): The Dominant Cost
Kruskal's algorithm time complexity is dominated by one operation: the initial sort. Every other phase is essentially free by comparison.
| Operation | Time | Space | Notes |
|---|---|---|---|
| Sort edges | O(E log E) | O(1) extra | Dominates the runtime |
| Initialize Union-Find | O(V) | O(V) | Two arrays of size V |
| Find (amortized) | O(α(V)) | O(1) | With path compression + union by rank |
| Union (amortized) | O(α(V)) | O(1) | With path compression + union by rank |
| Main loop (E edges) | O(E · α(V)) | O(V) | V-1 adds, rest skipped |
| Total | O(E log E) | O(E + V) | Sorting dominates |
Since E ≤ V² in a simple graph, log E ≤ 2 log V, so O(E log E) = O(E log V). Both forms appear in textbooks.
If edges arrive pre-sorted (a gift from the problem setter, or from integer weights that enable radix sort), the Union-Find loop dominates at O(E · α(V)). This is essentially O(E) for any graph you will encounter in practice.
Space breakdown: O(E) for the edge list, O(V) for the Union-Find arrays, O(V) for the MST output (at most V-1 edges). Total O(E + V).
Kruskal vs Prim: Which One to Use
Both algorithms find an MST. The argument about which one to use gets resolved faster than you'd think once you look at your data. The difference is in access patterns.
Kruskal's processes edges globally, sorted upfront. It is edge-centric: it doesn't care which vertex it is growing from. This makes it natural when you have an explicit edge list and the graph is sparse (E closer to V than to V²).
Prim's grows one connected component from a starting vertex, always adding the minimum weight edge that connects the component to an unvisited vertex. With a binary heap it runs in O(E log V). With a Fibonacci heap it achieves O(E + V log V), which is theoretically better for dense graphs. In practice, Prim's with a binary heap and an adjacency matrix benefits from better cache behavior on dense graphs.
Rule of thumb: sparse graph with an explicit edge list, use Kruskal's. Dense graph or adjacency matrix, use Prim's.
One Structure, Every Language
All implementations follow the same structure: a Union-Find class or struct, a sort on the edge list, and a loop that calls union and collects MST edges.
def kruskal(n: int, edges: list[tuple[int, int, int]]) -> tuple[list[tuple[int, int, int]], int]: parent = list(range(n)) rank = [0] * n def find(x: int) -> int: while parent[x] != x: parent[x] = parent[parent[x]] x = parent[x] return x def union(x: int, y: int) -> bool: rx, ry = find(x), find(y) if rx == ry: return False if rank[rx] < rank[ry]: rx, ry = ry, rx parent[ry] = rx if rank[rx] == rank[ry]: rank[rx] += 1 return True edges = sorted(edges) # sort by weight (first element) mst_edges: list[tuple[int, int, int]] = [] total_weight = 0 for weight, u, v in edges: if union(u, v): mst_edges.append((u, v, weight)) total_weight += weight if len(mst_edges) == n - 1: break return mst_edges, total_weight # Example: kruskal(5, [(2,0,1),(3,1,2),(5,1,4),(6,0,3),(7,2,4),(8,1,3),(9,3,4)]) # Returns: ([(0,1,2),(1,2,3),(1,4,5),(0,3,6)], 16)
What Problems It Solves
Minimum Cost Network Design
The most direct application: given a set of locations and the cost of connecting any pair, find the cheapest way to connect them all. Power grids, fiber optic networks, irrigation systems. The vertices are locations; the edges are possible connections with their costs; the MST is the cheapest connected network.
Single-Linkage Hierarchical Clustering
Build a complete graph where vertices are data points and edge weights are distances (Euclidean, cosine, or any other metric). Compute the MST. To get k clusters, remove the k-1 heaviest edges. The resulting connected components are the clusters. Single-linkage clustering and MST-based partitioning produce identical results, a fact that follows directly from the cut property.
The technique is used in genomics (clustering gene expression data), anomaly detection (outliers become isolated components when the heaviest edges are removed), and network community detection.
Image Segmentation
The Felzenszwalb-Huttenlocher algorithm (2004) segments images by treating pixels as vertices and color differences as edge weights. It builds a graph, computes something close to an MST, and uses the edge weight distribution to decide where to split components. It still ships in production computer vision pipelines.
Maximum Spanning Tree
The maximum spanning tree connects all vertices while maximizing total edge weight. Applications include maximum bandwidth paths in network routing and certain maximum likelihood problems in graphical models. To compute it: negate all weights and run Kruskal's, or just sort edges in descending order.
Approximation for Traveling Salesman
On a metric graph (edge weights satisfy the triangle inequality), an MST gives a 2-approximation for the Traveling Salesman Problem. The MST is a lower bound on the optimal TSP tour (drop any edge from the tour to get a spanning tree). Double the MST edges, find an Eulerian circuit, then shortcut repeated vertices. The result is a tour at most twice the optimal.
Bottleneck Spanning Tree
The MST is also a minimum bottleneck spanning tree: it minimizes the maximum edge weight across all spanning trees. This falls out of the correctness proof. Every time Kruskal adds an edge, it is the cheapest available option, so no spanning tree can avoid using a heavier edge.
How to Spot the Pattern
The Signal
The problem asks you to connect things at minimum cost. Specifically:
- "Minimum cost to connect all nodes / cities / computers."
- "Find the number of components after removing all edges heavier than threshold X."
- "Partition data into k groups maximizing the minimum inter-group distance."
- "Is there a spanning tree where the maximum edge weight is at most W?"
If you see a problem about connecting a set of nodes with a cost function, and the cost is the total of all chosen connections rather than a path between two specific nodes, MST is likely the tool.
The giveaway that separates MST from shortest path: Dijkstra finds the cheapest path between two specific vertices. Kruskal finds the cheapest structure connecting every vertex. If you need all vertices reachable, think MST. If you need to route between two specific points, think Dijkstra.
Worked Example 1: Cheapest Connections
Problem. There are n computers and a list of possible cables, each with a cost. Some computers are already connected via existing cables with cost 0. Find the minimum additional cost to network all computers.
Why MST fits. We need all computers reachable from all others. We want to minimize total cable cost. Existing connections are just edges with weight 0 in the graph.
Solution. Add every existing connection as an edge with weight 0. Add all possible cable routes with their costs. Run Kruskal's. The MST will include all weight-0 edges (they are processed first and never create cycles in a valid input). The remaining MST edges are the cables to buy.
This is LeetCode 1584 (Min Cost to Connect All Points) and countless variants.
Worked Example 2: Maximum Minimum Distance Clustering
Problem. You have n points in a 2D plane. Find a partition into k clusters such that the minimum distance between any two points in different clusters is maximized.
Why MST fits. This is equivalent to: find a partition of the MST into k trees by removing k-1 edges, maximizing the minimum removed edge weight. The k-1 heaviest edges in the MST are exactly the edges to cut.
Solution. Build a complete graph with Euclidean distances as weights. Run Kruskal's. Collect all MST edges sorted by weight. Remove the k-1 heaviest. The connected components of the remaining MST are the clusters. The answer (minimum inter-cluster distance) is the weight of the lightest removed edge.
 Remove the 2 heaviest MST edges (amber) and the three remaining components become your clusters. The answer is the lighter of the two removed edges.
Remove the 2 heaviest MST edges (amber) and the three remaining components become your clusters. The answer is the lighter of the two removed edges.
Why not build the complete graph explicitly? For large n, E = O(n²) edges are expensive. In practice you can often prune: for Euclidean distance, Delaunay triangulation contains the MST, and computing it gives O(n log n) edges instead of O(n²).
A Non-Obvious Subtlety: What "Cycle" Means for Union-Find
Many people learn Kruskal's and think the Union-Find is doing cycle detection. It is, but the reason it works is worth understanding precisely.
A spanning forest on k components has exactly V-k edges. When you add an edge between two different components, the edge count goes to V-k+1 and the component count to k-1. Still a forest. When you add an edge within a single component, you would create a cycle, so you skip it.
Union-Find detects the second case by checking whether find(u) == find(v). If they share a root, they're in the same component. Adding this edge would create a cycle. Skip. If they have different roots, merge them.
The subtle point: you don't need to find the actual cycle. You just need to know whether a cycle would form. Union-Find answers this in O(α(V)) without traversal.
Compare this with the naive alternative: before adding each edge, run a DFS or BFS from one endpoint to see if you can reach the other. That costs O(V) per edge and O(EV) overall, which for a dense graph is O(V³). It works. It is also three orders of magnitude slower. Union-Find drops this to effectively O(E).
Recap
- Kruskal's algorithm sorts all edges by weight and greedily adds each one that doesn't create a cycle, stopping at V-1 edges.
- Correctness follows from the cut property: the minimum weight edge crossing any cut of the graph belongs to some MST. Each edge Kruskal adds is provably the minimum crossing some cut at that moment.
- The Union-Find structure with path compression and union by rank brings cycle detection to O(α(V)) amortized per operation, reducing the Union-Find phase to O(E · α(V)), negligible next to sorting.
- Total complexity: O(E log E) time, O(E + V) space. Pre-sorted edges reduce this to O(E · α(V)).
- Kruskal's produces a spanning forest on disconnected graphs, handles negative weights correctly, and finds any valid MST when weights are not distinct.
- Use Kruskal's for sparse graphs with an explicit edge list. Use Prim's for dense graphs or adjacency matrix representations.
- Pattern signals: minimum cost to connect all nodes, maximum minimum inter-group distance, bottleneck path problems, or anything requiring all-vertex reachability at minimum total cost.
If you want to practice explaining this under interview conditions, SpaceComplexity runs voice-based DSA mock interviews with rubric feedback. Saying "cut property" in your head and saying it clearly to an interviewer while tracing through an example are very different skills.
MST problems show up regularly at every major company. The Union-Find algorithm is worth drilling separately since it appears in dozens of other problems beyond MST. For graph problems where you need shortest paths between specific pairs rather than all-vertex connectivity, see Dijkstra's algorithm. And for a primer on how to read the graph itself, graph data structures covers adjacency lists and matrices with their tradeoffs.