Logging System Design: The Write Path Never Waits for the Read Path
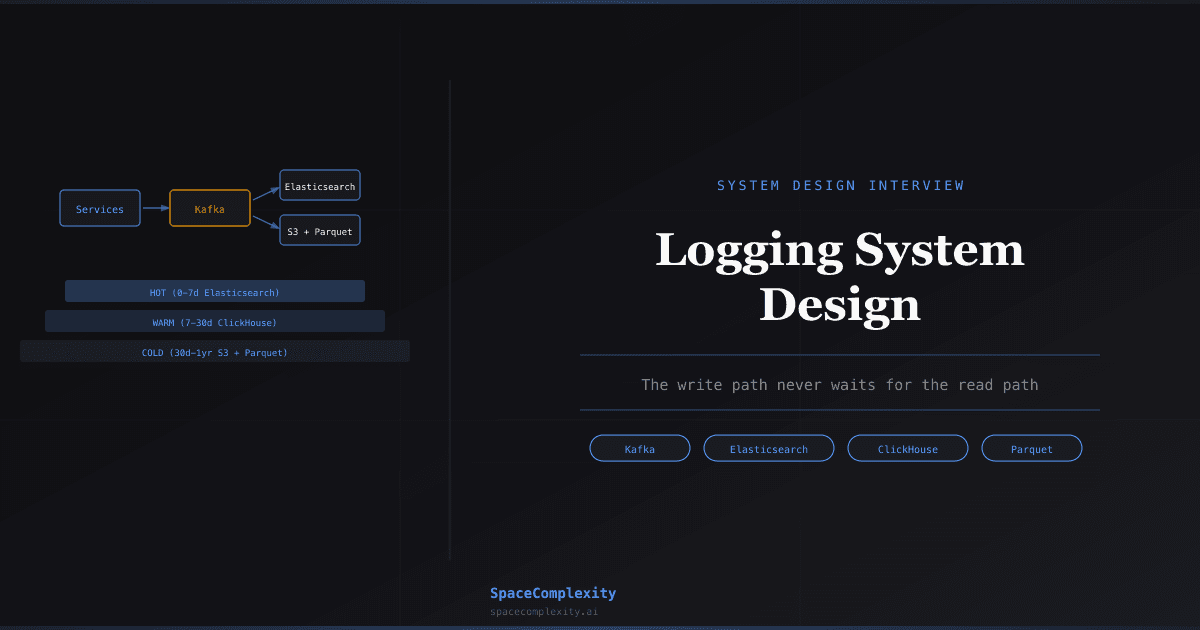
- Write path and read path are almost entirely separate pipelines; log writes must never block your application threads
- Kafka decouples producers from storage backends, absorbs traffic spikes, and lets you replay logs if Elasticsearch falls over
- Tiered storage (Elasticsearch for 7 days, ClickHouse for 30 days, S3/Parquet for a year) cuts costs 5-10x versus storing everything on fast SSDs
- Structured JSON with a mandatory
trace_idis the schema discipline that makes cross-service debugging possible; enforce it at the agent, not the database - The query router hides tier complexity from callers, fans out by time range, and merges results via cursor-based pagination
- Full-text indexing versus label-only indexing is the dominant cost tradeoff: Elasticsearch at roughly $15K/month versus Loki-style label indexing at roughly $3K
Every company has logs. Almost none of them have a logging system. They have log.info() calls scattered across a dozen services, a 3-day Elasticsearch retention window someone set in 2021, and an on-call engineer who finds out about production incidents from a customer email.
The logging system design interview question is a good one. It tests whether you know the difference between writing logs and collecting them, and whether you can reason about a write-heavy system where reads are exploratory and the two pipelines barely touch each other.
 r/ProgrammerHumor: loggingItRight (10.6K upvotes)
r/ProgrammerHumor: loggingItRight (10.6K upvotes)
Clarify Scope Before You Draw Anything
Application logs are different from access logs, which are different from audit logs. They share infrastructure but diverge on retention, indexing, and query patterns. The first question to ask: what are we logging and for whom?
For this walkthrough, assume application and access logs from a multi-service backend. About 100 services, each generating around 1,000 log lines per second under normal load, with spikes to 5x during high traffic. That is roughly 1 TB of raw logs per day. Retention target: 30 days searchable, 1 year archival.
Functional requirements: ingest logs from any service with minimal client-side work, store them durably, support full-text search and field-based filtering (by service, level, trace ID, time range), and return results within 5 seconds for most queries.
Non-functional requirements: write availability beats read consistency. Losing a log is worse than seeing a stale query result. Writes must tolerate backend slowness without blocking the application. The system must be cost-aware, because storage at scale is the dominant cost driver.
The Mental Model: Two Pipelines That Barely Touch
The system has two pipelines that operate almost independently: a fast write path and a slower read path.
Writes need to be durable, high-throughput, and non-blocking. The application must never slow down because the logging backend is struggling. The read path needs to be expressive and reasonably fast, but a 3-second search is fine. A 300ms write latency is not.
This asymmetry drives every component choice. Sketch both pipelines before going deep on either.
 The write path is fast, durable, and non-blocking. The read path is expressive and accepts more latency. They barely share any components.
The write path is fast, durable, and non-blocking. The read path is expressive and accepts more latency. They barely share any components.
The Write Path Has Three Jobs
Push Wins. Here Is Why.
The first real decision is how logs get from your services into the pipeline.
Push: the service writes to a local agent, which forwards logs upstream. This is the standard choice.
Pull: a centralized collector scrapes log files on a schedule. Simpler to reason about, but it creates collection lag and does not work well for ephemeral containers. Your pod is gone before the collector comes calling.
For a containerized environment, the production pattern is a DaemonSet agent (one log collector per Kubernetes node, reading from container stdout/stderr) for most services. For services that need routing to separate destinations or custom log formats, a sidecar agent per pod is the escape hatch. Filebeat and Fluentd are both production-proven. The property you must have from any agent: disk-buffered output, so the agent absorbs backpressure without dropping logs. The infrastructure-level push-vs-pull framing is in The Trade-off Maze.
Kafka as the Write Spine
After collection, logs flow into Kafka. At any meaningful scale, this is not optional.
Kafka decouples producers from consumers, absorbs traffic spikes, and makes downstream storage independently scalable. It also gives you replayability: if your Elasticsearch cluster falls over for two hours, you can replay the backlog when it recovers. That property alone makes Kafka worth the operational weight.
Partition logs by service_id. This keeps logs from the same service ordered and co-located on a partition, which matters if you ever run stateful stream processing. Avoid partitioning by timestamp (creates hot partitions) or by host (too granular, rebalancing nightmare). For 100K messages/sec: 64 partitions, replication factor 3, message retention 24 hours.
A stream processor (Flink or a simple Kafka Streams job) sits between Kafka and storage. It handles enrichment, filtering, and routing. Keep it stateless if you can. Its job is to normalize the schema, drop debug logs in production if needed, and write to multiple sinks.
Schema Discipline Saves You Later
Ad-hoc string logs are a trap. A canonical JSON schema is not optional.
{ "timestamp": "2026-05-27T03:47:12.843Z", "level": "ERROR", "service": "payment-service", "version": "v2.14.1", "trace_id": "abc123def456", "span_id": "789xyz", "message": "Failed to charge card: timeout after 5000ms", "host": "prod-node-42", "env": "production", "attributes": {} }
The trace_id field is not decoration. It is the thread that stitches distributed logs together across services. Without it, debugging a cross-service failure means jumping between unrelated streams by timestamp and guessing. You will be doing that at 3am.
Enforce schema at the agent level, not at the database. Logstash or Fluent Bit can parse, validate, and enrich before Kafka. Garbage-in means garbage queries forever, and there is no way to recover the original information after the fact. No one regrets adding schema enforcement. Everyone regrets skipping it.
Why One Storage Tier Is Never Enough
1 TB/day for 30 days is 30 TB. For 1 year, 365 TB. Storing all of it on fast SSDs would cost a small fortune and gain you nothing, because 95% of log queries happen against the last 3 days. The other 97 days of logs mostly sit there, waiting for a compliance audit or a postmortem that never comes.
The solution is tiered storage: fast nodes for recent logs, slower nodes for historical analysis, and object storage for archival. Each tier trades query latency for cost.
 ILM policies handle the transitions automatically. You set the policy once and forget it exists, which is the best possible relationship to have with your storage infrastructure.
ILM policies handle the transitions automatically. You set the policy once and forget it exists, which is the best possible relationship to have with your storage infrastructure.
Hot Tier (0-7 days): Elasticsearch on SSDs
For the recent window, Elasticsearch is the standard. Its inverted index (Lucene under the hood) makes full-text search on message content fast, and its JSON-native query language matches the log schema well. Each Elasticsearch shard is a self-contained Lucene index, and you size shards at 10-50 GB to keep recovery and rebalancing manageable.
Elasticsearch indexes every field by default. For 1 TB/day of raw logs, this produces 3-5 TB of index data per day including replicas and metadata. To control that cost, disable indexing on high-cardinality fields like host and trace_id that you query only by exact match, using the keyword type instead of text. Elasticsearch also uses bloom filters internally per segment to decide whether a shard can possibly contain a given term before touching disk, which matters at this write volume.
Index Lifecycle Management (ILM) automates rollover and tier transitions. A typical policy: roll over the index at 50 GB or 1 day, move to warm after 7 days, delete after 30 days.
Warm Tier (7-30 days): ClickHouse
Once logs are more than a week old, incident response queries drop to near zero. The access pattern shifts to trend analysis, capacity planning, and compliance. These workloads are aggregation-heavy, not full-text search heavy.
This is exactly where ClickHouse beats Elasticsearch by an order of magnitude. ClickHouse's MergeTree engine stores data in columnar format with LSM-style writes. For a query like "show me the p99 error rate for the payment service over the last 3 weeks, grouped by hour," ClickHouse reads only the level, service, and timestamp columns. Elasticsearch reads entire documents. The performance gap on analytical queries runs 10-30x in ClickHouse's favor.
If your team cannot operate two query backends, you can use Elasticsearch's cold and frozen node tiers for warm data instead. Slower and more expensive than ClickHouse, but one fewer system to run. Pick your tradeoff consciously.
Cold Tier (30 days to 1 year): S3 and Parquet
For compliance and historical queries, logs move to object storage as Parquet files. Parquet's columnar format compresses raw logs at roughly 10:1. At 1 TB/day raw, that is 100 GB/day stored. One year of logs lands at around 36 TB, which costs roughly $800/month on S3 standard.
Query cold storage with AWS Athena or Trino. Expect 30-60 seconds for large scans. That is fine for queries you run once a month. Nobody expects a one-year search to feel snappy.
The Read Path: One API, Three Backends
Hide the tiered backend from the caller. You give it a time range and filter criteria; the query router decides which tier to hit.
GET /logs
?service=payment-service
&level=ERROR
&from=2026-05-20T00:00Z
&to=2026-05-27T00:00Z
&q=timeout
&page_token=<cursor>
The router splits the time range across tiers, fires parallel sub-queries, and merges results ordered by timestamp. For cross-tier queries, cursor-based pagination is the right model: each tier returns its own cursor, and the router merges by timestamp on each page fetch. The cursor encodes both the tier and the position within that tier.
 The caller sees one API. Under the hood, the router is doing the messy work of hitting three different backends and stitching their results together by timestamp.
The caller sees one API. Under the hood, the router is doing the messy work of hitting three different backends and stitching their results together by timestamp.
Full-text search on the q parameter is expensive. Add a guard in the UI that warns when a free-text query spans more than 24 hours. A 1-hour window search is fast. A 30-day full-text scan will touch petabytes. Your Elasticsearch cluster will have opinions about that.
Three Tradeoffs Worth Naming Out Loud
1. Index all fields vs label-only indexing. Elasticsearch indexes everything, giving flexible search but expensive storage. Grafana Loki takes the opposite approach: index only a small set of labels (service, env, level) and store log content as unindexed compressed chunks. Loki is dramatically cheaper for high-volume logs where most searches are filter-by-label rather than free-text. At 1 TB/day with full Elasticsearch indexing, you might spend $15K/month on storage. With Loki-style label indexing, closer to $3K. The right choice depends on whether your engineers actually need full-text search or just level-and-service filtering. Most teams think they need full-text. Half of them are wrong.
2. Synchronous vs asynchronous writes. The application could write logs synchronously (blocking until the agent acknowledges) or asynchronously (fire and forget to a local buffer). Async wins for application availability, but you accept a small window where buffered logs can be lost if the agent crashes without flushing. Almost every production system accepts this tradeoff. Blocking application threads on log writes is worse. You are not Netflix. Your logs are not worth slowing your checkouts.
3. Single Kafka topic vs per-service topics. Per-service topics give clean isolation and independent retention policies. A single topic with service-name partitioning is operationally simpler. At 100 services, a shared topic with 64 partitions is manageable. At 1,000 services with different compliance requirements, per-service topics are worth the overhead.
The 45-Minute Clock
- 0-5 min: clarify scope. Application vs audit vs access logs, scale, retention, query SLA.
- 5-12 min: functional and non-functional requirements. Write the scale math (messages/sec, GB/day, storage for N days).
- 12-22 min: write path. Collection agents, Kafka, schema design.
- 22-32 min: storage. Explain the hot/warm/cold split and why tiering matters.
- 32-40 min: read path. Query router, API design, pagination.
- 40-45 min: one tradeoff deeply. Pick whichever one your interviewer probed hardest.
Two things separate a good answer from a great one. The schema discussion: most candidates skip it, and it is where most production bugs originate. The tiering rationale: anyone can say Elasticsearch, but few can explain why you would replace it with ClickHouse at 30 days and Athena at 90.
If you want to practice walking through designs like this out loud until they flow naturally under pressure, SpaceComplexity runs voice-based system design mock interviews with rubric-based feedback. Explaining an architecture is a different skill than knowing one.
Logging System Design: The Quick Recap
- Write path: DaemonSet agents, disk-buffered, feeding Kafka, then dual-write to Elasticsearch (hot) and S3 (cold).
- Schema: structured JSON with mandatory
trace_id; enforce at the agent before Kafka. - Storage: hot (Elasticsearch + SSDs, 7 days) to warm (ClickHouse, 30 days) to cold (S3 + Parquet, 1 year).
- Read path: query router fans out to the right tier by time range, cursor-based pagination merges results.
- Key tradeoffs: index density vs cost, sync vs async writes, single vs per-service Kafka topics.
- The clock: scope (5 min) → scale math (7 min) → write path (10 min) → storage (10 min) → reads (8 min) → tradeoffs (5 min).