Notification System Design Interview: The Complete Walkthrough
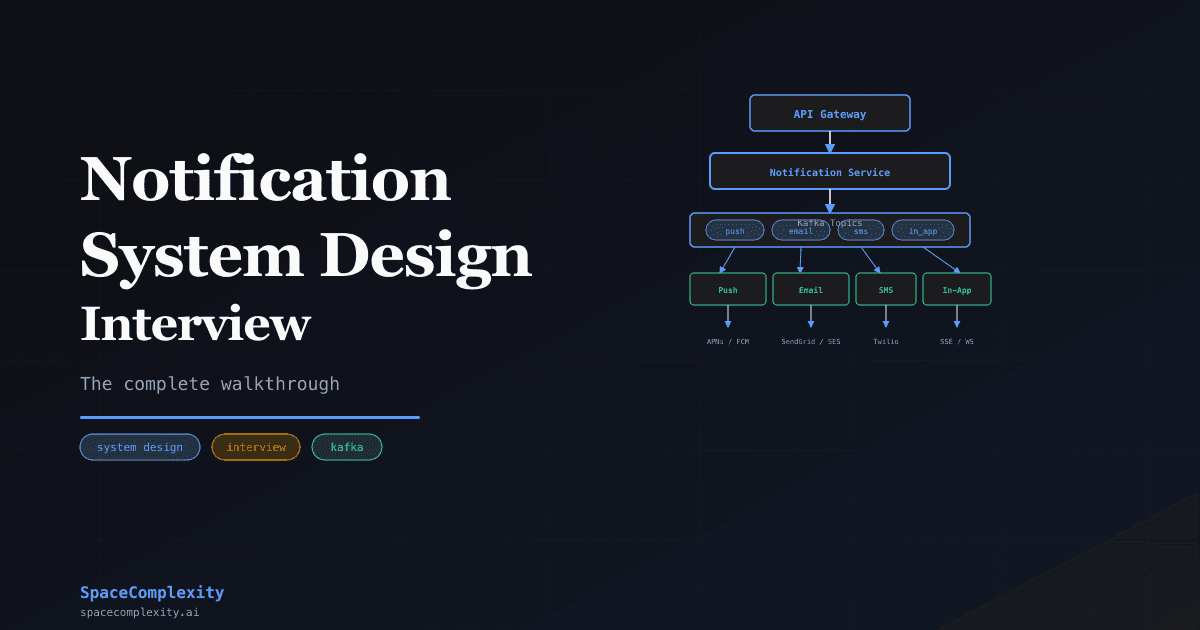
- Separate Kafka topics per channel (push, email, SMS, in-app) so one provider outage never cascades to others
- Check user preferences in the orchestrator, cached in Redis, before anything hits the queue
- Idempotency keys stored in Redis for 24 hours give you at-least-once-but-practically-once delivery without two-phase commit
- Fanout service handles bulk sends in batches of 1,000; never block the synchronous path for audience queries
- Cassandra for the notification log (write-heavy, partition by user_id), Postgres for preferences and device tokens
- Exponential backoff with jitter on all third-party calls; dead-letter queue after 5 failed attempts
- SSE for foreground in-app notifications, push for background; the architecture needs both
Most engineers walk into a notification system design interview thinking it's easy. Email, push, SMS. You'll be done by lunch. Probably before the second coffee.
The trap is that core delivery is the simple part. What breaks at scale is everything around it: idempotency, user preferences, rate limiting, fanout for high-follower users, and keeping a SendGrid outage from taking down your SMS workers. The outer shell is what separates a mid-level answer from a strong hire.
This walkthrough follows the same sequence an interview runs: requirements through tradeoffs, with a pacing guide at the end so you know where your 45 minutes go.
Scope First. Don't Draw Yet. (5 Minutes)
Don't start drawing boxes. Interviewers leave the prompt vague on purpose to see whether you clarify or assume. You'd be surprised how many candidates skip this and start drawing boxes. The interviewer watches this happen and writes things in their notepad.
Ask three things: which channels (push, email, SMS, in-app), rough daily volume, and delivery guarantee (at-least-once or exactly-once). A typical answer: 10 million push notifications, 5 million emails, and 1 million SMS per day. That's roughly 180 notifications per second at peak.
Functional requirements to agree on:
- Send notifications via push (iOS/Android), email, SMS, and in-app
- Respect per-user, per-channel opt-out preferences
- Track delivery status
- Support templated messages with user-specific data
Non-functional requirements:
- Push and SMS: under 5 seconds for transactional, batching fine for promotional
- At-least-once delivery with deduplication (not exactly-once, which is expensive)
- Fault isolation: an email provider outage must not affect push delivery
Run the Numbers Out Loud (2 Minutes)
Talking through the math signals operational instinct, even when the estimates are approximate.
16 million notifications per day across all channels. At 185 per second average, maybe 500 per second peak with 3x spikes. Notification records are small: 1 KB each. 16 million per day at 1 KB is 16 GB of writes per day, about 175 MB per second at peak. A single Kafka cluster handles this with room to spare.
Notification System Architecture: Keeping Channels Independent

API Gateway feeds the orchestrator. The orchestrator splits into per-channel Kafka topics. Stateless workers handle delivery. Nothing shares a queue.
Put a message queue between the orchestrator and the delivery workers, with a separate queue per channel. A backlogged email queue never delays push notifications, and a Twilio rate limit error never touches email throughput.
How an Event Becomes a Notification
Other microservices call the notification API when something happens: a payment completes, a friend sends a message, a deployment finishes.
The API accepts a thin event object: which user, which notification type, and a payload of key-value pairs. The notification service looks up the user's preferences, renders the template, and publishes one message per enabled channel to Kafka. The calling service gets a 202 Accepted with a notification ID.
POST /v1/notifications { "user_id": "usr_abc123", "type": "payment_received", "idempotency_key": "evt_xyz789", "payload": { "amount": "42.00", "from": "Alice" } }
The idempotency_key is the caller's event ID. Workers store processed keys in Redis with a 24-hour TTL and skip duplicate messages. This is your at-least-once-but-effectively-once guarantee.
Speaking of effectively-once, here's what happens when you run your test suite without idempotency keys:

Your idempotency key is the only thing standing between you and that inbox.
Filter Before the Queue, Not After
Before anything goes on the queue, check whether the user actually wants this notification.
The preferences check should happen in the orchestrator, not in individual channel workers, so you only hit the database once per event. Store preferences in Redis with a short TTL (30 seconds). The underlying source of truth is a PostgreSQL table:
CREATE TABLE user_notification_preferences ( user_id UUID NOT NULL, channel TEXT NOT NULL, -- 'push', 'email', 'sms', 'in_app' notif_type TEXT NOT NULL, -- 'marketing', 'transactional', etc. enabled BOOLEAN NOT NULL DEFAULT true, quiet_start TIME, -- e.g. 22:00 local time quiet_end TIME, -- e.g. 07:00 local time PRIMARY KEY (user_id, channel, notif_type) );
Quiet hours matter most for push. Nobody wants a "Your weekly digest is ready!" notification at 2 AM. If a user is in their quiet window, buffer the message to a delayed queue rather than dropping it.
One Queue Per Channel, Not One Queue for Everything
Use separate Kafka topics per channel: notifications.push, notifications.email, notifications.sms, notifications.in_app. Within each topic, add a priority dimension: transactional messages (password reset, payment confirmation) go to a high-priority partition; marketing messages go to a low-priority partition.

HIGH lane: your password reset and payment alerts. LOW lane: the newsletter nobody asked for.
This matters at 3 AM on Black Friday. You want password reset emails flowing even when your promotional email queue has 20 million messages backed up.
What Each Worker Actually Does
Each channel has a dedicated worker pool. Workers are stateless and scale horizontally.
Push workers send to APNs for iOS and FCM for Android. Keep persistent HTTP/2 connections open to both. APNs enforces a 4 KB payload limit and authenticates via JWT tokens refreshed every 60 minutes, which it will enforce silently, at 3 AM, on the one night you're not on-call. FCM allows collapse_key for message deduplication at the provider level. Store device tokens in a separate table and handle token invalidation: when APNs returns a 410 Gone response, delete the token immediately.
Email workers call SendGrid or SES. Email is slower and bulkier. Batch promotional messages into the off-peak window (3 AM user-local time). Transactional emails go out immediately. Keep an unsubscribe list synchronized with your provider to avoid spam complaints.
SMS workers call Twilio or Vonage. SMS is expensive. Reserve it for OTPs, two-factor codes, and high-priority alerts. Never send promotional SMS without explicit opt-in. Your users will absolutely unsubscribe, and then Twilio will still charge you for the message anyway.
In-app workers write to a Redis stream. The client reads via WebSocket or Server-Sent Events (SSE). SSE is simpler: HTTP, unidirectional, auto-reconnects. WebSockets make more sense if the product also needs client-to-server real-time communication, like a chat thread. For notifications alone, SSE is the right default.
What Lives in Postgres vs Cassandra

Postgres owns the structured, relational config. Cassandra owns the write-heavy time-series log.
Use Postgres for the structured, relational data:
-- device tokens (many per user) CREATE TABLE device_tokens ( id UUID PRIMARY KEY, user_id UUID NOT NULL, token TEXT NOT NULL UNIQUE, platform TEXT NOT NULL, -- 'apns' or 'fcm' created_at TIMESTAMPTZ, last_seen TIMESTAMPTZ ); -- notification templates CREATE TABLE templates ( type TEXT PRIMARY KEY, channel TEXT NOT NULL, subject TEXT, body TEXT NOT NULL -- Jinja2 / Handlebars template );
Use Cassandra (or DynamoDB) for the notification log. You write millions of records per day and query by user_id to show a notification inbox. Cassandra's write throughput and partitioned reads are built for exactly this access pattern:
CREATE TABLE notifications ( user_id UUID, created_at TIMEUUID, notif_id UUID, channel TEXT, status TEXT, -- 'sent', 'delivered', 'failed', 'read' payload TEXT, PRIMARY KEY (user_id, created_at) ) WITH CLUSTERING ORDER BY (created_at DESC);
Where Things Break Under Load
Retry with exponential backoff. Workers catch transient errors from third-party APIs and retry with delays of 1s, 2s, 4s, 8s, 16s, 32s. Add random jitter to each delay to prevent thundering herds on recovery. The thundering herd problem is exactly what it sounds like: your entire worker fleet hitting a recovering service at the same instant, immediately killing it again. Jitter is the humble hero of distributed systems.
After 5 attempts, route the message to a dead-letter queue for manual inspection and alerting. The dead-letter queue is where notifications go to think about what they've done.
Rate limiting per user. Even valid notifications become harassment without rate limits. A user shouldn't receive more than N push notifications per hour from your system. You have definitely muted an app that forgot this rule. Implement it with a Redis sliding window counter checked in the worker before calling the provider.
The high-fanout problem. If a notification type is "alert all users in Chicago," you need to fan out to potentially millions of recipients from a single event. Don't do this synchronously. Your orchestrator called the database, your database is now on fire, and you've delivered zero notifications. A fanout service reads the audience query, pages through users in batches of 1,000, and publishes individual messages to the channel queue. The orchestrator accepts the request, enqueues the fanout job, and returns immediately.

One event in. Millions of individual messages out. The synchronous path does not survive this.
Tradeoffs Worth Naming Out Loud
At-least-once vs exactly-once. Exactly-once delivery in a distributed system requires two-phase commit or a transactional outbox pattern. The cost in latency and complexity is usually not worth it for notifications. Two-phase commit also gives you a 40-page runbook for when it fails. At-least-once with an idempotency key stored in Redis for 24 hours gives you near-exactly-once at a fraction of the cost.
Kafka vs SQS. Kafka gives you replay, partitioned ordering, and high throughput. SQS is simpler to operate and fully managed. For most teams under 50 million notifications per day, SQS per channel is fine and cheaper to run. Kafka makes sense when you need replay to debug issues or backfill a new channel worker.
Push or pull for in-app. If users have the app open, SSE or WebSockets is the right answer. If the app is in the background, the OS cuts the connection and you need push notifications or silent background refresh. A real system does both: WebSocket for foreground, push for background.
Batching promotional notifications. Sending 5 million marketing emails the moment a campaign launches will saturate your email workers and spike costs. Use a scheduled fanout that spreads delivery over a 2-hour off-peak window. Most email providers enforce rate limits per second anyway.
Where Your 45 Minutes Go
45 minutes is tight. Here's the breakdown:
| Phase | Time | What to cover |
|---|---|---|
| Requirements + scope | 5 min | Channels, volume, guarantees |
| Capacity estimates | 3 min | Req/s, storage per day |
| High-level diagram | 10 min | Gateway, orchestrator, Kafka, workers, providers |
| Component deep dive | 12 min | Preferences, templates, retry, dedup |
| Data model | 8 min | Postgres for config, Cassandra for log |
| Bottlenecks + tradeoffs | 7 min | Fanout, backoff, at-least-once, queue choice |
You will go over on the high-level diagram. Everyone does. Plan for 15 minutes and apologize for exactly zero seconds of it.
Draw the high-level diagram first, then narrate it. Don't write code until the interviewer asks. Every box you add, say what problem it solves. When you introduce Kafka, say "this decouples ingestion from delivery and lets each channel scale and fail independently." Interviewers are scoring tradeoff articulation, not just pattern recognition.
If you get a follow-up like "what if APNs is down?", that's a gift. Answer: messages stay in the Kafka partition, the worker backs off, and your SLA monitoring fires an alert. Nothing is lost because the queue is the buffer.
The Short Version
- Separate queues per channel so failures stay isolated
- Idempotency keys in Redis for at-least-once-but-practically-once delivery
- User preferences check in the orchestrator, cached in Redis
- Postgres for config and preferences, Cassandra for the notification log
- Fanout service for bulk sends, not the synchronous path
- Exponential backoff with jitter for all third-party calls
- Dead-letter queues for failed messages after max retries
- SSE for foreground in-app, push for background
If you want to practice walking through this design under real interview pressure, SpaceComplexity runs voice-based system design mock interviews with rubric feedback on exactly these kinds of architectural tradeoffs.