Rabin-Karp Algorithm: Roll a Hash Across the Text, Search in O(n+m)
- Rolling hash shrinks every m-character window to one integer, so most positions are rejected in O(1) instead of O(m)
- The roll formula removes the leftmost character, shifts left, and appends the new right character in three arithmetic ops per step
- Expected O(n+m) time, but worst case O(nm) when the modulus is tiny or input is adversarial; a large prime like 10^9+7 keeps the expected spurious hit count near zero
- Negative modulo trap: C, Java, Go, and C++ truncate toward zero, so add
qbefore the inner mod or your hashes go negative and never match - Multi-pattern search is Rabin-Karp's structural edge over KMP: hash all patterns into a set and do one O(1) lookup per window
- Binary search plus rolling hash finds the longest duplicate substring in O(n log n); this is the approach behind LeetCode 1044
You are grepping a 1 MB log file for a 100-character error signature. Naive string search is O(nm). That is 100 million character comparisons. The cursor blinks. You go get coffee. The Rabin-Karp algorithm fixes this by shrinking every m-character substring to a single integer. Most positions get rejected in one comparison. Only when two integers match do you verify the actual characters. In practice the algorithm runs in O(n + m).
The one-sentence mental model: turn the pattern and every same-length window of the text into a number, compare numbers instead of strings, and verify only on a number match.
Reach for Rabin-Karp when you need to find all occurrences of a pattern, search for many patterns at once, or discover repeated substrings of a given length. It does not beat KMP or Boyer-Moore on a single-pattern, single-search benchmark, but it dominates when the number of patterns grows or when you need "does any duplicate of length k exist?" logic.
A String Is Just a Number in Disguise
Every m-character substring can be treated as a base-d integer:
hash("ABA") = ord('A') * d^2 + ord('B') * d^1 + ord('A') * d^0
With d = 256 (covering all ASCII) and arithmetic taken modulo a large prime q, this maps any string of length m to a number in [0, q). Two equal strings always get the same number. Two different strings usually get different numbers.
The hash is a lossy fingerprint. Collisions are possible, meaning different strings can share a hash value. The algorithm treats a hash match as "probably equal" and then confirms with a direct comparison. The fraction of false matches depends on how large q is.
Every Substring Is a Polynomial
hash(s[0..m-1]) = s[0]*d^(m-1) + s[1]*d^(m-2) + ... + s[m-1]*d^0 (mod q)
Computed efficiently via Horner's method, left to right:
h = 0 for c in s: h = (h * d + ord(c)) % q
Each step is a multiply-and-add. No exponentiation needed. The final result is a number in [0, q) that represents the entire substring.

Horner's method turns three characters into one integer, one multiply-and-add at a time.
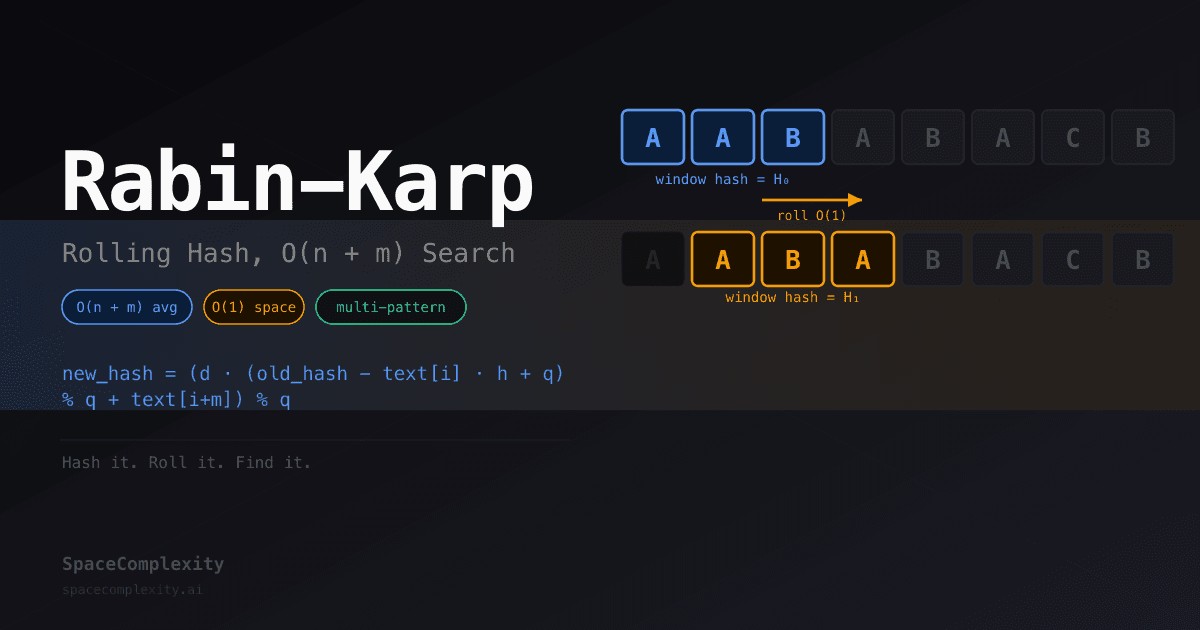
Rolling the Window in O(1)
Recomputing the hash from scratch at each of the n - m + 1 positions costs O(m) per position, giving O(nm) total. That is the naive algorithm with extra steps. The trick is to roll the hash forward.
You have the hash of text[i..i+m-1]. You want the hash of text[i+1..i+m]. Three things happen:
- Remove the leftmost character's contribution. Character
text[i]sits at positiond^(m-1)in the hash. Subtracttext[i] * d^(m-1). - Shift everything left. Multiply the result by
d. Each remaining character's power increases by one. - Append the new rightmost character. Add
text[i + m].
The compact formula, with h = d^(m-1) % q precomputed once:
new_hash = (d * (old_hash - text[i] * h) + text[i + m]) mod q
Each roll is three arithmetic operations: O(1). Across all n - m + 1 positions, rolling costs O(n) total.

Three operations: subtract the outgoing character, multiply to shift powers, add the incoming character. O(1) per slide.
Spurious Hits: When the Number Lies
Sometimes new_hash == pattern_hash but the strings are different. This is a spurious hit, a hash collision. The hash looked you right in the eye and lied. When it happens, the algorithm falls back to an O(m) character comparison.
How often do spurious hits occur? For a random string and a random prime q, the probability that any given position produces a spurious hit is about 1/q. With q = 10^9 + 7 and a text of length 10^6, the expected number of spurious hits per run is 10^6 / 10^9 ≈ 0.001. In practice you will almost never see one.
The worst case is O(nm), but it requires either a tiny modulus or a maliciously crafted input. With a large prime and normal data, the algorithm runs in O(n + m). The malicious-input case is a real concern for hash tables exposed to user input. For string search over your own logs, it is not.
What Every Operation Costs
| Operation | Time | Space | Notes |
|---|---|---|---|
Precompute h = d^(m-1) % q | O(m) | O(1) | Paid once before the loop |
| Compute initial hashes | O(m) | O(1) | Pattern hash and first window hash |
| Roll window one position | O(1) | O(1) | Three arithmetic ops |
| Verify match (hash hit) | O(m) | O(1) | Per true match or spurious hit |
| Full single-pattern search | O(n + m) avg, O(nm) worst | O(1) | Worst case requires many collisions |
| Full multi-pattern search (k patterns) | O(n + total pattern length) avg | O(k) | Hash set lookup per window |
Why O(n + m) on Average
The preprocessing phase takes O(m): compute h, compute the pattern hash, compute the first window hash. The sliding phase visits n - m + 1 windows, each rolled in O(1), for O(n) total. At each window, you do a single integer comparison. Only on a hash match do you spend O(m) on verification.
Expected total verification work = O(m) × (actual matches + spurious hits). With q = 10^9 + 7, the expected number of spurious hits over the whole run is (n - m + 1) / q, which rounds to zero for any practical input. So expected total is O(n + m + m × actual_matches).
For most searches, actual_matches is small. The whole thing is O(n + m).
Why the Worst Case Is O(nm)
Set q = 2. Now every hash is 0 or 1. The probability of a spurious hit at each position jumps to 50%. Nearly every position triggers an O(m) verification. With n positions and O(m) work each, you get O(nm). Nobody does this on purpose, but a carelessly small modulus gets you there.
The lesson is not "avoid Rabin-Karp." The lesson is: choose a large prime. 10^9 + 7 and 10^9 + 9 are both standard. For adversarial inputs, run two independent (base, modulus) pairs in parallel. A spurious hit under both hashes has probability 1 / (q₁ × q₂) ≈ 10^{-18}. You are more likely to be struck by lightning.
The Negative Modulo Trap
The roll formula subtracts a term before multiplying. In C, Java, Go, and C++, the % operator truncates toward zero, so (-3) % 7 == -3. If old_hash - old_left * h goes negative, your hash becomes negative, and the comparison with the pattern hash (always non-negative) will never match. This bug sits in your code silently. Every test passes. The pattern finds matches on short strings. Then a character above ASCII 127 shows up, an intermediate goes negative, and suddenly you get zero results. No exception. Just silence.
Always add q before the inner modulo:
new_hash = (d * ((old_hash - old_left * h % q + q) % q) + new_right) % q
Python and Ruby have floor division % (always non-negative), so the + q is technically redundant there, but including it makes the code portable and self-documenting.
One Structure, Every Language
The implementations below search text for all occurrences of pattern and return the starting positions. All use d = 256 (full ASCII range) and q = 1_000_000_007.
def rabin_karp(text: str, pattern: str) -> list[int]: n, m = len(text), len(pattern) if m > n: return [] BASE = 256 MOD = 1_000_000_007 h = pow(BASE, m - 1, MOD) pattern_hash = 0 window_hash = 0 for i in range(m): pattern_hash = (pattern_hash * BASE + ord(pattern[i])) % MOD window_hash = (window_hash * BASE + ord(text[i])) % MOD results = [] for i in range(n - m + 1): if window_hash == pattern_hash and text[i:i + m] == pattern: results.append(i) if i < n - m: window_hash = (BASE * ((window_hash - ord(text[i]) * h % MOD + MOD) % MOD) + ord(text[i + m])) % MOD return results
What Problems It Solves
Single-pattern search. The obvious use: find all positions where a pattern occurs in a text in O(n + m) expected time. KMP and Boyer-Moore also solve this with O(n + m) guarantees (KMP is worst-case deterministic), so for a single pattern on an adversarial input, KMP is safer. For typical inputs, Rabin-Karp is simpler to implement correctly.
Multiple-pattern search. This is the plot twist. Rabin-Karp looks like a complicated way to do something str.find() already does. Then someone asks you to search for 10,000 patterns at once. KMP needs a fresh automaton per pattern. Boyer-Moore needs separate preprocessing per pattern. Rabin-Karp shrugs: store all pattern hashes in a hash set, then slide one rolling window across the text.

Rabin-Karp multi-pattern search, summarized.
For each window in the text, compute the rolling hash and do a set lookup in O(1). If any pattern matches, verify. The total time is O(n + total pattern length) expected, regardless of how many patterns you have. KMP and Aho-Corasick require preprocessing proportional to the pattern count. Rabin-Karp just extends naturally.

One rolling window. One hash set. Every pattern covered.
Longest repeated substring. Binary search on the length k. For a fixed k, use Rabin-Karp to slide a window of length k over the text and store each window's hash in a set. If any hash appears twice (and verification confirms it), a duplicate of length k exists. Binary search across k gives O(n log n) total. This is LeetCode 1044.
Common substring detection. Do two strings share any substring of length k? Compute rolling hashes for all windows of length k in string 1, store them in a set, then slide over string 2 checking against the set. O(n + m) expected.
2D pattern matching. Hash each row of the text matrix to reduce the 2D problem to a 1D problem on row hashes, then apply Rabin-Karp again on the column direction.
Document fingerprinting. The Rabin fingerprint (Rabin's 1981 paper) extends this idea to arbitrary-length files using polynomials over GF(2). Git and rsync use rolling hashes derived from this idea for efficient deduplication and delta-syncing.
When to Reach for Rabin-Karp
The signal is usually in the problem constraints: a fixed window length, or many patterns. Rabin-Karp problems usually have one of these shapes:
- "Find all starting indices where
patternappears intext." - "Find the longest substring that appears more than once."
- "Given a list of words, find which ones appear in the text."
- "Do these two strings share a substring of length at least k?"
- The substring length is fixed or can be binary-searched, and you need to check many windows.
The distinguishing feature is exact substring matches at scale: either many patterns, or the same window shape tested at many positions. When the problem is fuzzier (approximate matching, subsequences, edit distance), Rabin-Karp does not apply. When it does apply, it is usually the cleanest solution in the room.
Worked Example 1: Repeated DNA Sequences (LeetCode 187)
Problem: Given a DNA string, find all 10-letter sequences that appear more than once.
Why Rabin-Karp fits: The window length is fixed at 10. You need to detect duplicates among n - 9 windows. A rolling hash represents each window as a number in O(1) per step. Store hashes in a set. When a hash appears for the second time, verify the actual substring (length 10, so verification is O(1)). Total: O(n).
def find_repeated_dna_sequences(s: str) -> list[str]: if len(s) <= 10: return [] BASE, MOD, WINDOW = 4, 1_000_000_007, 10 mapping = {'A': 1, 'C': 2, 'G': 3, 'T': 4} h = pow(BASE, WINDOW - 1, MOD) window_hash = 0 for c in s[:WINDOW]: window_hash = (window_hash * BASE + mapping[c]) % MOD seen = {window_hash} result_set = set() for i in range(1, len(s) - WINDOW + 1): left = mapping[s[i - 1]] * h % MOD window_hash = (BASE * ((window_hash - left + MOD) % MOD) + mapping[s[i + WINDOW - 1]]) % MOD if window_hash in seen: candidate = s[i:i + WINDOW] result_set.add(candidate) else: seen.add(window_hash) return list(result_set)
Using a 4-character alphabet (base 4) instead of 256 reduces hash density and makes collisions even rarer. Verification costs O(1) here because the window is always exactly 10 characters.
Worked Example 2: Longest Duplicate Substring (LeetCode 1044)
Problem: Find the longest substring of s that occurs at least twice. s is up to 3 × 10^4 characters.
Why Rabin-Karp fits: Brute force tries all O(n^2) pairs of starting positions for every possible length. That is O(n^3). The key observation: if a duplicate of length k exists, one of length k - 1 also exists (take any prefix). The answer length is monotone, so binary search on k works.
For a fixed k, check whether any duplicate window of length k exists: slide Rabin-Karp across the string, store window hashes in a set, and return True on first repeated hash (after verification). This check costs O(n) expected. Binary search on k from 1 to n - 1 adds a log factor.
Total: O(n log n) expected.
def longest_dup_substring(s: str) -> str: BASE, MOD = 256, (1 << 61) - 1 # Mersenne prime, fewer spurious hits def has_duplicate_of_length(length: int) -> str: if length == 0: return "" h = pow(BASE, length - 1, MOD) window_hash = 0 for c in s[:length]: window_hash = (window_hash * BASE + ord(c)) % MOD seen: dict[int, list[int]] = {window_hash: [0]} for i in range(1, len(s) - length + 1): left = ord(s[i - 1]) * h % MOD window_hash = (BASE * ((window_hash - left + MOD) % MOD) + ord(s[i + length - 1])) % MOD if window_hash in seen: candidate = s[i:i + length] for start in seen[window_hash]: if s[start:start + length] == candidate: return candidate seen.setdefault(window_hash, []).append(i) return "" lo, hi, answer = 1, len(s) - 1, "" while lo <= hi: mid = (lo + hi) // 2 found = has_duplicate_of_length(mid) if found: answer = found lo = mid + 1 else: hi = mid - 1 return answer
This version uses (1 << 61) - 1 as the modulus, a Mersenne prime. It reduces spurious hits further and its modular arithmetic can be optimized with bitwise tricks on 64-bit hardware. If a collision is a correctness bug rather than just a performance hiccup, this is the modulus to reach for.
Spurious Hit vs. True Match

A large prime keeps the right branch dominant. With q = 10^9 + 7, the "NO" path fires 999,999,999 times out of every billion windows on average.
Quick Recap
- Rabin-Karp treats every substring as a polynomial evaluated at
dmoduloq. - The rolling hash formula updates the window hash in O(1): remove leftmost, shift, add rightmost.
- Expected performance is O(n + m). Worst case is O(nm), only under a tiny modulus or adversarial input.
- Space is O(1) for single-pattern search, O(k) to hold k pattern hashes for multi-pattern search.
- The biggest practical pitfall is negative modulo. Add
qbefore the inner modulo in every language except Python and Ruby. - Use two independent hash functions if the input may be adversarial or the cost of a collision is high.
- Rabin-Karp's structural advantage over KMP and Boyer-Moore is the multi-pattern case and the "repeated substring of length k" class of problems.
- For single-pattern search on adversarial inputs, KMP offers a deterministic O(n + m) guarantee without the probability argument.
Recognizing the rolling hash signal under interview pressure is a different skill from implementing it at home. The pattern looks obvious in retrospect. SpaceComplexity runs voice-based DSA mock interviews with rubric-based feedback on communication, problem-solving, and code quality. That's the gap they're built to close.
For related data structure internals, see how hash tables achieve O(1) lookups and why the same collision math governs both. The suffix array is an alternative for offline multi-pattern search that trades the probabilistic argument for a deterministic O(n log n) build and O(m + log n) query. When your "longest duplicate substring" problem has an even stricter time budget, binary search invariants spell out the loop structure that makes the binary search component correct.