Reservoir Sampling: Sample Any Stream Without Seeing Its End
- Reservoir sampling solves uniform random k-item sampling from a stream of unknown length in O(n) time and O(k) space with a single pass.
- Algorithm R fills the first k slots, then accepts each new item at position i with probability k/(i+1) by drawing j uniformly in [0, i] inclusive.
- Correctness follows by induction: after m items each has probability k/m in the reservoir; multiplying by the survival factor m/(m+1) gives k/(m+1) at every step.
- Algorithm L reduces expected random number calls to O(k log(n/k)) by skipping to the next swap position via a geometric-like distribution.
- Weighted reservoir sampling (Efraimidis-Spirakis A-ES 2006) assigns key = U^(1/weight) and maintains a min-heap of size k, achieving O(n log k) time.
- The range bug: generating j in [0, i) instead of [0, i] silently biases the sample from the first element beyond the reservoir.
- Pattern signals: "return random node," O(1) or O(k) space constraint, single-pass or non-rewindable stream, or unknown n all point to reservoir sampling.
You have a data stream. Could be a file you're reading line by line. Could be a live feed of network packets. Could be a database cursor scanning a billion rows you absolutely refuse to load into memory because you've seen what happens when someone tries. You want a random sample of k items. Equal probability for every item. One catch: you don't know how many items are in the stream until you hit the end.
That's the problem. Reservoir sampling solves it in a single pass with O(k) memory, no matter how large the stream turns out to be.
The mental model: fill a bucket with the first k items, then for every new item that arrives, flip a biased coin and maybe swap it in. By the time the stream ends, the bucket holds a perfectly uniform random sample. The whole thing takes about fifteen lines of code. You'll feel like you're missing something. You're not.
Why You Can't Just Generate Random Indices
The obvious approach: if the stream has n items, generate k distinct random indices in [0, n-1], collect those items, done. O(k) space. Clean.
It breaks the moment n is unknown. You can't generate indices into a set whose size you haven't seen yet. You could buffer the entire stream and sample at the end, but that trades O(k) space for O(n) space. Which is fine if n is a hundred items. Less fine if n is a billion log lines and your server has 4GB of RAM. Your laptop becomes a space heater and your ops team becomes very curious about what you're doing.
The core constraint: you must decide whether to include each item in your sample at the moment you see it, using only information you have so far.
Fill First, Swap the Rest
Algorithm R, from Vitter's 1985 paper in ACM Transactions on Mathematical Software, does exactly that.
Fill reservoir with items[0..k-1].
For each item at position i (0-indexed, so i >= k):
Generate a random integer j in [0, i] inclusive.
If j < k:
Replace reservoir[j] with the current item.
Return reservoir.
That is the entire algorithm. Take a second with that. The algorithm running inside BigQuery's approximate aggregates, inside every Kafka-based log sampler, inside the linked list random-node problem you might get asked in a screening tomorrow... fits on a napkin. The non-obvious part is why it's correct.
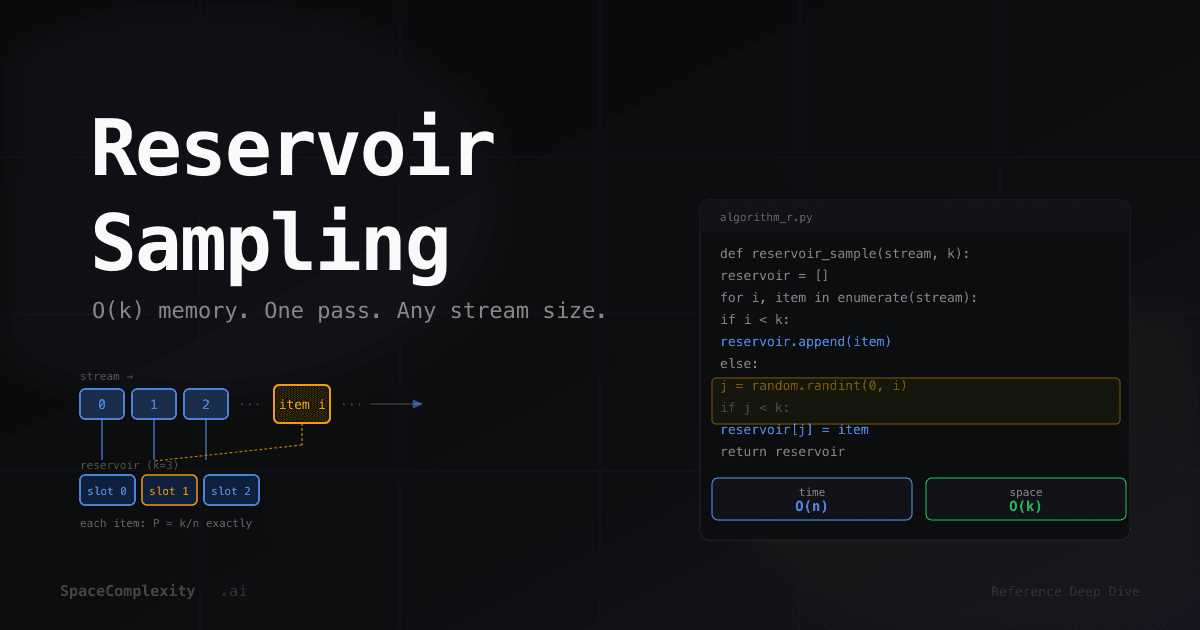
![A stream of items flowing left-to-right into k reservoir slots, showing direct fill for the first k items and a conditional swap for item i with random j drawn from [0, i].](https://assets.spacecomplexity.ai/blog/content-images/reservoir-sampling-algorithm/1779820286490-stream-reservoir.png)
Algorithm R: the first k items fill the reservoir directly. Each subsequent item at position i is accepted with probability k/(i+1), and if accepted, evicts one slot chosen uniformly.
Why the Probability Is Exactly Right
Claim: after processing m items (m >= k), each of those m items is in the reservoir with probability exactly k/m.
Proof by induction. This one is unusually clean, so bear with it.
Base case: m = k. All k items are in the reservoir. Probability k/k = 1. Trivially true.
Inductive step: assume after m items, each is in the reservoir with probability k/m. Now item m+1 arrives (switching to 1-indexed here for clarity).
We generate j uniformly in [1, m+1]. Item m+1 gets accepted when j <= k, so with probability k/(m+1). Good.
Take any existing item already in the reservoir. By the inductive hypothesis it's there with probability k/m. What's the probability it survives this step?
Two ways it survives: item m+1 is not accepted at all (probability (m+1-k)/(m+1)), or item m+1 is accepted but our item is not the one evicted (probability (k/(m+1)) times (k-1)/k).
P(survive) = (m+1-k)/(m+1) + (k-1)/(m+1) = m/(m+1)
So the probability that any existing item is still in the reservoir after m+1 items:
P = (k/m) * (m/(m+1)) = k/(m+1)
Every item, new or old, ends up in the reservoir with probability k/(m+1) after m+1 items. The invariant holds. By induction, after all n items, every item has probability exactly k/n.

The k=1 case traced step by step. Item 1 starts at probability 1, then gets diluted at each step. Every new item enters at exactly the right probability. They all meet at 1/n when the stream ends.
Complexity: What You Pay and Why
| Operation | Time | Space | Notes |
|---|---|---|---|
| Algorithm R (fill + sample) | O(n) | O(k) | One pass, n random number calls |
| Algorithm L (skip-ahead) | O(k + k·log(n/k)) | O(k) | Vitter 1992, far fewer RNG calls |
| k = 1 (single-item case) | O(n) | O(1) | One variable in memory |
| Weighted sampling (A-ES) | O(n log k) | O(k) | Efraimidis-Spirakis 2006, min-heap |
Why O(n) time: you visit each item exactly once. The constant work per item is one random number generation and at most one array write. There is no cheaper algorithm that achieves exact uniform sampling in a single pass: any correct algorithm must at least read every item.
Why O(k) space: the reservoir holds exactly k items. The only other state is the running index and the random number, both O(1). The stream itself is never buffered.
Why Algorithm L is faster in practice: for large n and small k, Algorithm R generates O(n) random numbers. Most result in no action because j >= k most of the time. You're paying the cost of a random number generator call just to throw the result away. Algorithm L computes the next position where a swap happens by sampling from a geometric-like distribution. The expected number of random calls drops to O(k log(n/k)), which is a dramatic improvement when k << n. Vitter showed this is optimal up to a constant factor in the paper Reservoir-sampling algorithms of time complexity O(n(1 + log(N/n))) (1992).

Algorithm R calls the RNG 10 million times for a stream of 10 million items. Algorithm L makes around 1,600 calls. Same result. Neither knows n in advance.
Why the weighted variant costs O(n log k): each item computes a key via U^(1/weight) where U is uniform in (0, 1]. A min-heap of size k holds the current top-k keys. Each arrival that beats the minimum requires a heap replacement costing O(log k). In the worst case all n items enter the heap at some point.
One Structure, Every Language
import random from typing import TypeVar, Iterable T = TypeVar("T") def reservoir_sample(stream: Iterable[T], k: int) -> list[T]: reservoir: list[T] = [] for i, item in enumerate(stream): if i < k: reservoir.append(item) else: j = random.randint(0, i) # inclusive on both ends if j < k: reservoir[j] = item return reservoir
The Problems Reservoir Sampling Is Built For
Reservoir sampling applies whenever you need a uniform random sample and cannot afford to store the full input or make a second pass.
Concrete scenarios where nothing else fits:
Stream of unknown length. You're reading a log file and want 1000 random lines for analysis. You don't know how many lines the file has and don't want to read it twice. Reservoir sampling handles it in one pass.
Memory-constrained environments. A billion-row table with only a few hundred megabytes of working memory. Buffering rows is not an option. Reservoir sampling keeps exactly k rows at any moment. Google BigQuery's approximate aggregate functions internally rely on reservoir-style sketches for exactly this reason: scan once, keep a fixed-size structure, return statistically valid results.
Non-rewindable streams. Network packet sniffers, Kafka topic consumers, and sensor feeds can't be rewound to replay from the start. Reservoir sampling samples them in real time with no buffering.
The k = 1 case is worth spelling out. To pick one item uniformly at random from a stream of unknown length, keep the current candidate and replace it with item i with probability 1/i. After n items, the probability works out to 1/n for every item. This is also how some companies run their candidate review process, but that's a different post.
How to Spot a Reservoir Sampling Problem
The signal is a combination of: uniform random sample, stream of unknown or very large n, and O(k) or O(1) space required.
Pattern cues that show up in problem statements:
- "return a random node" from a linked list or stream
- "pick an index at random" where the target may appear multiple times
- "the list is too large to fit in memory" in the follow-up
- "single pass" or "streaming" stated explicitly
- any problem where you want uniform representation across items you can't count in advance
Example 1: LeetCode 382, Linked List Random Node
Problem: given a singly linked list, return a uniformly random node value. The follow-up: the list is huge, you cannot store it in an array.
The naive approach collects all values then calls random.choice. O(n) space. The follow-up kills it.
Reservoir sampling with k = 1 keeps one integer in memory regardless of list length.
class Solution: def __init__(self, head): self.head = head def getRandom(self) -> int: result = -1 node = self.head i = 1 while node: if random.randint(1, i) == 1: # accept with probability 1/i result = node.val node = node.next i += 1 return result
After visiting all n nodes, each had probability 1/n of being the final result. The linked list structure is irrelevant because reservoir sampling needs only sequential access, not random access.

Six nodes, one pass. The result variable updates twice here: at node 1 (always accepted) and at node 3 (accepted with probability 1/3). Every node had an equal shot.
Example 2: LeetCode 398, Random Pick Index
Problem: given an integer array with possible duplicates, for a given target, return a uniformly random index where nums[index] == target.
Precomputing a map from value to list of indices is O(n) space and the problem constrains you away from it in the follow-up.
Use reservoir sampling where the "stream" is only the indices where the value matches the target.
class Solution: def __init__(self, nums: list[int]): self.nums = nums def pick(self, target: int) -> int: result = -1 count = 0 for i, num in enumerate(self.nums): if num == target: count += 1 if random.randint(1, count) == 1: result = i return result
When there are m occurrences of target, each is the current result with probability 1/m after all indices are processed. Each pick call is O(n) time, O(1) space.
One Subtle Bug That Breaks Everything
The most common implementation error is using the wrong random integer range, producing a non-uniform sample that looks correct.
If you generate j in [0, i) instead of [0, i] (exclusive upper bound), item i gets accepted with probability k/i rather than k/(i+1). The math breaks from the first element beyond the reservoir. The bug is quiet. The sample won't crash. The probabilities will be subtly wrong, the distribution will look plausible, and you won't notice until someone runs a chi-squared test on the output of a trillion-item stream. At that point it's probably someone else's problem. But it was yours first.
Every language has its own convention, and they are all slightly different on purpose to keep things interesting:
- Python:
random.randint(0, i)is inclusive on both ends, returns [0, i]. Correct. - JavaScript:
Math.floor(Math.random() * (i + 1))returns [0, i]. Correct. - Java:
random.nextInt(i + 1)returns [0, i). Wait:nextInt(n)returns [0, n-1], sonextInt(i + 1)returns [0, i]. Correct. - C#:
random.Next(0, i + 1)is [inclusive, exclusive), so returns [0, i]. Correct. - Rust:
rng.gen_range(0..=i)is inclusive, returns [0, i]. Correct.
For k = 1, the acceptance condition j == 0 or j == 1 (depending on your indexing) must fire with probability 1/(i+1) or 1/i respectively. Getting this wrong means item 0 or item 1 is always selected.
When Items Have Weights
Uniform sampling assumes all items deserve equal representation. They often don't. A log line from a critical payment service carries more signal than your load balancer's thousandth health check ping. You want to oversample the important stuff.
The Efraimidis-Spirakis A-ES algorithm (2006) solves this. Assign each item a key: key = random() ^ (1 / weight). Maintain a min-heap of size k keyed by these values. When item i arrives, compute its key; if it exceeds the heap minimum, pop the minimum and push the new item.
The log transform simplifies computation: key = log(random()) / weight. Since log is monotone, the ordering is preserved and you avoid computing fractional powers.
Total time is O(n log k). Space is O(k). The proof runs through order statistics of the exponential distribution.
Recap
- Problem: uniform random sample of k items from a stream of unknown or huge length n, with O(k) memory and one pass.
- Algorithm R: fill the reservoir with the first k items, then for each item at position i, generate j in [0, i] and replace reservoir[j] if j < k.
- Correctness: by induction. After m items, each is in the reservoir with probability k/m. The product (k/m) times (m/(m+1)) equals k/(m+1), preserving the invariant at every step.
- Time: O(n) for Algorithm R. Algorithm L reduces expected random number calls to O(k log(n/k)) using skip counts.
- Space: O(k), exactly the reservoir. The stream is never stored.
- Edge case: if the stream has fewer than k items, the reservoir contains all of them. No special-casing needed; the fill branch handles it.
- Range bug: generating j in [0, i) instead of [0, i] produces a biased sample. Verify your language's inclusive/exclusive semantics.
- Weighted variant: Efraimidis-Spirakis A-ES uses key = U^(1/weight) with a min-heap of size k. O(n log k) time.
- Pattern signals: "random node/index," unknown or huge n, O(k) or O(1) space constraint, single-pass or non-rewindable stream.
Reservoir sampling comes up regularly in SpaceComplexity mock interviews. It shows up in linked list and streaming problems, and it rewards candidates who can derive the invariant on the spot rather than recite it. The platform runs voice-based DSA interviews with rubric feedback if you want to practice that kind of reasoning out loud.
The problems in this article pair naturally with the patterns in linked list interview questions. And if you want to implement the weighted variant using a min-heap, the heap data structure deep dive is the right foundation.