Ride-Sharing System Design Interview: Two Stores, 500K Writes, One Race Condition
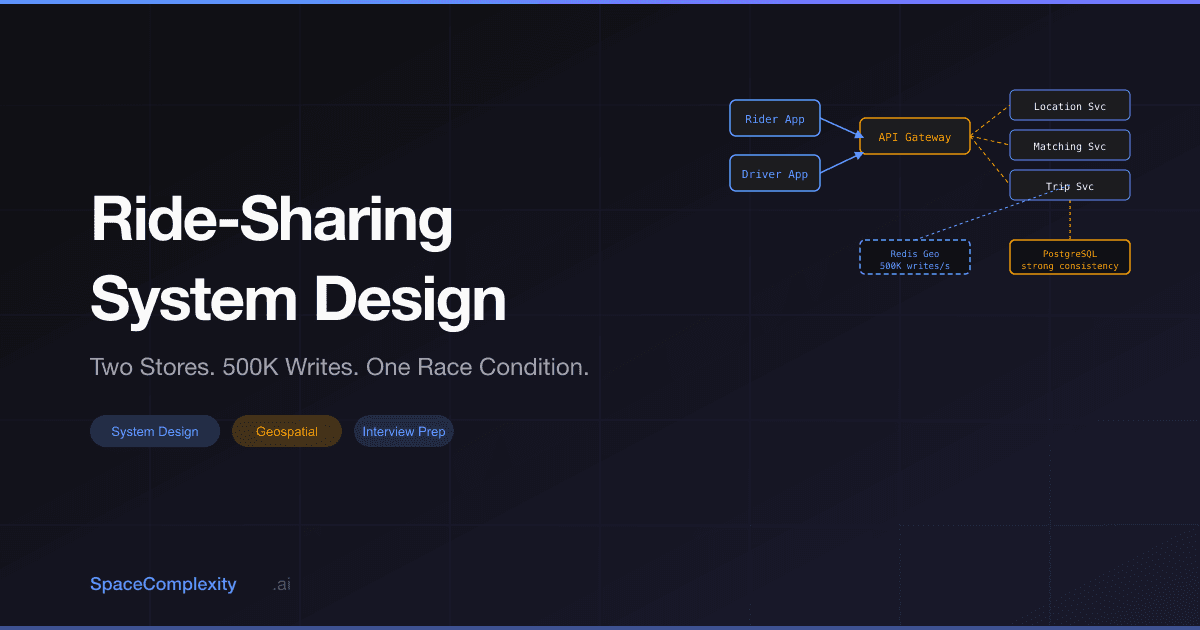
- Two stores keep the system coherent: PostgreSQL for trips (ACID, strong consistency) and Redis for live driver positions (in-memory, TTL-managed)
- 500,000 location writes per second rules out any relational database for live driver data; back-of-envelope is the first decision gate
- H3 hexagonal cells give six equidistant neighbors for spatial queries; Redis
GEORADIUSis the interview-ready shorthand - Optimistic locking on a
versioncolumn prevents double-assignment when two riders grab the same driver simultaneously, no distributed lock required - The trip state machine (REQUESTED to SEARCHING to MATCHED to IN_TRIP to COMPLETED) means every transition is a database write and invalid transitions are rejected
- Match by ETA, not distance: a driver 800m away across a river is slower than one 1.2km away on the same road
- WebSocket, not HTTP polling, for real-time driver location; 2 million open polling connections is not a viable architecture
You're in a system design interview. The prompt lands: "Design Uber." You nod confidently. You draw a box labeled "Backend." You put a database underneath it. You say "microservices" three times like it's a magic spell. You don't get the offer.
The interviewer wanted to see you identify the hard part. The hard part is not "which cloud provider." It's knowing why you need two completely separate databases, why hexagons beat squares, and how to stop two riders from stealing the same driver without a distributed lock service.
This post walks through all of it.
Scope It Before You Draw a Single Box
Interviewers want to see you constrain the problem before you start architecting. Spend the first two to three minutes here. Functional scope for this session:
- Rider: request a ride, track driver location, complete payment
- Driver: go online, accept/reject, navigate to pickup, complete trip
- Out of scope: fraud detection, driver onboarding, scheduled rides, carpooling
Non-functional requirements are where you show real judgment. Matching latency under 5 seconds is the headline constraint. Location accuracy within 10 meters. 99.99% availability. Eventual consistency for driver positions is fine. Strong consistency for trip assignment is not negotiable.
Run the Numbers First. They Decide Everything.
Back-of-envelope estimation isn't a formality. It's a decision gate.
- ~5 million rides per day, roughly 60 per second at peak
- ~2 million drivers online at peak
- Drivers send a GPS update every 4 seconds
- That's 500,000 location writes per second
That one number invalidates half the architectures a candidate might propose. No relational database handles 500K writes per second without some very creative lying in your resume. You need an in-memory store for live driver positions, completely separate from your transactional database. Every candidate who routes everything through one PostgreSQL instance is wrong by the math, not by opinion.
High-Level Architecture: Three Planes

Three planes, one coherent system. The tricky part is knowing which store goes where.
The system has three conceptual planes.
Communication plane. Both apps maintain a persistent WebSocket connection to a Connection Service. This is not optional. HTTP polling from 2 million drivers would generate tens of thousands of requests per second just to check for notifications. WebSocket pushes only when there is something to say.
Location plane. The Location Service receives every driver GPS ping, writes it to Redis with a 30-second TTL, and drops it onto a Kafka topic. Kafka buffers bursts and lets matching workers catch up without dropping updates. When a driver goes offline or their app crashes, the Redis entry expires on its own. No cleanup job, no state to synchronize.
Trip plane. The Trip Service owns the state machine and writes to PostgreSQL. This is the only component that demands ACID guarantees. Strong consistency where it matters, nowhere else.
The Hard Part: Geospatial Indexing
Most candidates say "find drivers near the pickup" and leave it there. They've described what the feature does, not how it works. That's not architecture.
The naive version: store every driver's lat/lng and run a bounding-box query. At 2 million drivers that scans millions of rows on every request. It does not scale.
The correct version: partition the earth into cells, index drivers by cell, then query adjacent cells at pickup time.
Uber's production system uses H3, their open-source hexagonal hierarchical grid. The earth is divided into hex cells at configurable resolution. Resolution level 9 gives cells of roughly 0.1 km², which is right for urban matching. Each driver record carries their H3 cell index. Finding nearby drivers means querying the home cell plus its six immediate neighbors.

Query the center cell plus six neighbors. That's your entire driver candidate set. No table scans.
Why hexagons over squares? A square's diagonal neighbor is 1.41x farther than its cardinal neighbor, so distance calculations are inconsistent across directions. A hexagon has exactly six equidistant neighbors. The math is cleaner and the spatial aggregations (like surge pricing heatmaps) don't have seam artifacts at cell boundaries.
For the interview, you don't need to memorize H3. Redis GEOADD and GEORADIUS implement the same idea using geohash encoding and are perfectly valid to describe. Mentioning both shows you know the production tool and the interview-friendly shorthand.
# Store an active driver redis.geoadd("drivers:online", longitude, latitude, driver_id) redis.expire(f"driver:status:{driver_id}", 30) # Find drivers within 5 km of the pickup point candidates = redis.georadius( "drivers:online", pickup_lng, pickup_lat, 5, unit="km", count=20, sort="ASC" )
O(1) for the geo lookup, O(k log k) to sort k candidates by ETA. The hash map internals make the per-driver lookup constant regardless of fleet size.
The Trip Is a State Machine

Every forward arrow is a database write. The race condition lives exactly at the MATCHED transition, which is also why we need the version column.
A trip moves through a fixed sequence of states. Every transition is a database write, and invalid transitions are rejected. This is what keeps you from billing a rider for a trip that was cancelled, or starting a trip that was never matched.
The dangerous edge case: two riders requesting the same driver simultaneously. Both queries hit Redis, both see the driver as available, and both try to write MATCHED. Without coordination, both could succeed. You'd have one driver and two very confused riders.
Optimistic locking on a version column solves this without any distributed lock service. No Zookeeper. No Redis SETNX. Just one extra integer column.
UPDATE trips SET status = 'MATCHED', driver_id = $1, version = version + 1 WHERE id = $2 AND status = 'SEARCHING' AND version = $3;
If the version has already incremented, zero rows are updated. The second request detects this, re-runs the driver search, and finds the next available driver. No double-assignment, no coordination overhead. The database's built-in compare-and-swap does all the work.
Data Model
Two stores. Two roles. One each.

PostgreSQL for what needs to survive forever. Redis for what needs to be fast and is fine disappearing after 30 seconds.
PostgreSQL owns users, drivers, and trips. The trips table is the source of truth for the state machine.
CREATE TABLE trips ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), rider_id UUID NOT NULL REFERENCES users(id), driver_id UUID REFERENCES drivers(id), status TEXT NOT NULL, pickup_lat DOUBLE PRECISION NOT NULL, pickup_lng DOUBLE PRECISION NOT NULL, dropoff_lat DOUBLE PRECISION, dropoff_lng DOUBLE PRECISION, fare_cents INTEGER, surge NUMERIC(4, 2) DEFAULT 1.0, version INTEGER NOT NULL DEFAULT 0, created_at TIMESTAMPTZ NOT NULL DEFAULT NOW() );
Redis owns live driver positions and availability status only. The geo sorted set holds positions. A separate hash holds driver state (AVAILABLE, ON_TRIP, OFFLINE), with a 30-second TTL on both.
Cassandra is worth a mention if the interviewer probes historical data. Raw GPS tracks are write-heavy append-only time-series that Cassandra handles better than PostgreSQL. This data arrives async via Kafka and is never in the critical path for matching or trip assignment.
API Design
Keep it narrow. Three REST endpoints cover the rider flow.
POST /rides # rider requests, returns trip ID
GET /rides/{id} # poll current status and driver position
PATCH /rides/{id}/status # driver: accepts, arrives, completes
Driver location updates do not go through REST. They travel upstream on the WebSocket connection as compact JSON payloads. Pulling them through HTTP would add round-trip overhead on every 4-second update from every driver on the planet.
{ "type": "location_update", "lat": 37.774, "lng": -122.419, "heading": 270 }
Three Scaling Bottlenecks
The interviewer will probe all three. Have answers ready.

Each worker owns a region. No cross-shard coordination. Scale by adding workers, not by praying.
Location writes at 500K/sec. Redis Cluster shards the geo key by city or H3 super-cell. Each shard owns a geographic region so driver updates stay local. No cross-shard coordination for a typical search.
Matching throughput. The Matching Service is stateless. Add workers reading from partitioned Kafka topics, each handling one region. The heap-based priority queue inside each worker ranks candidates by ETA in O(k log k) without shared state.
Trip database hotspots. Partition the trips table by created_at. The current month's partition is hot. Older partitions serve archive reads from replicas. Write throughput stays bounded by concurrent rides, not total trip history.
Three Tradeoffs Worth Raising Unprompted
Naming tradeoffs before the interviewer asks is the difference between a strong hire and a borderline pass.
Push vs. pull for driver location. Drivers push every 4 seconds. The server could poll instead, but push gives fresher data and avoids managing millions of polling connections. The full push vs. pull tradeoff analysis applies directly here. Bring it up before they ask.
Eventual consistency for location vs. strong consistency for trips. Driver positions being 4 seconds stale is fine. A driver doesn't teleport. But two riders matching the same driver is a hard business error that breaks payments, routing, and trust. The version column buys you strong consistency exactly where you need it. Nowhere else.
Distance vs. ETA for matching. Straight-line distance is wrong in practice. A driver 800 meters away across a river is slower than one 1.2 km away on the same road. Ranking by true ETA via a routing API is one sentence that separates you from the drawing-boxes crowd.
How to Run a Ride-Sharing System Design Interview in 45 Minutes
A system design interview is 45 minutes. Spend it deliberately. - Minutes 1-5: requirements and non-functionals, confirm scope
- Minutes 5-10: back-of-envelope (the 500K writes/second number is your pivot)
- Minutes 10-25: high-level architecture, then geospatial deep-dive
- Minutes 25-35: data model, state machine, API sketch
- Minutes 35-45: bottlenecks, tradeoffs, questions back to the interviewer
Do not draw boxes before you have identified the hard problem. For this system, the hard problem is the geospatial index and the two-store split. Everything else is plumbing. Name that insight by minute 15 and the interviewer knows you understand the system, not just what it looks like in a diagram.
Quick Recap
- Two stores: PostgreSQL for trips (strong consistency, ACID), Redis geo for driver positions (speed, TTL, eventual consistency)
- 500K writes/second from GPS pings means no SQL for live locations
- H3 hexagonal cells give uniform neighbor distances; Redis
GEORADIUSis the interview shorthand - Optimistic locking on
versionprevents double-assignment without distributed locks - State machine: every transition is a write; invalid transitions are rejected
- WebSocket, not polling, for bidirectional real-time communication
- Match by ETA, not distance
If you want to practice walking through this out loud and get rubric-based feedback on where you stalled, rushed, or over-explained, SpaceComplexity runs voice-based system design mock interviews with structured scoring. Knowing the architecture is half the problem. Communicating it coherently in 45 minutes is the other half.