Singly vs Doubly Linked List: One Pointer Changes Everything
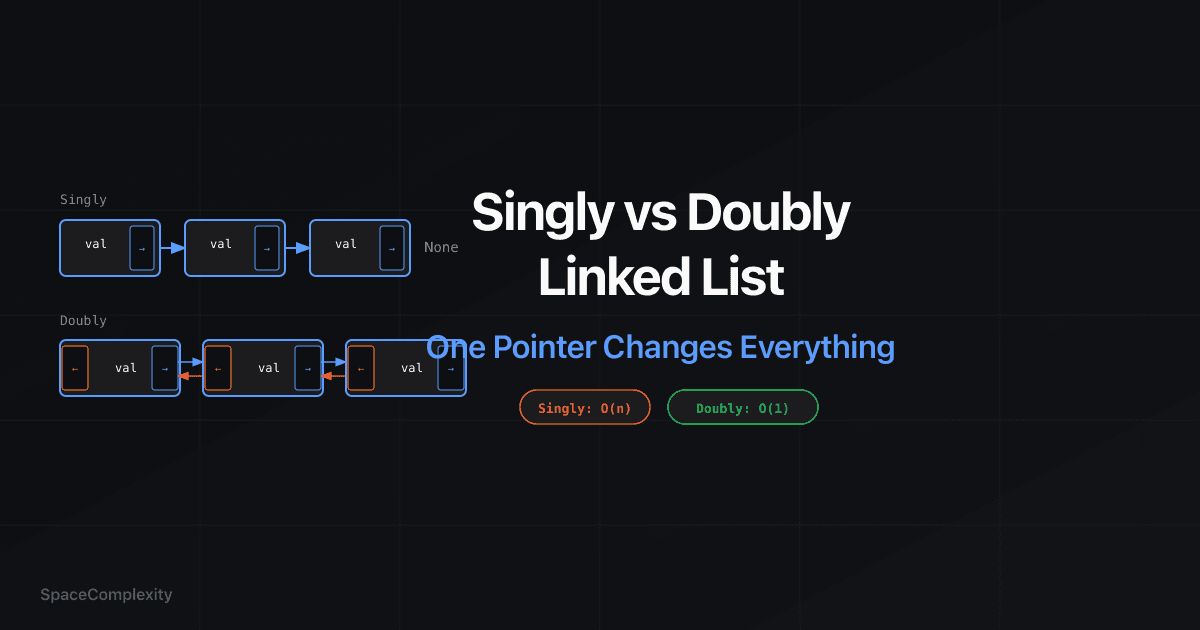
- Singly linked list traverses forward only; deleting a node you hold a direct pointer to costs O(n) because there is no back-pointer to the predecessor
- Doubly linked list stores a
prevpointer per node, making deletion from any arbitrary position O(1) in constant time - Tail deletion is O(n) in a singly list even with a maintained tail pointer; doubly makes it O(1) via
tail.prev - Memory overhead is 8 bytes per node (one extra pointer on 64-bit), a 50% increase over singly list node storage
- Sentinel nodes (dummy head and tail) eliminate all null-check edge cases and make insert and remove identical code paths regardless of list state
- LRU cache, Python's
collections.deque, and Linux's kernellist_headall depend on the doubly linked list's O(1) arbitrary deletion
You're implementing an LRU cache. O(1) get. O(1) put. Your interviewer is nodding along. The hash map handles lookup. The linked list tracks eviction order. You sketch the structure and feel good about it.
Then you realize: when you access a cached item, you need to move it to the front of the list. You have a direct pointer to that node from the hash map. Moving it means removing it first. This is the singly linked list vs doubly linked list tradeoff at its sharpest: in a singly linked list, removing a node you're pointing at costs O(n). You need the predecessor node, and the only way to find it is to walk from the head.
One extra pointer per node is the difference between O(1) and O(n) for that operation. That pointer is the structural distinction between a singly linked list and a doubly linked list. Everything else follows from it.

Every linked list problem, every time.
Two Designs, One Extra Pointer
A singly linked list node stores a value and a pointer to the next node.
class SNode: def __init__(self, val): self.val = val self.next = None
Nodes form a one-way chain:
[val | next] --> [val | next] --> [val | next] --> None
A doubly linked list node stores a value plus pointers in both directions.
class DNode: def __init__(self, val): self.val = val self.prev = None self.next = None
None <-- [prev | val | next] <--> [prev | val | next] <--> [prev | val | next] --> None
The prev pointer is the only structural difference. The heap allocation, the O(n) search, the pointer chasing that defeats the hardware prefetcher: all identical between the two variants.

Eight bytes. That's it. Eight bytes per node is the whole argument.
The Operation That Splits Singly and Doubly Linked Lists
Every operation that touches only the head of the list runs in O(1) for both variants. Insert at head, delete the head, peek the front. No traversal needed.
The split happens the moment you have a pointer to a node in the middle of the list and need to delete it.
In a doubly linked list, deleting node C given a direct pointer to it takes four pointer rewires:
def remove(node): node.prev.next = node.next if node.next: node.next.prev = node.prev
Two writes. No traversal. O(1) regardless of list length. The prev pointer gives you the predecessor immediately.
In a singly linked list, there is no node.prev. To unlink C, you must find the node before it first. The only way to do that is walk from the head until you hit the node whose .next equals C. That is O(n). You have a direct pointer to the node you want to remove, and you still can't use it. It's like knowing exactly which car you want to leave the parking lot but having to circle the entire structure first because there's no exit from your floor.
There is one partial workaround. If the target node is not the tail, you can copy the next node's value into the current node, then skip the next node:
def delete_node_trick(node): # Works only when node is not the last node node.val = node.next.val node.next = node.next.next
This is the trick behind LeetCode 237. It is O(1) and it works. But it is fragile: it fails for tail nodes, invalidates external pointers to the "next" node (which is now effectively gone), and changes node identity. Any code that cached a pointer to the next node now points at stale data. It is a clever interview hack, not a design pattern.
If your structure requires O(1) deletion from an arbitrary mid-list position, a doubly linked list is the only clean choice.

Left: walk the whole list to delete one node. Right: use the pointer you already have.
Every Operation, Side by Side
| Operation | Singly | Doubly |
|---|---|---|
| Insert at head | O(1) | O(1) |
| Insert at tail (tail pointer maintained) | O(1) | O(1) |
| Delete head | O(1) | O(1) |
| Delete tail (tail pointer maintained) | O(n) | O(1) |
| Delete given a direct node pointer | O(n) | O(1) |
| Search by value | O(n) | O(n) |
| Forward traversal | O(n) | O(n) |
| Reverse traversal | Not possible | O(n) |
| Space per node | data + 1 pointer | data + 2 pointers |
The tail deletion row catches people off guard. Even if you maintain a tail pointer so you can locate the tail in O(1), deleting it still requires setting the second-to-last node's .next to None. In a singly linked list, finding that second-to-last node is a full O(n) walk. In a doubly linked list, tail.prev hands it to you instantly.
This is why deques, double-ended queues that need O(1) push and pop from both ends, are always built on doubly linked lists. The singly variant cannot deliver O(1) at the tail without reconstructing the predecessor link.
Every Node Pays Eight Bytes Extra
On a 64-bit system each pointer is 8 bytes. A singly linked list node holding a 4-byte integer packs to 16 bytes: 4 bytes of data, 4 bytes of alignment padding, 8 bytes for next. A doubly linked list node for the same integer reaches 24 bytes by adding the 8-byte prev pointer.
That is a 50% increase in per-node pointer storage.
For a million integers:
| Structure | Approximate memory |
|---|---|
| Plain array | 4 MB |
| Singly linked list | ~16 MB |
| Doubly linked list | ~24 MB |
Both linked variants look bad against the array. Comparing them against each other, the doubly list pays a 50% premium over singly purely for that backwards pointer. In embedded systems with tens of kilobytes of RAM, that 8 bytes per node matters. Across 10,000 nodes it is 80KB of extra memory for a single backwards pointer field. In a cloud service with millions of items in memory, you're buying a lot of AWS instances for a field you might not need.
If you only traverse forward and never need in-place deletion from the middle, the singly linked list is the more honest choice.

The array is quietly judging everyone in this diagram.
Sentinel Nodes Remove All the Edge Cases
Both variants get messy when the list is empty, or when you insert and delete at the boundary. An empty list has no head. A single-element list has a head that is also the tail. Every operation needs null checks.
Sentinel nodes solve this with two dummy nodes that always exist and never hold real data.
class DoublyLinkedList: def __init__(self): self.head = DNode(0) # dummy head self.tail = DNode(0) # dummy tail self.head.next = self.tail self.tail.prev = self.head def insert_after_head(self, node): node.next = self.head.next node.prev = self.head self.head.next.prev = node self.head.next = node def remove(self, node): node.prev.next = node.next node.next.prev = node.prev
With sentinels, every real node always has non-null prev and next neighbors. The list is structurally never empty. There are no special cases for the first insertion, the last deletion, or operations at either end.
The sentinel pattern is standard in LRU cache implementations because it makes insert_after_head and remove identical code paths regardless of list state. The dummy head represents "most recently used" and the dummy tail represents "least recently used." Moving a cache entry to the front is remove(node) followed by insert_after_head(node), each O(1), with no branch on list length. See the full LRU cache walkthrough at /blog/lru-cache-implementation.

The sentinels are the two nodes at the ends that do nothing but save you from writing six if-statements.
Production Code That Depends on This
Linux kernel process lists. The kernel's list_head struct is two pointers, prev and next, embedded directly inside whatever data structure needs linking. The process descriptor task_struct embeds multiple list_head fields: one for the global task list, one for the parent's list of children, one for the scheduler's run queue. Every list_add() and list_del() runs in O(1). The kernel's own documentation notes that linked lists are not the right default choice due to poor cache locality, but O(1) deletion from arbitrary positions is non-negotiable for process scheduling, and doubly linked lists are the only structure that delivers it.
Python's collections.deque. CPython implements deque as a doubly linked list of fixed-size blocks, 64 elements per block as of CPython 3.6. Each block is linked to its neighbors via prev and next pointers. This gives O(1) appendleft and popleft alongside O(1) append and pop. The block-based design reduces memory overhead and improves cache locality compared to one-node-per-element doubly lists. The doubly structure is what makes the left-end operations O(1).
Undo and redo. Text editors maintain a history list where each edit is a node. Undo steps backward through the list. Redo steps forward. Bidirectional traversal with O(1) step is exactly what a doubly linked list provides. A singly list could handle undo with a stack, but redo would require a second parallel structure. Nobody is shipping a text editor that can undo but not redo.
The pattern across all three cases is the same: O(1) access or deletion at an arbitrary known position, not just the head.
Which One Do You Reach For?
Use a singly linked list when you traverse forward only, never need to delete a node you're pointing at mid-list, or memory is genuinely constrained. Log streaming, simple stacks, forward-only pipelines, and functional-style recursive algorithms are natural fits.
Use a doubly linked list when you need O(1) deletion from an arbitrary position, bidirectional traversal, or O(1) operations at both ends. LRU caches, OS schedulers, memory allocators, browser history, and deques all fall here.
When the problem gives you a direct node pointer and asks you to delete it, reach for the doubly linked list.
One more option exists for the memory-extreme case. An XOR linked list, a concept from Knuth's 1968 TAOCP, stores a single pointer per node as prev XOR next. Traversal in either direction is possible by XOR-ing the address you came from against the stored value to recover the next pointer. You get doubly linked list traversal with singly linked list storage. The catch: garbage collectors cannot trace XOR'd pointers, so it only works with manual memory management. It comes up in interviews occasionally as a trivia question. You would not find it in production Python or Java code, because the answer to "why not" is "the garbage collector will eat your nodes."
The Short Version
- Singly: one pointer per node, forward traversal only, O(n) to delete a given node from mid-list.
- Doubly: two pointers per node, bidirectional traversal, O(1) to delete a given node from any position.
- The deciding operation: deletion given a direct node pointer. Singly is O(n). Doubly is O(1).
- Doubly nodes carry 50% more pointer overhead than singly nodes on 64-bit systems.
- Tail deletion is O(n) in singly even with a maintained tail pointer.
- Sentinel head and tail nodes eliminate all null-check edge cases in doubly list code.
- Linux
list_head, Pythoncollections.deque, and every LRU cache implementation depend on the doubly linked list's O(1) arbitrary deletion. - For deeper coverage of the doubly linked list operations and implementations, see /blog/doubly-linked-list.
- For the classic linked list interview problems and where cycle detection and reversal fit in, see /blog/linked-list-interview-questions.
If you want to practice explaining tradeoffs like this one out loud, SpaceComplexity runs voice-based DSA mock interviews with rubric-based scoring. Knowing that a doubly linked list is required for O(1) arbitrary deletion is one thing. Saying it clearly under pressure, before you write a single line of code, is the skill that actually gets scored.