Sqrt Decomposition: Split Into √n Blocks, Answer in O(√n)
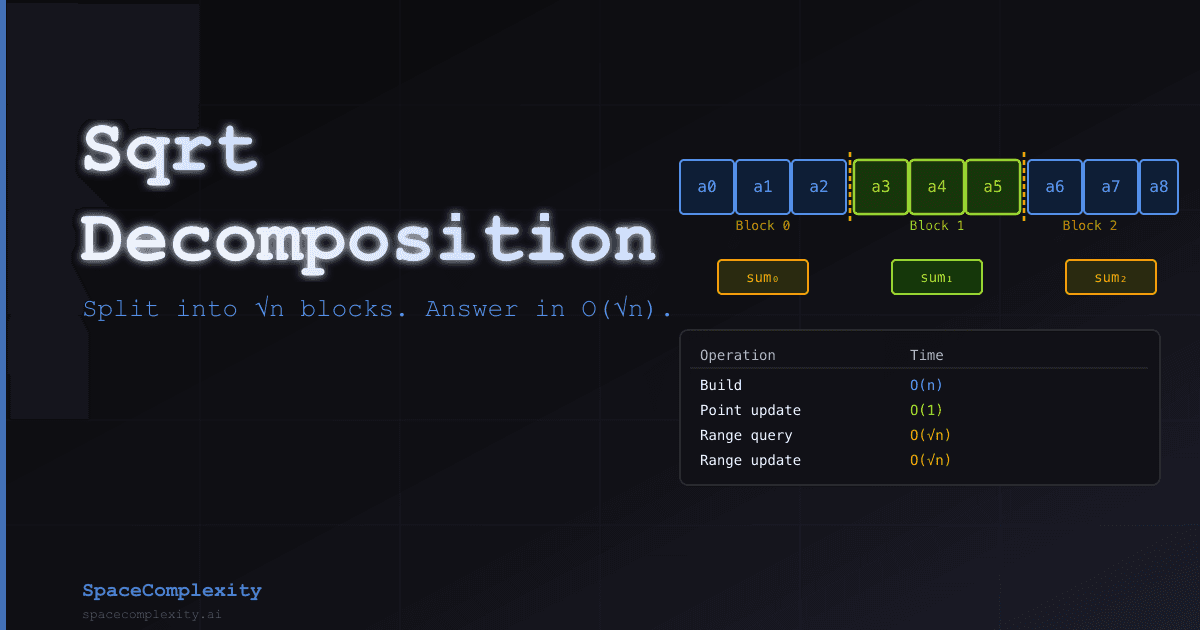
- Sqrt decomposition groups an array into √n blocks, giving O(√n) range queries and point updates in roughly 30 lines of code
- Block size √n is optimal by AM-GM: minimizing k + n/k sets k = √n, making both terms equal
- Range query sums two partial blocks (O(k) each) plus precomputed full block aggregates (O(1) each), totaling O(√n)
- Mo's algorithm applies the same block structure to offline queries, sorting by block of left endpoint then right endpoint for O((n+q)√n) total
- Same-block guard (
lb == rb) is mandatory: without it the partial-block traversals overlap and double-count - Prefer sqrt decomp over segment trees when the aggregate is non-invertible (mode, distinct count) or you need Mo's query reordering
You have an array of a million numbers. Someone asks for the sum of elements 3 through 847,293. Then they update element 12,000. Then they ask about elements 500,000 through 999,999. Repeat, ten thousand times. You work for a data warehouse. Everyone is very enthusiastic.
The naive approach is O(n) per query. That is fine if your users enjoy waiting. A Fenwick tree or segment tree gets you O(log n). Both require significantly more code, with indexing bugs that are easy to introduce under pressure. Square root decomposition gets you O(√n) per operation with maybe 30 lines of code, and the insight is clean enough that you can derive it from scratch in a whiteboard interview.
The mental model: group the array into blocks of size ~√n, precompute the aggregate for each block, and answer queries by summing whole blocks plus the two ragged ends.
Why √n? There's Actually a Proof
Say you split the array into blocks of size k. For a range query [l, r]:
- You walk through at most k elements in the left partial block
- You walk through at most k elements in the right partial block
- You sum at most n/k complete blocks
Total cost per query: O(k + n/k).
Now minimize k + n/k over k > 0. By AM-GM, k + n/k ≥ 2√(k · n/k) = 2√n, with equality exactly when k = n/k, meaning k = √n.
Set the block size to √n and every term in the cost expression becomes √n, giving O(√n) per query. Any other block size makes one of the two terms bigger.
The block size √n is the optimum by proof. The technique is named for that math, which is unusually honest for computer science.
 Two competing costs. One goes up with k. One goes down. They meet exactly at √n.
Two competing costs. One goes up with k. One goes down. They meet exactly at √n.
How Sqrt Decomposition Works Internally
Memory layout
Original array: [a0, a1, a2, ..., a(n-1)]
Block size k = ⌊√n⌋
Block 0 Block 1 Block 2 ... Block ⌈n/k⌉-1
[a0..a(k-1)] [ak..a(2k-1)] [a2k..a(3k-1)] ... [remaining]
blocks[]: [sum₀, sum₁, sum₂, ..., sum_last]
The blocks[] array has ⌈n/k⌉ ≈ √n entries. Total extra space is O(√n).
 The blocks[] array sits below the original. ⌈n/k⌉ entries. Everything else stays where it was.
The blocks[] array sits below the original. ⌈n/k⌉ entries. Everything else stays where it was.
Building the structure
Walk the array once. For each element, add it to both the element position and its block's aggregate. Build time is O(n).
for i in range(n):
blocks[i // k] += arr[i]
Answering a range query
A query [l, r] splits into three zones: the partial block at the left end, any complete blocks in the middle, and the partial block at the right end.
Example: n=16, k=4, query [2, 13]
Array: [a0 a1 | a2 a3 | a4 a5 a6 a7 | a8 a9 a10 a11 | a12 a13 a14 a15]
Blocks: B0 B1 B2 B3
lb = 2 // 4 = 0 (block containing left endpoint)
rb = 13 // 4 = 3 (block containing right endpoint)
Left partial: a2, a3 (from l=2 to end of block 0)
Full blocks: B1 (a4..a7), B2 (a8..a11)
Right partial: a12, a13
The key invariant: the left partial block and right partial block each contain fewer than k elements, so each takes O(k) = O(√n) time. The full blocks in between are each answered in O(1) via their precomputed sums.
![Range query [l=2, r=13] on 16-element array: amber left partial, blue full blocks, green right partial](https://assets.spacecomplexity.ai/blog/content-images/sqrt-decomposition-algorithm/1779844640563-query-zones.png) Three zones, three colors. The blue ones are free. The amber and green cost O(k) each.
Three zones, three colors. The blue ones are free. The amber and green cost O(k) each.
What Each Operation Costs
| Operation | Time | Space | Notes |
|---|---|---|---|
| Build | O(n) | O(√n) | One pass; block array has ⌈n/√n⌉ entries |
| Point query | O(1) | O(1) | Direct array access |
| Point update | O(1) | O(1) | Update element + its block aggregate |
| Range query | O(√n) | O(1) | Two partial blocks + full blocks |
| Range update | O(√n) | O(1) | Partial blocks element-by-element; full blocks lazily |
| Range update + range query | O(√n) | O(√n) | Requires lazy block additions |
Why point update is O(1)
An element belongs to exactly one block. Updating element i means touching exactly two locations. That is it.
arr[i] += delta
blocks[i / block_size] += delta
![Point update on index 6: writes to arr[6] and blocks[1], everything else untouched](https://assets.spacecomplexity.ai/blog/content-images/sqrt-decomposition-algorithm/1779844640906-update-operation.png) Two writes. Two. The rest of the array does not care.
Two writes. Two. The rest of the array does not care.
Why range update works lazily
Say you want to add v to every element in [l, r]. There are three kinds of blocks involved:
- Left partial block: The query starts in the middle. Walk through elements l to (end of that block), add v to each. O(k) operations.
- Full blocks: Every element in these blocks gets v added. Instead of touching each element, store
lazy[b] += v. One write per block. At most n/k = √n blocks. O(√n) total. - Right partial block: Same as left partial. O(k) operations.
When you later query a range that includes partial elements from a lazily-updated block, you add lazy[b] to each element you touch from that block. This is O(1) per element, so the query complexity stays O(√n).
The full range-update, range-query variant stores two values per block: the precomputed block sum and the pending lazy addition. A range query adds lazy[b] * (block elements in range) for full blocks. "Lazy" is an accurate description. You are deferring work until someone actually asks for it.
Why Mo's algorithm is O((n + q)√n)
Mo's algorithm is a different beast. It answers offline range queries (all queries known in advance, no updates) by reordering them to minimize the total distance the window boundaries travel.
Divide query left-endpoints into blocks of size √n. Sort queries: first by which block the left endpoint falls in, then by right endpoint within each block (alternating ascending/descending on adjacent blocks for a small constant improvement).
Now process queries in order, maintaining a sliding window [curL, curR] by expanding or contracting one element at a time.
Why is this fast?
- Right pointer movement: Within each block, the right pointer is monotone (sorted by R). It travels at most n positions across all queries in a block. With ⌈n/√n⌉ = √n blocks, total right pointer movement is O(n√n).
- Left pointer movement: Within each block, the left pointer only moves within a range of √n positions per query. With q queries, total left pointer movement is O(q√n).
Total: O((n + q)√n). For q ≈ n, this is O(n√n).
 Sort by block of L, zigzag by R. The R pointer never has to reset all the way to zero at block boundaries.
Sort by block of L, zigzag by R. The R pointer never has to reset all the way to zero at block boundaries.
One Structure, Every Language
import math class SqrtDecomposition: def __init__(self, arr: list[int]) -> None: n = len(arr) self.arr = arr[:] self.block_size = max(1, math.isqrt(n)) num_blocks = (n + self.block_size - 1) // self.block_size self.blocks = [0] * num_blocks for i, v in enumerate(arr): self.blocks[i // self.block_size] += v def update(self, i: int, delta: int) -> None: self.arr[i] += delta self.blocks[i // self.block_size] += delta def query(self, l: int, r: int) -> int: """Inclusive range sum query.""" total = 0 lb = l // self.block_size rb = r // self.block_size if lb == rb: return sum(self.arr[l : r + 1]) for i in range(l, (lb + 1) * self.block_size): total += self.arr[i] for b in range(lb + 1, rb): total += self.blocks[b] for i in range(rb * self.block_size, r + 1): total += self.arr[i] return total
What Problems It Solves
Range queries with updates. When you need O(√n) per operation and O(n) build time on an arbitrary associative function (sum, min, max, GCD, XOR), sqrt decomposition works out of the box. Segment trees also cover this at O(log n), but they require roughly twice the code.
Queries that a Fenwick tree cannot express. Fenwick trees require an invertible aggregate (subtraction must exist) or careful double-tree techniques. Sqrt decomposition handles range minimum or mode queries directly, because you just store the block's aggregate and recompute it for partial blocks.
Mo's algorithm and offline range queries. Problems that ask you to compute some property of the sub-array [l, r] across many queries, where adding and removing one element from the range is O(1) or O(log n), can be solved with Mo's ordering. The canonical example is counting distinct elements in a range, which would be O(n^2) naively and is O(n√n) with Mo's.
Range update, point query. When you frequently add a constant to a range [l, r] and then query a single position, invert the lazy approach: store a pending addition per block, and at query time read arr[i] + lazy[block of i]. Updates become O(√n), point queries become O(1).
Block-level binary search. If you need the first index in [l, r] satisfying some property, you can skip whole blocks that definitely do not contain the answer, then walk through the one block that does. This gets you from O(n) to O(√n) without a segment tree.
Five Signals to Reach for This
- Range queries plus point updates, where a segment tree would be overkill for the implementation budget
- A query function that is hard to express as a Fenwick tree (non-invertible, or queries on non-additive aggregates)
- Offline queries with no updates: all queries given upfront, asking for range properties
- "Count distinct" or "mode in range" style problems
- O(n√n) is fast enough (n ≤ 10^5 with √n ≈ 316 makes ~30 million operations)
Worked example 1: Range Sum Query with Updates (LeetCode 307)
Problem: Given an integer array, implement sumRange(left, right) and update(index, val).
The naive answer reaches for a Fenwick tree. Sqrt decomposition works just as well and is harder to get wrong.
Why sqrt fits: Updates and queries are both O(√n). For n = 30,000 (LeetCode's constraint), √n ≈ 173. That is fast.
How to see it: "Updates that change a single element" maps to point update O(1). "Query over a range" maps to range query O(√n). The block aggregates accumulate sums, so after a point update you fix one element and its block's sum.
# LeetCode 307 solution using sqrt decomposition class NumArray: def __init__(self, nums: list[int]) -> None: import math n = len(nums) self.arr = nums[:] self.k = max(1, math.isqrt(n)) num_blocks = (n + self.k - 1) // self.k self.blocks = [0] * num_blocks for i, v in enumerate(nums): self.blocks[i // self.k] += v def update(self, index: int, val: int) -> None: delta = val - self.arr[index] self.arr[index] = val self.blocks[index // self.k] += delta def sumRange(self, left: int, right: int) -> int: total = 0 lb = left // self.k rb = right // self.k if lb == rb: return sum(self.arr[left : right + 1]) for i in range(left, (lb + 1) * self.k): total += self.arr[i] for b in range(lb + 1, rb): total += self.blocks[b] for i in range(rb * self.k, right + 1): total += self.arr[i] return total
Signal you missed: LeetCode 307 explicitly says both operations can be called up to 30,000 times each. That's the hint that O(n) per query is too slow and O(√n) or O(log n) is the target. When you see a problem with both query and update operations and a medium-sized n, think sqrt decomposition before reaching for a segment tree.
Worked example 2: Count of Distinct Values in Range (Mo's algorithm)
Problem: Given array arr of length n and q queries, each asking how many distinct values appear in arr[l..r].
Brute force: O(n) per query via a hash set. With q = 10^5 queries, this is 10^10 operations.
Why Mo's fits: The operation "add element arr[r+1] to the current window" and "remove element arr[l-1] from the window" can each be done in O(1) with a frequency counter. That makes Mo's algorithm applicable.
How to see it: The magic words are "distinct values in a range" and "offline" (all queries given at once). Mo's needs:
- O(1) or O(log n) add/remove for the sliding window
- All queries available before processing begins
from collections import defaultdict import math def count_distinct_queries(arr, queries): n = len(arr) k = max(1, math.isqrt(n)) # Attach original index to each query for output ordering indexed_queries = [(l, r, i) for i, (l, r) in enumerate(queries)] # Sort: by block of left endpoint, then right endpoint (ascending) indexed_queries.sort(key=lambda q: (q[0] // k, q[1] if (q[0] // k) % 2 == 0 else -q[1])) freq = defaultdict(int) distinct = 0 cur_l = 0 cur_r = -1 answers = [0] * len(queries) def add(pos): nonlocal distinct freq[arr[pos]] += 1 if freq[arr[pos]] == 1: distinct += 1 def remove(pos): nonlocal distinct freq[arr[pos]] -= 1 if freq[arr[pos]] == 0: distinct -= 1 for l, r, qi in indexed_queries: while cur_r < r: cur_r += 1 add(cur_r) while cur_l > l: cur_l -= 1 add(cur_l) while cur_r > r: remove(cur_r) cur_r -= 1 while cur_l < l: remove(cur_l) cur_l += 1 answers[qi] = distinct return answers
The Mo's signal: You're computing a range statistic across many queries with no updates. The add and remove operations are O(1). The problem doesn't require online processing (no query depends on a previous answer). All three conditions met: use Mo's.
Time: Sorting queries is O(q log q). Processing is O((n + q)√n). For n = q = 10^5, that's about 3 * 10^7 operations.
When Sqrt Beats Segment Tree
 Okay this is slightly exaggerated. But O(√n) with 30 lines versus O(log n) with 80 lines is a real tradeoff.
Okay this is slightly exaggerated. But O(√n) with 30 lines versus O(log n) with 80 lines is a real tradeoff.
Sqrt decomposition loses on asymptotic complexity: O(√n) per operation vs O(log n). For n = 10^6, that's 1000 operations vs 20. So why would you ever choose it?
Code simplicity under pressure. The core logic is 15 to 20 lines. The only mandatory edge case is the same-block guard. A segment tree with lazy propagation is 50 to 80 lines and has notoriously subtle index arithmetic. You are in a timed interview. The segment tree has let you down before. You know what it did.
Non-standard aggregates. Segment trees with lazy propagation get complicated fast when the aggregate is not trivially composable. Mode queries, frequency-based statistics, and "count of values satisfying a predicate" are all natural for sqrt decomposition and painful for lazy segment trees.
Mo's algorithm has no segment tree equivalent. The offline query reordering technique is sqrt-specific. That is not fixable with a fancier data structure.
The block size is a tunable constant. The AM-GM argument gives the asymptotically optimal k = √n, but competitive programmers often benchmark nearby values, since cache behavior and the specific query distribution can shift the practical optimum. This is the kind of optimization you do after getting the answer, not during.
The Non-Obvious Traps
The lb == rb case is mandatory. If the left and right endpoints fall in the same block, the standard three-zone logic breaks: the "full blocks" loop runs from lb+1 to rb-1 which is an empty range, but the left and right partial traversals would overlap and double-count. Handle this by summing the sub-array directly. Skip this guard and your code will pass 95% of test cases and fail on the one the interviewer writes on the board. Every implementation above handles it.
Integer square root vs floating point. In Python 3 use math.isqrt(n), not int(math.sqrt(n)). For n = 10^18, math.sqrt is a float64 and can round incorrectly. For the block sizes used in practice this matters less, but isqrt is exact and costs nothing.
In Mo's, the block size for q queries is n/√q, not √n. When q is much smaller than n, using √n blocks wastes time on over-sorting. The optimal block size minimizes the same cost function but now parameterized by both n and q. This is a constant-factor tweak that matters in competitive programming but rarely in interviews.
Range update + range query needs both lazy and partial recomputation. When a partial block gets an element-by-element range update, the block's precomputed aggregate goes stale. You must either recompute it from scratch (O(k)) or maintain it carefully. The lazy block addition only applies cleanly to full blocks where every element gets the same delta.
Mo's alternating sort direction. The simple sort (by block, then by R ascending) is correct but not optimal. Alternating between ascending R on even-numbered blocks and descending R on odd-numbered blocks (the "zigzag" version) eliminates the O(n) right-pointer reset when moving from one block to the next. It halves the constant on the right pointer movement in practice.
The Comparison You Actually Need
| Structure | Build | Point Update | Range Query | Range Update | Use when |
|---|---|---|---|---|---|
| Naive array | O(n) | O(1) | O(n) | O(n) | Never for queries |
| Prefix sum | O(n) | O(n) rebuild | O(1) | O(n) | Static arrays, no updates |
| Sqrt decomp | O(n) | O(1) | O(√n) | O(√n) | Simple to implement, offline queries |
| Fenwick tree | O(n) | O(log n) | O(log n) | O(log n) | Additive aggregates, invertible |
| Segment tree | O(n) | O(log n) | O(log n) | O(log n) | General, non-invertible aggregates |
Sqrt decomposition sits between prefix sums and segment trees: more flexible than prefix sums, simpler to implement than segment trees, and worse asymptotically than both.
The Short Version
- Split the array into ⌈n/k⌉ blocks of size k ≈ √n
- Precompute an aggregate per block in O(n) time and O(√n) extra space
- Range query: walk two partial blocks (O(k)) + sum full blocks (O(n/k)) = O(√n) total
- Point update: fix element + block aggregate. O(1)
- Range update: partial blocks element-by-element (O(k)), full blocks with a lazy addition (O(n/k)). O(√n)
- The optimal block size √n follows from minimizing k + n/k via AM-GM
- Mo's algorithm applies sqrt decomposition to offline queries: sort by block of L, then by R; total cost O((n + q)√n)
- The
lb == rbguard is not optional - Use
math.isqrtin Python 3 rather thanint(math.sqrt(n)) - Mo's optimal block size is n/√q when q queries are given, not √n
If you want to practice explaining the AM-GM argument or walking through Mo's query ordering under pressure, SpaceComplexity runs voice-based mock interviews where you talk through the tradeoffs out loud, the same way a real interviewer expects.
For the related structures that achieve O(log n) with a similar "precomputed aggregates" philosophy, see the segment tree deep dive and the Fenwick tree for the additive-only case.