Stack vs Heap: The Two Memory Regions Behind Every Recursion Bug
- Stack vs heap memory: the stack is fast, auto-managed, and limited (8 MB on Linux, 1 MB on Windows); overflow it and you crash.
- Heap memory holds any object that must outlive the function that created it: linked list nodes, tree nodes, and dynamic structures all live here.
- Recursion space complexity is measured in stack frames, not heap objects: O(h) for DFS means h frames alive on the call stack simultaneously.
- Converting recursion to iterative trades call stack space for heap space, which is why it avoids
RecursionErrorwithout changing logical complexity. - Dangling pointers happen when you return a pointer to a stack-allocated variable: the frame dies on return, the pointer lies.
- Tail-call optimization can collapse O(n) stack depth to O(1), but CPython and most JVM implementations don't do it.
- Backtracking copy cost (
path[:]) is a heap allocation per leaf; aliasing avoids the allocation but introduces the classic mutation bug.
Your recursive DFS hits a RecursionError. Your linked list nodes vanish when you return from a function. You get a segfault for no obvious reason. These are not random bugs. They all trace back to one misunderstanding about stack vs heap memory: your program has two completely separate memory regions, and different kinds of data live in each one for different reasons.
The mental model: the stack holds things that die with the function that created them; the heap holds things that outlive any single function call.
That one sentence explains most of what goes wrong. The other 10% is undefined behavior. We'll get there.

Every programmer's face upon seeing RecursionError: maximum recursion depth exceeded in comparison for the first time.
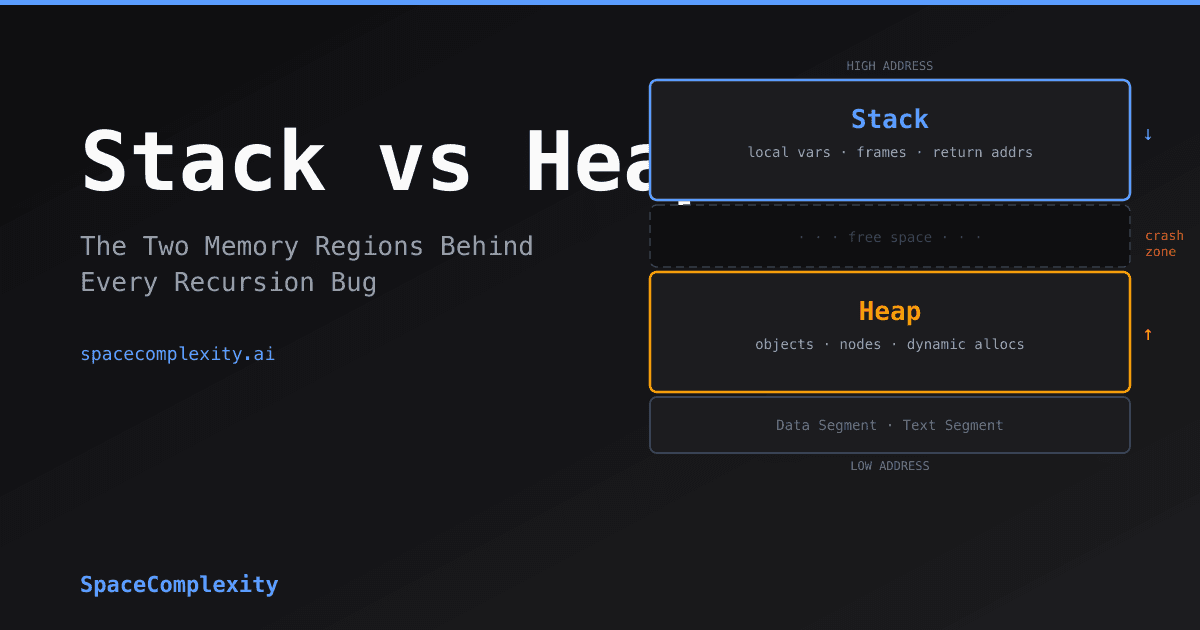
Your Program's Address Space Has Four Regions
When your OS launches a process, it maps a chunk of virtual memory to that process. That memory is divided into four regions, from low addresses to high:

Your process gets four memory regions. The stack and heap grow toward each other. If they meet, something crashes. Usually the stack gets there first.
The heap and stack grow toward each other. If they meet, something crashes. Usually the stack crashes first, because it starts at a much lower limit.
The text and data segments are mostly fixed at load time. The interesting action is in the stack and heap.
The Stack: One Pointer to Rule Them All
Every thread has its own call stack. On x86-64, the stack pointer register (rsp) tracks the top. When you call a function, the CPU runs a prologue that saves the caller's frame pointer and moves rsp down to make room for the new frame. When the function returns, the epilogue moves rsp back up. That's it. Allocation is a single instruction.
A stack frame holds exactly what the function needs to run:
- The return address (where to jump back when the function exits)
- The saved frame pointer from the caller
- All local variables
- Function arguments (when they overflow registers)
def add(x, y): result = x + y # 'result', 'x', 'y' all live in this stack frame return result # frame is destroyed here; result value is returned in a register
When add returns, that frame is gone. Not freed. Not garbage collected. Just gone: rsp moved up, and that memory is instantly available for the next call. Stack allocation is this fast because local variables have no lifetime beyond the function.
The Stack Has a Hard Ceiling
The stack is fast because it's simple and small. Default stack sizes:
- Linux: 8 MB
- macOS: 8 MB
- Windows: 1 MB
Those limits apply per thread. If your recursion is 50,000 levels deep and each frame is 200 bytes, you need 10 MB. On Linux, you get a segfault. On Windows, you hit the limit at 1/8th of the depth. Windows users suffer twice. Python saves you from this by imposing a default limit of 1,000 frames before you hit the OS limit. When you see RecursionError: maximum recursion depth exceeded, the interpreter stopped you on purpose. That is a kindness. C does not offer this kindness. C offers a segfault.
The error name "stack overflow" is not metaphorical. The call stack literally overflowed its memory region.
The Heap: Memory That Outlives the Function
The heap is the other region. It starts at a low address and grows upward as your program allocates. Unlike the stack, there is no automatic cleanup. You allocate memory (malloc in C, new in C++ and Java, object creation in Python), and it stays allocated until something frees it or a garbage collector reclaims it.
class Node: def __init__(self, val): self.val = val self.next = None # This object lives on the heap node = Node(5)
In Python, the name node lives in the current stack frame. The Node object itself is on the heap. When node goes out of scope, the reference count drops; Python's reference-counting GC eventually frees the heap memory. In Java, you'd wait for the GC mark-and-sweep. In C, you'd call free() yourself. If you forget, the memory leaks. If you free it twice, you get a crash. C gives you rope in quantities that are genuinely alarming.
Heap allocation is slower because it has to do real work:
- Find a free block large enough for the request
- Split that block if it's too large
- Record metadata about the allocation
- Return a pointer
This bookkeeping creates fragmentation over time. Many small allocations and frees leave gaps between live objects, so even if total free space is large enough for a new allocation, no single contiguous gap might be. GC runtimes solve this with compaction, which moves live objects together and costs pause time.
Stack vs Heap: What Goes Where and Why
The division between stack and heap is not a style choice. It follows from lifetime.
Stack: local variables of primitive type, references/pointers to heap objects, function parameters, return addresses.
Heap: every object whose size is unknown at compile time, every object that must outlive the function that created it, every dynamically linked structure like a linked list or tree.
In Java, every object without exception goes on the heap. The stack holds primitive values (int, long, boolean) and references (pointer-sized values). When you write:
int x = 5; // lives in the current stack frame Node node = new Node(5); // 'node' reference on stack; Node object on heap
In Python, everything is an object, so everything is on the heap. The CPython frame holds references to those heap objects.
Why Linked List Nodes Cannot Live on the Stack
This is where the distinction becomes concrete. Say you try to build a linked list with stack-allocated nodes:
// THIS IS WRONG struct Node* build_list() { struct Node head = {1, NULL}; // on the stack struct Node second = {2, NULL}; // on the stack head.next = &second; return &head; // returning pointer to a dead stack variable }
When build_list returns, its stack frame is gone. The pointer you returned points to memory that is now garbage, possibly already overwritten by the next function call. This is a dangling pointer. In C, accessing it is undefined behavior. It may crash. It may appear to work fine today and fail at the demo. The canonical fix is heap allocation:
// Correct struct Node* build_list() { struct Node* head = malloc(sizeof(struct Node)); head->val = 1; head->next = malloc(sizeof(struct Node)); head->next->val = 2; head->next->next = NULL; return head; // heap memory persists after return }

The head pointer lives in the stack frame and dies on return. The Node object lives on the heap and persists. This is the distinction that makes linked lists possible.
The node's lifetime must span the entire list's lifetime. Heap gives you that. Stack does not.
Why This Matters for Every DSA Problem You Practice
Recursion Space Complexity Lives in the Stack
When you write a recursive DFS on a binary tree and say it takes O(h) space, where does that space come from? The call stack. (If you want the full derivation of recursion complexity, Recursion Time Complexity walks through the tree method and the Master Theorem.) Each recursive call creates a new stack frame. For a balanced tree of height h, you have h frames alive simultaneously, each holding the current node reference and any local variables.
def dfs(node): if not node: return 0 left = dfs(node.left) # new frame pushed right = dfs(node.right) # new frame pushed return 1 + max(left, right)

Each call pushes a frame. At the deepest point, every frame on the path from root to that node is still alive, suspended and waiting. That's your O(h) stack cost.
At the deepest point, you have h frames on the stack. For a skewed tree of n nodes, h = n, and you have n frames. On a balanced tree of 100,000 nodes, h ≈ 17, so you have 17 frames. The tree itself (all the Node objects) lives on the heap and costs O(n) space there. The recursion costs O(h) on the stack. These are separate budgets.
That is why the space complexity of a recursive algorithm has two components: heap space for the data structure, and stack space for the recursion depth. Most complexity analyses only count the former, but the latter is the one that crashes your program.
The Iterative Trick Trades Stack for Heap
When you convert a recursive DFS to iterative, you introduce an explicit stack data structure:
def dfs_iterative(root): stack = [root] # this list lives on the heap while stack: node = stack.pop() if node.right: stack.append(node.right) if node.left: stack.append(node.left)

Same logical traversal. Recursive version stores state in the OS call stack. Iterative version stores the same state in a heap-allocated list. The failure mode is different. The logic is identical.
That stack list is a Python list, which is a heap-allocated object. You are now storing the traversal state on the heap instead of the call stack. Same O(h) worth of nodes, different memory region. This is why iterative DFS does not hit the recursion limit: it uses heap memory, which is orders of magnitude larger than the call stack.
The transformation is not a free lunch. You trade the elegant call stack (which saves and restores state automatically) for manual state management in a heap-allocated structure. You also potentially change your cache behavior, since call stacks tend to be hot in L1 cache.
The Hidden Cost of Object Creation in Loops
Heap allocation is expensive relative to stack operations. If you are creating new objects in a tight loop during an interview (say, creating a new list or tuple on every iteration of a backtracking search), each allocation is a call into the heap allocator with all its bookkeeping overhead.
This is one concrete reason that copying a path versus passing a reference looks identical in big-O but can be 10x different in practice:
# Each call copies the list (O(k) heap allocation) def backtrack(path): results.append(path[:]) # new list object allocated on heap ... # Passing the reference is O(1) stack operation, no heap allocation def backtrack(path): results.append(path) # but now mutation is shared: classic bug
The first version is correct and does a heap allocation per leaf. The second version avoids allocation but aliases the same list, so every result in results will show the same final state. This is the mutation bug that trips people up in backtracking, covered in depth in Backtracking Time Complexity. That allocation cost is exactly what makes the buggy version tempting.
The Part Everyone Misses: The Call Stack Is a Stack
The "stack" in "call stack" and the "Stack" data structure you implement in DSA are the same underlying idea. LIFO. Push on call, pop on return. When you implement a Stack class backed by a list in Python, that list lives on the heap, but you are simulating the same LIFO discipline that the CPU's call stack uses natively.
The recursive solution and the iterative-with-explicit-stack solution are logically identical; they differ only in which memory region holds the frames. Recursive: call stack (fast, limited). Iterative: heap (slower allocation, effectively unlimited).
This is also why tail-call optimization matters. If the last thing a recursive function does is call itself (a tail call), a smart compiler can reuse the same stack frame instead of pushing a new one, converting O(n) stack space into O(1). Python's CPython does not do this, for reasons that are either philosophical or technical depending on who you ask. Most JVM implementations do not either. Languages like Haskell and Scheme guarantee it. If you want O(1) stack depth in Python, you need to convert to iterative yourself. Python is not sorry. It comes up in interview follow-ups whenever someone asks how you'd reduce the space usage of a recursive solution.
Quick Recap
One more time, for everyone who hit a segfault and came here in a panic:
- The stack holds stack frames: local variables, return addresses, saved registers. Allocated and freed in one instruction. Limited (8 MB on Linux, 1 MB on Windows).
- The heap holds dynamically allocated objects. Persists until freed or garbage collected. Much larger but slower.
- Primitives live in the stack frame. Objects live on the heap with a reference in the frame.
- Linked list nodes, tree nodes, and any object that must outlive its creating function must be on the heap.
- Recursive DFS costs O(h) stack space. Converting to iterative moves that cost to heap.
- Iterative solutions avoid stack overflow but do not change the logical space complexity.
- Tail-call optimization can collapse O(n) stack depth to O(1), but most runtimes do not do it.
If you want to practice explaining concepts like this under pressure, SpaceComplexity runs voice-based mock interviews where you have to narrate your space analysis out loud. The gap between "I know it" and "I can explain it clearly while coding" is where most candidates lose points.