Trie vs Suffix Tree: One Searches a Dictionary, One Searches Text
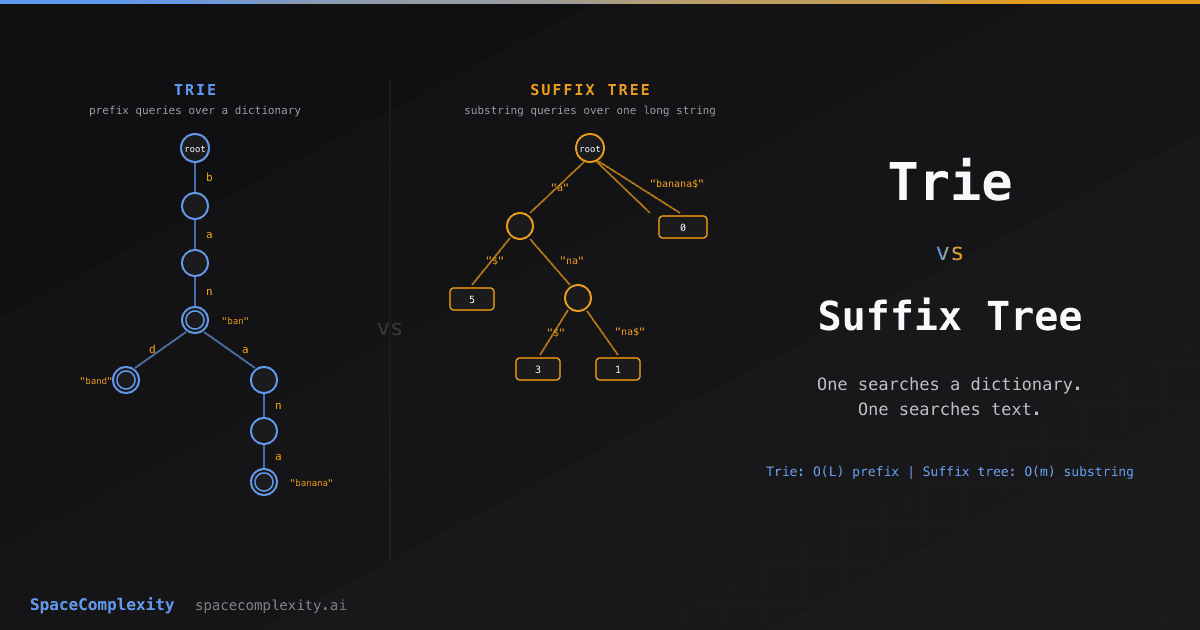
- Trie indexes a dictionary of strings for O(L) prefix lookup; suffix tree indexes all substrings of one string for O(m) pattern search.
- The suffix trie (naive all-suffixes trie) has O(n²) nodes; Ukkonen's three tricks compress it to O(n) nodes and O(n) build time.
- Edge labels stored as (start, end) index pairs are the compression that makes the suffix tree possible: no character copying, no quadratic blowup.
- Longest repeated substring is the deepest internal node in the suffix tree, found in O(n) by a single DFS.
- Suffix array is the practical alternative: 4 bytes/char vs 10-20 for the suffix tree, with O(m log n) search instead of O(m).
- In interviews, proposing a "trie of all suffixes" without compression is a red flag; the answer must make the (start, end) edge encoding explicit.
People describe the suffix tree as "a compressed trie." That's technically correct and completely misleading. A trie and a suffix tree solve different problems. The trie vs suffix tree choice is not a speed-vs-memory tradeoff. It's recognizing which problem you actually have.
The short version: use a trie when you have a dictionary of strings and need prefix queries; use a suffix tree when you have one long string and need to query any substring of it. Everything else follows from that distinction.
The Trie's One Job
You have a dictionary of words: {"ban", "band", "banana", "bandana"}. Someone types "ban" and you need to find every word that starts with it. That's prefix lookup over a set of strings.
A trie stores those strings by sharing their common prefixes. Each edge carries one character. Each node represents the accumulated prefix on the path from root to that node, and a flag marks where words end.

All four words share the prefix "b-a-n". The trie stores that path exactly once.
For a dictionary with W words of average length L, building the trie costs O(W * L) time. Every operation (insert, exact search, prefix search) runs in O(L) where L is the query length, independent of how many words are in the dictionary. That's the key advantage over a hash map: a trie groups all words with the same prefix in one subtree, so "give me everything starting with 'ban'" is a single subtree traversal, not a scan of all keys.
The space cost is the other side of that deal. A naive trie allocates an array of SIGMA child pointers at every node, where SIGMA is the alphabet size. For lowercase English that's 26 slots per node, most of them null. With N total nodes you spend O(N * SIGMA) memory even if the trie is sparse. A Patricia trie (compressed trie / radix tree) collapses chains of single-child nodes into one edge, but the fundamental shape stays the same: it's organized around the strings you've inserted.
Why You Can't Just Build a Trie of All Suffixes
Now imagine a different problem. You have one long string T (a chromosome, a book, a log file) and you want to answer queries like: "Does pattern P appear anywhere in T?" That's substring search, not prefix search.
The naive idea: build a trie of all suffixes of T. For T = "banana$" the suffixes are:
banana$
anana$
nana$
ana$
na$
a$
$
Insert all seven into a trie, and any pattern match becomes a root-to-node walk. It works. The problem is size. A trie of all n suffixes of a length-n string contains O(n²) nodes. For T of length n, suffix i has length n-i, so the total characters across all suffixes is n + (n-1) + ... + 1 = n(n+1)/2 = O(n²). On a genome of 3 billion base pairs, that's 4.5 * 10^18 nodes. Dead on arrival.

Seven suffixes, 28 characters to store. At n=1000 that's 500,000 nodes. At n=3B (human genome), you're done.
The Compression That Saves Everything
A suffix tree compresses every chain of single-child nodes into a single edge. Instead of spelling out each character, an edge stores a pair (start, end) indexing into the original string T. The label is a view, not a copy.
That one change drops the node count from O(n²) to O(n). Specifically, a suffix tree on an n-character string (with a unique terminal character $) has at most n leaves and at most n-1 internal nodes, for a total of 2n-1 nodes. Every internal node has at least two children, since the compression merges any single-child chain. The space is O(n): about 10-20 bytes per character in a typical C implementation, compared to the suffix array's 4 bytes per character.

10 nodes instead of 28. Scale that to a million-character string: 2 million nodes vs 500 billion. The compression is not optional.
Building this tree naively costs O(n²). Esko Ukkonen's 1995 algorithm does it online in O(n) using three tricks:
- Global end pointer. All leaf edges end at the current position. Extending every leaf edge as each new character arrives is free: increment one integer, and every leaf edge extends automatically.
- Rule 3 (showstopper). If the new character already exists on the current edge, stop the current phase. The whole suffix is already implicitly present. No leaf needs to be added.
- Suffix links. After creating an internal node during an extension, link it to the node representing the same string minus its first character. When Rule 3 fires in one branch, a suffix link jumps you to the next smaller suffix's insertion point in O(1) instead of re-scanning from root.
Those three tricks keep total work across all n phases at O(n). If you want the full derivation, the suffix tree reference walks through each trick in detail.
The Cold Hard Numbers
| Operation | Trie | Suffix Tree |
|---|---|---|
| Build | O(W * L) total across all words | O(n) for one string |
| Insert one string | O(L) | N/A (static structure) |
| Prefix search | O(L) | O(L + k) results |
| Exact substring search | Not directly supported | O(m) for pattern of length m |
| All occurrences of P | N/A | O(m + k) |
| Longest repeated substring | Build trie of all substrings (O(n²)) | O(n) (deepest internal node) |
| Longest common substring | Generalized trie, expensive | O(n + m) generalized suffix tree |
| Count distinct substrings | O(n²) to build | O(n): sum of edge label lengths |
| Space | O(N * SIGMA) or O(N) compressed | O(n) |
Here W is the number of words, L is average word length, n is the single-string length, and m is the query pattern length.
The suffix tree supports everything the trie does for prefix queries, but the trie has no equivalent for arbitrary substring search. To do prefix lookup, walk the tree for the prefix, then DFS the subtree for all matches. The tree compresses all suffix information into one reusable index.
When to Pick the Trie
A trie makes sense whenever your data is a dynamic collection of independent strings and your queries are prefix-based.
Autocomplete and spell-checking are the canonical cases. You insert millions of words once (or incrementally), then handle a constant stream of prefix queries. The trie shares prefixes across all words, so "the" is stored once even though thousands of words start with it. Adding or deleting a word is O(L) and doesn't invalidate anything else.
IP routing tables are another classic: IPv4 has 32-bit addresses, and the routing table maps prefixes (like 192.168.0.0/16) to next hops. A trie on the binary representation of an address finds the longest-prefix match in O(32) = O(1) hops regardless of table size.
Tries also win when your alphabet is small and your strings are long, since the compression of shared prefixes becomes dramatic. A dictionary of DNA k-mers over {A, C, G, T} fits compactly because SIGMA = 4.
What tries can't do is substring queries. Asking "which of my words contains 'nana' somewhere in the middle?" requires scanning every word unless you build some additional structure.
When the Suffix Tree Wins
The suffix tree is the right tool when you have one piece of text you'll query many times, and your queries are about arbitrary substrings.
Pattern matching. Build the suffix tree for T once in O(n). Then each pattern query of length m costs O(m): just walk down from the root, consuming the pattern character by character. If you fall off the tree, no match. If you reach a node, all leaves in that subtree are occurrence positions. For k total occurrences the full reporting costs O(m + k). Compare that to KMP at O(n + m) per query: if you run thousands of pattern queries on the same text, the suffix tree amortizes its O(n) build cost across all of them. KMP reruns n characters every time. The suffix tree runs m characters every time.
Longest repeated substring. In a trie of all substrings this would cost O(n²). In the suffix tree, the answer is the deepest internal node (the deepest node that has at least two children), since that node represents the longest string that is a prefix of at least two different suffixes. One DFS in O(n) finds it.
Longest common substring of two strings S and T. Build a generalized suffix tree over S$T# (two different sentinel characters). Track which leaves descend from S-suffixes and which from T-suffixes. The deepest internal node with leaves from both is the answer. O(n + m) total.
Counting distinct substrings. Every distinct substring corresponds to a unique path prefix in the suffix tree. The count equals the sum of edge label lengths: each edge of label length L contributes L new substrings (one for each position along it). For "banana$" excluding the sentinel, the sum is 14, which matches the known answer.
The catch: suffix trees are static. Ukkonen's algorithm handles online insertion (characters arrive one by one), but arbitrary deletion and reinsertion destroy the structure. If your text changes frequently, you're back to rebuilding from scratch. A trie doesn't care. You can insert and delete words all day.
The Worked Example: Hunting "ana" in "banana"
Build the suffix tree for "banana$". To search for pattern "ana":
- Start at root. Try to match 'a'. Root has an edge starting with 'a'. Go there.
- Consume the edge label. The edge from root labeled 'a' leads to internal node A. We consumed 'a'; remaining pattern is "na".
- From node A, look for an edge starting with 'n'. There is one, labeled "na". Consume it; remaining is "".
- Pattern exhausted. We're at node B. Every leaf below this node is an occurrence.
- Two leaves below: positions 1 and 3 in "banana" (0-indexed). Report both.
Total work: O(m) = O(3) to descend, then O(k) = O(2) to enumerate results.

The search doesn't touch the "na", "banana$", or "$" branches at all. Only the path that matches consumes work.
Should You Use the Suffix Array Instead?
For most production substring-search problems, you should know about suffix arrays before committing to a suffix tree. A suffix array stores just the sorted starting positions of all suffixes in 4n bytes (vs. 10-20 bytes/char for the tree). Combined with the LCP array, it supports the same queries with O(m log n) search or O(m + log n) with precomputed LCP-LR arrays. The construction runs in O(n) with SA-IS.
The suffix tree is faster per query (O(m) vs. O(m log n)) and more natural for tree-structural queries like longest repeated substring. The suffix array wins when memory is tight or you need to serialize the index to disk.
For a bioinformatics pipeline scanning a genome once, suffix tree. For a search engine index you'll serialize to disk and reload later, suffix array.
The Non-Obvious Trap: The Suffix Trie Is Not the Suffix Tree
People sometimes propose "build a trie of all the string's suffixes" thinking they get a suffix tree. They don't. They get a suffix trie, which has O(n²) nodes and O(n²) build time.
The compressed suffix tree requires the compression to exist at all. Without edge labels stored as index pairs, there's no avoiding the quadratic blowup. At n=10,000 that's 100 million nodes. At n=10^6, it's a trillion. Your interviewer will notice.
This distinction matters in interviews: if asked "how would you support substring queries on a string?", proposing a naive suffix trie is a red flag. The answer has to be either the compressed suffix tree (with compression explicit) or the suffix array. "A trie of all suffixes" with no mention of compression is the kind of answer that gets a polite "interesting, but what's the space complexity?" followed by the sort of silence that echoes.
Quick Recap
- Trie: indexes a dynamic set of strings, optimized for prefix queries, O(L) per operation.
- Suffix tree: indexes all substrings of one static string, O(n) build, O(m) pattern search.
- The naïve suffix trie (all suffixes in a plain trie) is O(n²) space and build time. Ukkonen's compression brings it to O(n).
- Use a trie for autocomplete, routing, and dictionary problems. Use a suffix tree for full-text search, repeated substring, and bioinformatics.
- Internal nodes with two or more children are the structural unit of power: deepest such node = longest repeated substring.
- For most real problems, consider the suffix array first. It does 90% of what the suffix tree does at 25% of the memory.
If you're interviewing and find yourself trying to reason through substring search verbally, SpaceComplexity runs voice-based mock interviews with rubric feedback so you can practice explaining exactly these structural tradeoffs before the real thing.
For deeper background, the reference articles on the trie, suffix tree, and suffix array walk through each structure in full.
Further Reading
- Suffix tree (Wikipedia): formal definition, properties, history from Weiner 1973 through Ukkonen 1995
- Trie (Wikipedia): complete formal treatment including compressed variants
- Ukkonen's Suffix Tree Construction (GeeksforGeeks): step-by-step walkthrough of the three tricks
- Trie Data Structure (GeeksforGeeks): insert, search, and delete with complexity proofs
- Suffix Array (GeeksforGeeks): the space-efficient alternative to the suffix tree