Twitter News Feed System Design Interview: Fan-Out, Celebrities, and the Hybrid Fix
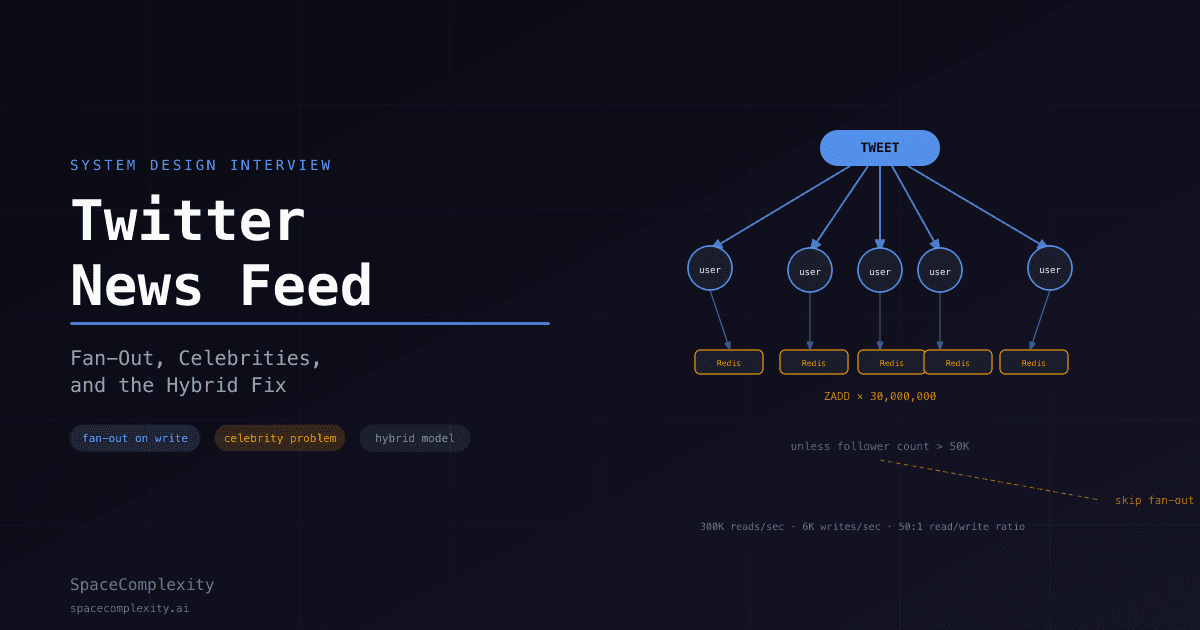
- Fan-out on write pre-computes each follower's timeline in Redis on every tweet, giving O(1) reads but catastrophic write amplification for celebrity accounts with millions of followers.
- Fan-out on read queries all followed accounts at load time, staying simple but crushing the database as followee counts and read volume scale up.
- The hybrid model skips fan-out for accounts above roughly 50,000 followers and merges their tweets at read time, solving the celebrity problem without sacrificing read speed.
- Redis sorted sets store pre-computed timelines scored by Snowflake tweet ID, capped at 800 entries per user so newer posts automatically evict old ones.
- Kafka decouples the write path from fan-out: a tweet returns immediately while background workers propagate to follower timelines asynchronously.
- Cursor-based pagination anchors each page to a specific tweet ID so posts added between page loads are never silently skipped.
Your interviewer opens with: design the Twitter news feed. Easy, right? Users tweet, followers see it. You sketch a database, add a cache, call it done. Then they ask: "What happens when Lady Gaga posts?"
Your design collapses.
The core challenge is write amplification. When a user with 30 million followers tweets, your system must update 30 million timelines. How you handle that one decision separates a toy design from a real one. Get it right and you look like someone who has actually thought about scale. Get it wrong and you spend the next 20 minutes explaining why your Redis cluster is on fire.
This walkthrough covers every stage in interview order: requirements, estimation, high-level architecture, data model, APIs, feed generation, scaling, and how to pace yourself in 45 minutes.
Scope It Before You Sketch Anything
Spend the first three minutes scoping. Interviewers reward candidates who ask before drawing. The questions that shape the whole design:
- Feed type: home timeline (people you follow) or algorithmic "For You" recommendations?
- Real-time: does the feed update live, or on refresh?
- Ordering: reverse chronological, or ranked by engagement?
- Content: text only, or media too?
For this walkthrough, scope to: home timeline, tweets and retweets, refresh-based updates, reverse chronological with a light ranking pass, media supported. This covers the interesting problems without drowning in ML infrastructure.
Functional requirements:
- Users post tweets (up to 280 chars, optional media)
- Users follow and unfollow other users
- Home timeline shows tweets from followed accounts, newest first
- Feed paginates; user can scroll back through history
Non-functional requirements:
- 250 million daily active users, 500 million tweets per day
- Read-heavy: roughly 50 timeline reads per user per day
- Eventual consistency is acceptable; a 500ms delay before a follower sees a tweet is fine
- 200ms p99 timeline load time
Do the Math Before You Draw Anything
Back-of-envelope estimates tell you where the bottlenecks are. Do them explicitly in the interview. Interviewers want to see you quantify, not wave hands.
| Metric | Estimate |
|---|---|
| Tweet writes | ~6,000 QPS average, ~30,000 peak |
| Timeline reads | ~300,000 QPS |
| Average followers per user | 200 |
| Fan-out writes (avg) | 6,000 x 200 = 1.2M Redis ops/sec |
| Tweet storage | ~1 KB/tweet, ~180 TB/year |
The read-to-write ratio is about 50:1. Your caching strategy matters more than your write path optimizations. The system reads 50x as often as it writes. Optimize the read path first.
Now the celebrity case. A single tweet from an account with 30 million followers triggers 30 million timeline writes. One post, 30 million Redis ops. That is where fan-out-on-write dies. Your interviewer is absolutely waiting for you to notice this.
Start With Services, Not Database Boxes

Write path and read path are separate services. A tweet write publishes an event and returns immediately. Fan-out catches up in the background.
The key insight: the write path and the read path are completely decoupled. A tweet write does not block on fan-out. It publishes an event to Kafka and returns. Fan-out happens asynchronously. Your user gets a snappy response. Your Redis cluster handles the fan-out at its own pace.
The main services:
- Tweet Service: persists tweets to the database, publishes a
tweet_createdevent to Kafka - Fan-out Service: consumes events, looks up followers via Graph Service, writes tweet IDs into follower timelines in Redis
- Timeline Service: fetches pre-computed timelines from Redis; falls back to DB on cache miss
- Graph Service: stores the follow graph, sharded by both follower and followee for bidirectional lookup
- Media Service: uploads go to S3, served globally through a CDN
What the Data Model Looks Like
Three core tables. Resist the urge to add more until you have the basics right.
-- Users CREATE TABLE users ( user_id BIGINT PRIMARY KEY, -- Snowflake ID username VARCHAR(50) NOT NULL UNIQUE, follower_count INT DEFAULT 0, created_at TIMESTAMP NOT NULL ); -- Tweets (sharded by user_id) CREATE TABLE tweets ( tweet_id BIGINT PRIMARY KEY, -- Snowflake ID: encodes timestamp + machine + seq user_id BIGINT NOT NULL, content VARCHAR(280), media_url TEXT, created_at TIMESTAMP NOT NULL, INDEX idx_user_created (user_id, created_at DESC) ); -- Follows (sharded by follower_id; secondary index by followee_id) CREATE TABLE follows ( follower_id BIGINT NOT NULL, followee_id BIGINT NOT NULL, created_at TIMESTAMP NOT NULL, PRIMARY KEY (follower_id, followee_id) );
Use a Snowflake ID for tweet_id. It is a 64-bit integer that encodes a millisecond timestamp, a datacenter ID, a machine ID, and a per-machine sequence number. You get globally unique, roughly chronologically sortable IDs with no coordination between machines. Shard tweets by user_id so all tweets from one author live on one shard. This keeps author-level queries fast.
The Two APIs Worth Designing
POST /v1/tweets
Authorization: Bearer <token>
Body: { "content": "...", "media_ids": [] }
Response: { "tweet_id": "...", "created_at": "..." }
GET /v1/timeline?cursor=<tweet_id>&limit=20
Authorization: Bearer <token>
Response: { "tweets": [...], "next_cursor": "..." }
Use cursor-based pagination on the timeline, not offset. Offset pagination on a live feed skips posts when new tweets arrive between pages. A cursor anchors to a specific tweet ID so the next page starts exactly where the previous one ended. Your interviewer will appreciate this detail because most candidates miss it.
Feed Generation: Write First, Read First, or Both?
This is the core of the problem. Your interviewer is waiting for this section. Everything else is mostly table stakes.
Fan-Out on Read
When a user opens their feed, fetch recent tweets from every account they follow, merge, sort, return. No pre-computation needed.
The appeal is obvious. Simple to understand, simple to build. And it works fine if you follow 5 people. If you follow 500, that is 500 database queries on every feed load. At 300,000 reads per second across the platform, the DB is crushed. Users who follow 5,000 accounts are staring at a spinner.
Fan-out on read scales badly in exactly the scenario users care about most. Heavy Twitter users follow many accounts. Those are also the users who open the app most often. You have designed a system that penalizes your best customers.
Fan-Out on Write
When a tweet is written, the fan-out service looks up all followers and writes the tweet ID into each follower's Redis timeline. Reads become trivially fast: one O(log N) operation against a sorted set.

One tweet. One Kafka event. One fan-out worker. Thirty million ZADD calls. The write path returns fast. The Redis cluster catches up in the background.
def fan_out(tweet_id: int, author_id: int, score: float): followers = graph_service.get_followers(author_id) pipe = redis.pipeline() for follower_id in followers: key = f"timeline:{follower_id}" pipe.zadd(key, {str(tweet_id): score}) pipe.zremrangebyrank(key, 0, -801) # keep only 800 newest entries pipe.execute()
The problem: Lady Gaga tweets. Fan-out starts. At 100,000 Redis ops per second, distributing to 30 million followers takes five minutes. Her followers see the tweet five minutes late. That is not a news feed. That is an archive with drama.
Fan-out on write gives you fast reads but creates catastrophic write amplification for accounts with millions of followers. You have traded one bad problem for a different, worse one.
The Hybrid Model (What Twitter Actually Uses)
You cannot pick one or the other. You need both. Assign users to a path based on their follower count.

Regular users: fan-out on write. Celebrities: fan-out on read. The Timeline Service merges both at query time. The merge is cheap because most users follow very few celebrities.
Define a threshold: accounts with more than ~50,000 followers do not participate in fan-out. Their tweets stay in the tweet DB. When a user loads their feed, the Timeline Service runs two queries and merges:
- Fetch the pre-computed timeline from Redis (regular accounts)
- Fetch the latest tweets from any followed celebrity accounts directly from the DB
Merge the two sorted lists in memory. This merge is fast because the celebrity set is small. Most users follow zero or a handful of celebrity accounts.
def get_timeline(user_id: int, cursor: int, limit: int = 20) -> list: # Pre-computed timeline for regular accounts tweet_ids = redis.zrevrangebyscore( f"timeline:{user_id}", "+inf", cursor, start=0, num=limit * 2 ) # Fan-out on read for celebrities celebrity_ids = graph_service.get_followed_celebrities(user_id) celebrity_tweets = [] if celebrity_ids: celebrity_tweets = tweet_db.get_recent_tweets( user_ids=celebrity_ids, before=cursor, limit=20 ) all_tweets = merge_by_tweet_id(tweet_ids, celebrity_tweets) return all_tweets[:limit]
The extra read cost is single-digit milliseconds. The write savings are enormous. You have just solved the celebrity problem without rebuilding your architecture.
How Redis Stores Your Timeline

Each user's timeline is one sorted set. Tweet IDs double as scores because Snowflake IDs encode timestamps. Higher score means newer tweet. No separate sort needed.
Each user's timeline is a Redis sorted set keyed by timeline:{user_id}. The score is the Snowflake tweet ID, which encodes timestamp, so higher scores are newer tweets. Members are also tweet IDs.
Twitter caps stored timelines at 800 entries per user. That is several days of content for an active follower count. If a user has been away for weeks, the cache is cold. The Timeline Service detects the miss and falls back to a direct DB query using the user's last-seen tweet ID as a lower bound.
Memory estimate: 800 entries x 20 bytes per entry x 25 million active cached timelines = 400 GB. A Redis cluster handles this without drama.
What Breaks First
Fan-out queue pressure. Mid-tier accounts with 500,000 followers still generate 500,000 Redis writes per tweet. Several such accounts tweeting simultaneously fills the Kafka topic faster than workers can drain it. Fix: auto-scale fan-out worker pods on queue depth. Shard Kafka by author_id so high-volume authors do not block everyone else.
Graph service becomes a hotspot. Every fan-out call enumerates followers. Cache follower lists in Redis with a short TTL (a few minutes). Shard the follows table by followee_id for the "who follows me" query and by follower_id for the "who am I following" query. You need both directions.
Cold timeline on login. When the cache misses, reconstructing the timeline means querying the tweet DB for every followed account since the last visit. This is the most expensive operation in the system. A smarter approach: store the user's last-seen tweet ID. On cold load, query only tweets newer than that ID from each followed user's shard. This turns O(n) full scans into O(n) bounded point-in-time reads.
The Tradeoffs Your Interviewer Wants to Hear
| Decision | Fan-out on Write | Fan-out on Read | Hybrid |
|---|---|---|---|
| Read latency | O(1) from cache | O(n followees) | O(1) + small merge |
| Write cost | O(followers) per tweet | O(1) | O(followers) for regular users only |
| Celebrity problem | Catastrophic | No problem | Solved by exclusion |
| Consistency | Eventually consistent (async) | Stronger (pull is live) | Eventually consistent |
State the consistency model explicitly. Twitter timelines are eventually consistent. A follower might see your tweet 200ms after you post. For a social feed, that is fine. For a financial transaction, it is not. Voice the assumption and your interviewer will respect it. Candidates who silently assume strong consistency in async systems tend to design for correctness at the cost of availability.
For a broader look at the push-vs-pull cost structure, the analysis in The Trade-off Maze maps directly onto this decision. And the hashing mechanics behind Redis's O(1) lookups are covered in Hash Table Time Complexity if the interviewer probes that direction.
How to Pace the 45 Minutes
| Minute | Focus |
|---|---|
| 0 to 5 | Requirements and clarifications. Ask before drawing. |
| 5 to 10 | Capacity estimation. Compute fan-out QPS explicitly. |
| 10 to 20 | High-level architecture. Services and data flow, not database internals. |
| 20 to 35 | Feed generation deep dive. Fan-out on write, the celebrity problem, the hybrid fix. |
| 35 to 45 | Scaling bottlenecks, tradeoffs, optional ranking layer. |
Do not spend 30 minutes drawing boxes. Spend 30 minutes on the fan-out decision. The architecture boxes are mostly table stakes. The hybrid model reasoning is what separates a strong hire from a hire.
Voice the tradeoff out loud: "Fan-out on write gives O(1) reads but creates catastrophic write amplification for accounts with millions of followers. The hybrid model fixes this by skipping fan-out for those accounts and merging their tweets at read time. The merge is cheap because the celebrity follow set is small." That is 40 seconds. It covers the problem, the solution, and the reasoning. If your interviewer wants to go deeper, they will tell you.
Before Your System Design Interview
- The home timeline is read-heavy. Cache first, query second.
- Fan-out on write gives fast reads but collapses under celebrity traffic.
- Fan-out on read is simple but scales badly as followee counts grow.
- The hybrid model solves both: push for regular accounts, pull-and-merge for celebrities above a follower threshold.
- Redis sorted sets store pre-computed timelines, capped at 800 entries per user.
- Kafka decouples tweet writes from fan-out. A tweet write returns immediately; fan-out catches up asynchronously.
- Snowflake IDs give you sortable, globally unique tweet IDs without coordination overhead.
- Use cursor-based pagination. Offset pagination skips posts on a live feed.
- State your consistency model. Eventual consistency is standard for social feeds.
System design interviews reward structured thinking more than perfect answers. State a tradeoff, defend it, and ask "want me to go deeper?" That loop is what top-quartile candidates do.
SpaceComplexity runs voice-based mock system design interviews where the AI interviewer pushes back on your fan-out choice, asks you to estimate Redis memory on the fly, and probes your consistency assumptions. If you want to practice this kind of structured reasoning out loud before the real thing, that is exactly what it is built for.
Further Reading
- The Architecture Twitter Uses to Deal with 150M Active Users (High Scalability, 2013). The primary source for Twitter's actual Redis and fan-out architecture.
- Twitter's Recommendation Algorithm (X Engineering Blog). Official open-source release of the ranking system.
- Designing Twitter: A System Design Interview Question (GeeksforGeeks). Solid reference for the interview format.
- Design a News Feed System (ByteByteGo). Chapter-length treatment of both Facebook and Twitter variants.
- Designing Data-Intensive Applications (Kleppmann). Chapter 11 covers stream processing and fan-out patterns with rigorous analysis.