URL Shortener System Design: The Interview That Tests Everything
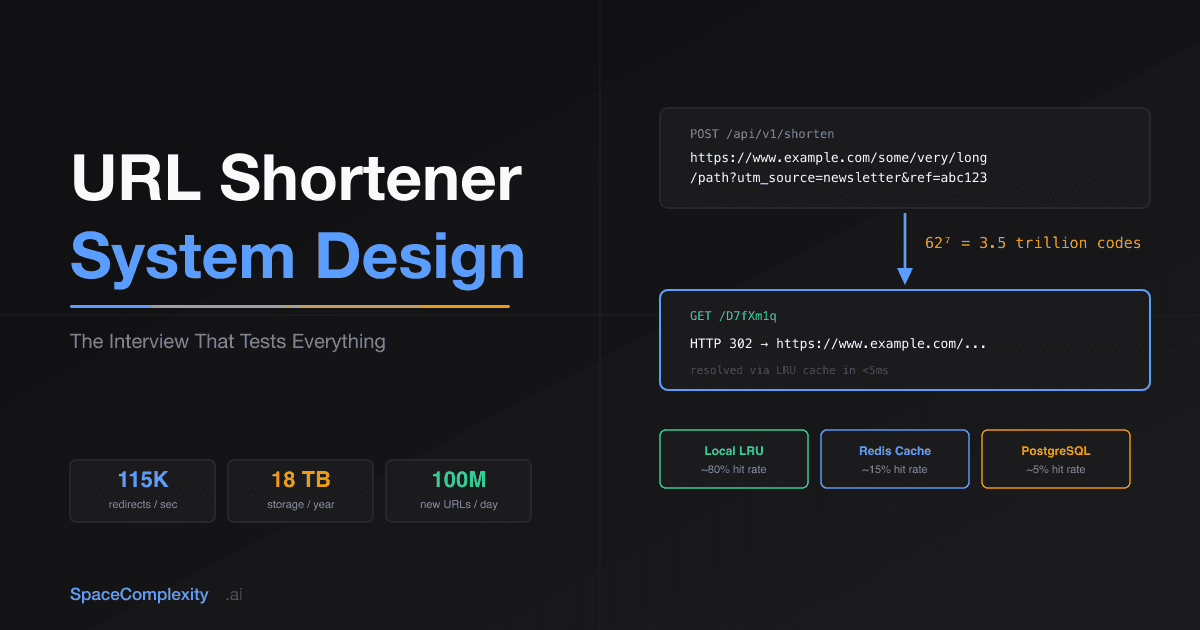
- Seven characters covers 3.5 trillion codes:
62^7via base62 encoding gives 96 years of runway at 100 million new URLs per day. - Counter-based generation beats hashing: assigning each URL an auto-incremented integer eliminates collision retries; use Redis
INCRwith range allocation for distributed resilience. - 302 over 301 if analytics matter: a 301 permanent redirect caches at the browser, bypassing your servers and making click tracking impossible.
- Cache aggressively with LRU eviction: the top 20% of URLs absorb 80% of reads; a tiered Redis cache in front of the database keeps the redirect path in single-digit milliseconds.
- Decouple analytics writes: log click events to a queue (Kafka, SQS) and consume asynchronously so analytics never block the redirect response.
- Lazy expiry as the default: check
expires_aton read and return 410 Gone if expired; active cleanup adds operational complexity without clear benefit unless storage is a hard constraint.
Seven characters. That's all TinyURL gives you. And that number is not a guess. It falls out of a single calculation that shapes every architectural decision downstream.
The URL shortener system design is the canonical warm-up interview question, and almost every candidate underestimates it. It touches distributed ID generation, caching strategy, read/write imbalance, database indexing, and asynchronous pipelines. All in a problem that initially sounds like "just store a key and a value." Get the scope right and you can walk through the whole interview methodically. Miss the scope and you spend forty minutes designing a system for the wrong scale.
Requirements First, Architecture Second
Don't draw boxes until you've confirmed scope. The urge strikes early. Resist it. For a URL shortener, ask:
- Do we need custom aliases? ("tinyurl.com/my-brand")
- Do links expire? If so, by user configuration or global TTL?
- Do we track analytics: click counts, referrer, device?
- Is this public or auth-gated?
The answers change the design materially. Analytics means a decoupled write path. Expiry means TTL fields and cleanup logic. Custom aliases mean reservation and collision handling on top of the standard generation path.
Non-functional requirements to state before anything else:
- Availability over consistency. A redirect failing is worse than briefly serving a cached URL.
- Read-heavy. Reads outnumber writes 100:1 or more on any popular service.
- Low latency. Redirects should resolve in under 100ms, globally.
- Durability. A short URL must never silently disappear.
The Math That Drives Every Decision
Estimate before you draw.
Writes: 100 million new URLs per day. That's roughly 1,200 writes per second.
Reads: At a 100:1 read-to-write ratio, 10 billion redirects per day, or about 115,000 reads per second.
Storage: Each URL record is around 500 bytes (long URL, short code, timestamps, user ID). 100 million records per day is 50 GB daily, 18 TB per year. Manageable with a single partitioned database.
Code space: With base62 encoding (a-z, A-Z, 0-9 = 62 characters), a 7-character code gives you:
62^7 = 3,521,614,606,208 ≈ 3.5 trillion unique codes
At 100 million new URLs per day, you won't exhaust that space for 96 years. Seven characters is not arbitrary. It's a deliberate minimum.
 6 characters runs out in under two years at 100M URLs/day. 7 characters lasts 96. The math makes the decision.
6 characters runs out in under two years at 100M URLs/day. 7 characters lasts 96. The math makes the decision.
Three Ways to Generate a Short Code
This is the most interesting decision in the interview, and where candidates tend to improvise instead of reason.
Option 1: Hash the long URL. Take MD5 or SHA-256 of the long URL, encode the first 7 characters in base62.
import hashlib def shorten(long_url: str) -> str: digest = hashlib.md5(long_url.encode()).digest() n = int.from_bytes(digest[:6], 'big') return to_base62(n)[:7]
Problem: two different long URLs can produce the same 7-character prefix. You need a database uniqueness check on every write, and a retry loop for collisions. Under sustained load, those checks pile up. A Bloom filter can front-run the DB check (filter miss = definitely not in DB, filter hit = check DB), but retry logic remains.
Option 2: Random code with a uniqueness check. Generate a random 7-character base62 string, check the database, retry on collision. Simple but brittle. It also ages poorly: collision probability climbs as the table fills, and retries become more frequent at exactly the worst time.
Option 3: Counter-based with base62 encoding. This is what production systems use. Assign every new URL a globally unique integer, convert it to base62. No collisions possible. No retries.
BASE62 = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" def to_base62(n: int) -> str: if n == 0: return BASE62[0] digits = [] while n: digits.append(BASE62[n % 62]) n //= 62 return ''.join(reversed(digits))
The only hard problem with a counter is making it distributed. A single Redis INCR is atomic and returns a globally unique integer, but it's a single point of failure. (Redis goes down. Not often. But eventually.) Two better options:
- Range allocation: Each URL generation server reserves a block of IDs from a coordinator (Zookeeper, etcd, or a dedicated DB table). Server A gets 1 to 1,000,000, Server B gets 1,000,001 to 2,000,000, and so on. A server works through its range locally with no coordination at all. When it runs out, it fetches a new range. One coordinator request per million URLs.
- Snowflake-style IDs: Combine a millisecond timestamp, machine ID, and per-machine sequence number into a 64-bit integer. No central coordinator. The catch: Snowflake IDs are too large for a 7-character base62 code (you need ~8), and they encode generation time, which leaks information.
For most interviews, Redis INCR with range allocation as the production fix is the cleanest answer. Name the failure mode (Redis goes down, it just hasn't yet) and the fix (range allocation), then move on.
 No collision possible. No retry loop. The counter guarantees uniqueness by construction. The SPOF annotation shows where range allocation fixes the single Redis dependency.
No collision possible. No retry loop. The counter guarantees uniqueness by construction. The SPOF annotation shows where range allocation fixes the single Redis dependency.
The Data Model
Keep this simple.
CREATE TABLE urls ( id BIGINT PRIMARY KEY, -- the counter value short_code VARCHAR(7) UNIQUE NOT NULL, -- base62 of id long_url TEXT NOT NULL, created_at TIMESTAMP NOT NULL DEFAULT NOW(), expires_at TIMESTAMP, -- null = never expires user_id BIGINT -- null = anonymous );
Every redirect is a lookup by short_code. That column needs an index. The id column is the auto-incremented primary key that drives your base62 encoding. Analytics (click counts, referrer, device) go in a separate table because they are write-heavy and you don't want them on the critical redirect path.
NoSQL (DynamoDB, Cassandra) works just as well here. The access pattern is a pure key-value lookup: give me the long_url for this short_code. No joins. No transactions. If you go NoSQL, short_code is your partition key.
API Design and the 301 vs 302 Trap
Two endpoints cover the core product.
POST /api/v1/shorten
Body: { "long_url": "https://...", "custom_alias": "optional", "expires_at": "optional" }
Response: { "short_url": "https://tinyurl.com/D7fXm1q" }
GET /{short_code}
Response: HTTP 301 or 302 redirect to long_url
The choice between 301 and 302 is the most common trap in this interview. A 301 (Permanent Redirect) tells the browser to cache the result forever. The second time a user clicks that link, the request never reaches your servers. That's excellent for latency and terrible for analytics: you can't count clicks you never see. Your analytics dashboard will show flattering zeros forever. A 302 (Found / Temporary Redirect) sends every click through your servers, enabling full analytics but adding a round-trip on every request. Most services choose 302, but you need to say why, or you'll get the follow-up.
URL Shortener System Design Architecture
 Left: the read path handles 115K req/s through three cache layers. Right: the write path runs at 1.2K req/s with analytics fully decoupled via Kafka. The two paths share the same Primary DB but never block each other.
Left: the read path handles 115K req/s through three cache layers. Right: the write path runs at 1.2K req/s with analytics fully decoupled via Kafka. The two paths share the same Primary DB but never block each other.
The redirect path is the critical path. It runs at 115,000 requests per second and needs to be fast.
- Client requests
GET /D7fXm1q - Load balancer routes to one of N redirect servers
- Server checks its local in-process LRU cache
- Cache hit: return 302 immediately. Done. No database involved. Maybe 3ms total.
- Cache miss: query the shared Redis cluster, populate local cache, return 302
- Redis miss: query the database, populate Redis, return 302
A well-tuned cache eliminates the database from 90% of redirects. The 80/20 rule applies hard here: a small fraction of URLs absorb nearly all traffic. Cache 20% of your URL space in Redis and you handle the overwhelming majority of requests without touching the database. An LRU eviction policy keeps the hottest links in memory without manual management.
Where the Bottlenecks Actually Are
Reads at scale. Redis handles most of it. For cache misses hitting the database, add read replicas. Writes are light (1,200/sec) and go to a single primary. Reads are heavy (115K/sec after cache hits are subtracted) and can fan out across replicas. Shard by short_code hash if you need horizontal write scaling, though you probably won't for several years.
Analytics writes. If you track every click, that's 10 billion write events per day. You cannot do this synchronously in the redirect path. Log each click to a message queue (Kafka, SQS), and process it asynchronously in a consumer that batches inserts into a separate analytics store. The redirect stays in the single-digit millisecond range. Click counts lag by a few seconds. That tradeoff is completely fine. The redirect cares about being fast. Your analytics dashboard can handle a two-second wait.
Geographic latency. A redirect is latency-sensitive. Users in Frankfurt hitting a server in Virginia adds 90ms before anything else happens. The fix: regional Redis caches pre-warmed with popular URLs, regional database read replicas, and optionally a CDN layer for the redirect response itself. Regional caches populate from the origin on miss and stay synchronized via async replication.
 Three independent regions. Most traffic resolves from local Redis without ever crossing an ocean. The US Primary DB replicates asynchronously. A Frankfurt user clicking a link should not wait for Virginia.
Three independent regions. Most traffic resolves from local Redis without ever crossing an ocean. The US Primary DB replicates asynchronously. A Frankfurt user clicking a link should not wait for Virginia.
Expiry and Cleanup
Two options, one clear winner for the interview.
Lazy expiry: Check expires_at on every read. Return 410 Gone if expired. Never run a delete. Storage grows but you need no background jobs and no operational complexity.
Active cleanup: A background worker (cron or queue-driven) deletes expired records periodically. Keeps storage bounded but adds an operational surface area.
State both, then choose lazy expiry as the default. Active cleanup becomes necessary only if storage is constrained or if you're charging users per stored URL.
How to Communicate This in 45 Minutes
The URL shortener interview rewards candidates who move methodically and narrate tradeoffs. A rough time budget:
- Minutes 0 to 5: Requirements confirmed. Non-functional requirements stated. Scale estimated.
- Minutes 5 to 15: Short URL generation approach chosen. Counter plus base62. Distributed counter failure mode named and resolved.
- Minutes 15 to 25: Data model sketched. API endpoints defined. 301 vs 302 addressed.
- Minutes 25 to 35: Architecture drawn. Cache hierarchy explained. Analytics path decoupled.
- Minutes 35 to 45: Deep dive on whichever component the interviewer pulls on.
Every design decision you state should be immediately followed by the tradeoff you accepted to get there. "I'm using a counter over hashing because counters have no collision risk, at the cost of needing a distributed counter coordinator" is worth more to an interviewer than the right answer stated without explanation. They want to see that you understand the design space, not just that you landed on a reasonable node in it.
If you get to geographic distribution and async analytics, you're ahead. If you're still drawing the basic architecture at minute 30, you went too deep too early.
The narration skill is the hardest part to train on paper. If you want to practice the full forty-five minutes out loud with rubric feedback, SpaceComplexity runs voice-based mock system design interviews that score you on exactly this.
Quick Recap
- Requirements first. Custom aliases, expiry, and analytics each add a distinct design component. Confirm before drawing.
- 62^7 = 3.5 trillion unique codes. Seven characters is the minimum safe choice.
- Counter plus base62 is the standard approach. Redis
INCRfor simplicity, range allocation from etcd or Zookeeper for production resilience. - 301 caches at the browser (kills analytics). 302 routes every request through your servers (enables analytics). Choose based on whether click tracking is a requirement.
- Cache aggressively. 80% of reads hit 20% of URLs. An LRU Redis layer in front of the database keeps the read path in single-digit milliseconds.
- Decouple analytics writes. Log to a queue, consume asynchronously. Never write click events on the synchronous redirect path.
- Lazy expiry is simpler. Active cleanup is necessary only if storage is a hard constraint.
Further Reading
- URL Shortening on Wikipedia -- history and overview of the problem
- System Design: URL Shortening Service on GeeksforGeeks -- comprehensive walkthrough with capacity math
- Consistent Hashing on Wikipedia -- the sharding strategy that keeps hot-spot partitions manageable
- Snowflake ID on Wikipedia -- Twitter's distributed ID generation scheme, the alternative to range-based counters
- Design a URL Shortener on ByteByteGo -- Alex Xu's canonical chapter covering this exact problem in depth