What Is a Code Point? The Unicode Number Behind Every String Length Bug
- Code points are unique integers assigned to every Unicode character;
U+1F600is a code point, not a byte or encoding unit. - Python 3's
len()counts code points directly, making it the safest language for string problems involving emoji. - JavaScript and Java use UTF-16 internally, so
.lengthcounts code units; emoji require a surrogate pair and count as 2, not 1. - Go's
len()returns bytes; uselen([]rune(s))or afor rangeloop to count code points correctly. - Surrogate pairs are two UTF-16 code units encoding one supplementary character; splitting them mid-string corrupts output.
- String reversal, palindrome checking, and substring extraction all silently break on emoji when you iterate by code unit instead of code point.
You write len(s) to count the characters in a string. It works great. You feel good. Then someone passes in an emoji and your palindrome checker returns the wrong answer, your string reversal corrupts the output, and your character frequency map produces phantom entries that shouldn't exist.
The algorithm is fine. Your bug is in a mental model you built at age twelve when you learned that a character fits in a byte. It has been quietly wrong ever since.
A code point is the thing you were actually missing.
Every Character Is a Number
Unicode is a standard that assigns a unique integer to every character humans write: every letter in every alphabet, every punctuation mark, every mathematical symbol, every emoji. That integer is the code point.
Code points are written as U+ followed by a hexadecimal value. The letter A is U+0041. The Greek letter π is U+03C0. The grinning face emoji is U+1F600. Not a byte. Not a symbol. A number in a very large table.
The Unicode standard defines 1,114,112 possible code points, from U+0000 to U+10FFFF. About 150,000 are currently assigned. The rest are waiting, presumably for future emoji that describe even more specific emotions.
You can inspect any character's code point directly:
# Python ord('A') # 65 (0x0041) ord('π') # 960 (0x03C0) ord('😀') # 128512 (0x1F600)
// JavaScript 'A'.codePointAt(0) // 65 'π'.codePointAt(0) // 960 '😀'.codePointAt(0) // 128512
Code points are abstract. They are integers in a table. How they get stored in memory is a completely separate question, and that separation is where most string bugs live.
The BMP: Where Normal Characters Live
Unicode divides its 1,114,112 code points into 17 planes of 65,536 code points each.
Plane 0 is the Basic Multilingual Plane (BMP), covering U+0000 to U+FFFF. It contains virtually every character used in modern written languages: all Latin, Greek, Cyrillic, Arabic, Hebrew, CJK ideographs, and thousands more. If a character lives in the BMP, its code point fits in a single 16-bit integer.
Planes 1 through 16 are supplementary planes. Most emoji live in Plane 1 (the Supplementary Multilingual Plane), starting around U+1F300. Ancient scripts, musical notation, and extended CJK characters live here too.
This geography matters because the dominant internal string encoding in modern languages is UTF-16, and UTF-16 cannot fit supplementary characters in a single 16-bit slot. That 16-bit assumption was baked in when emoji didn't exist and the designers thought 65,536 characters would be plenty. They were wrong in a way that still costs developers time in interviews in 2025.
Code Point vs Code Unit vs Byte
These three terms get conflated constantly. They are not the same thing.
A code point is the abstract character number. U+1F600 is a code point. There is exactly one per character, regardless of how it is stored.
A code unit is the smallest chunk in a specific encoding. UTF-16 uses 16-bit (2-byte) code units. UTF-8 uses 8-bit (1-byte) code units.
A byte is 8 bits.
For BMP characters, UTF-16 uses one code unit. For supplementary characters (U+10000 to U+10FFFF), UTF-16 needs two code units called a surrogate pair: a high surrogate in the range U+D800-U+DBFF followed by a low surrogate in U+DC00-U+DFFF. The emoji U+1F600 becomes two 16-bit code units when encoded in UTF-16.
UTF-8 works differently. It uses a variable number of bytes per code point: 1 byte for ASCII, 2 bytes for Latin Extended and Greek, 3 bytes for most BMP characters, and 4 bytes for supplementary characters. The same emoji, U+1F600, takes 4 bytes in UTF-8.
The critical fact for interviews: when a language reports string length, it usually counts code units, not code points. This is the gap between what you expect and what you get.
Here is how the whole stack looks for one emoji:

One glyph. Three different numbers depending on which layer you ask.
What Each Language Actually Counts
This is the table that trips people up in real interviews.
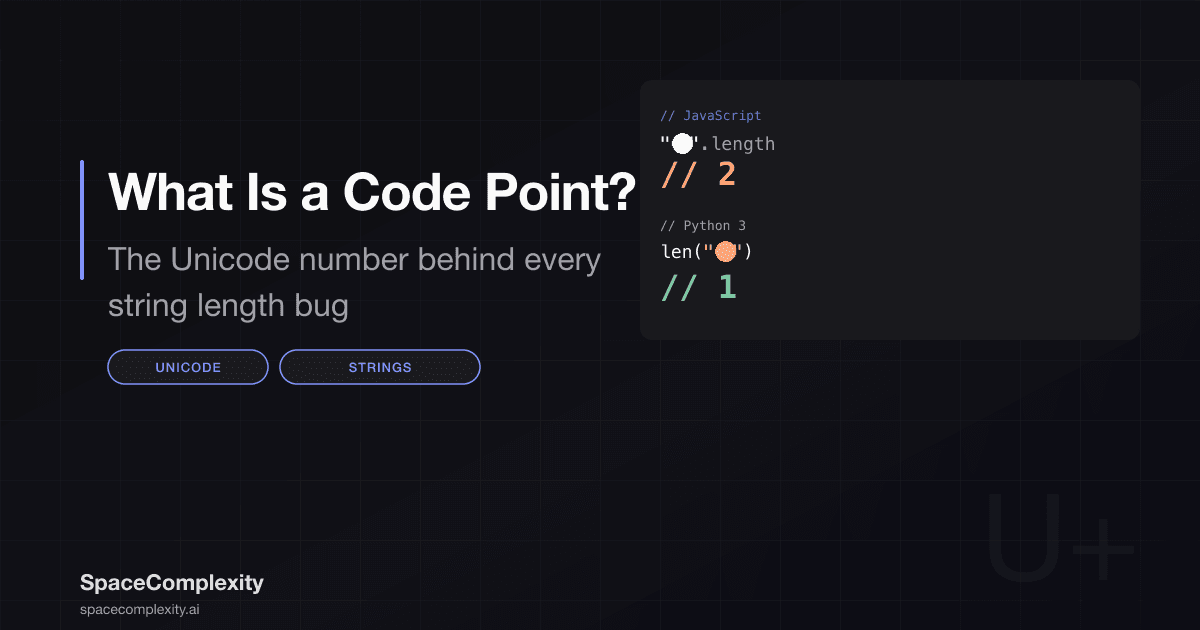
JavaScript and Java store strings as UTF-16 internally. .length in both languages counts UTF-16 code units. Because emoji are supplementary characters requiring a surrogate pair, they count as two. This is not a bug. It is a deliberate, documented decision. It is still painful.
"😀".length // 2, not 1 "hello".length // 5 "hello😀".length // 7, not 6
"😀".length() // 2 "😀".codePointCount(0, "😀".length()) // 1
The spread operator in JavaScript is code-point aware, so it gives you the correct count:
[..."😀"].length // 1 [..."hello😀"].length // 6
The JavaScript gotchas post covers several more places where this assumption quietly corrupts output.
Python 3 is the friendliest for code point work. Python stores strings as sequences of code points, and len() counts them directly. No edge cases. No surprises. Just the number you expected.
len("😀") # 1 len("hello😀") # 6
Iterating a Python 3 string gives you code points one at a time, every time. The Python gotchas post is worth reading anyway since mutability and default argument bugs cause more failures, but string length is not one of them.
Go is the trickiest to remember. A Go string is a read-only byte slice. Calling len() returns bytes, not code points.
len("😀") // 4 (four UTF-8 bytes) len("hello") // 5 (ASCII, so bytes == code points here)
To work with code points in Go, convert to []rune (rune is Go's alias for int32, representing a single code point) or use a for range loop, which decodes one rune per iteration:
len([]rune("😀")) // 1 for i, r := range "hello😀" { fmt.Printf("index %d: U+%04X\n", i, r) } // index 0: U+0068 (h) // index 1: U+0065 (e) // ... // index 5: U+1F600 (😀)
Note how the byte index jumps from 5 to 9 when it hits the emoji: four bytes, one rune.
Rust takes the most principled stance. str::len() returns bytes. Rust will not let you index into a string by integer without an explicit conversion, which prevents an entire class of mid-surrogate accidents. To count code points, call .chars().count():
"😀".len() // 4 (bytes) "😀".chars().count() // 1
Rust's char type is a 32-bit value representing exactly one Unicode scalar value. The compiler forces you to say what you are counting. Whether this is ergonomic or just aggressively honest depends on your mood.
Here is the full picture at a glance:
| Language | Encoding | len("😀") | Code point count |
|---|---|---|---|
| Python 3 | variable (PEP 393) | 1 | len(s) directly |
| JavaScript | UTF-16 | 2 | [...s].length |
| Java | UTF-16 | 2 | s.codePointCount(0, s.length()) |
| Go | UTF-8 bytes | 4 | len([]rune(s)) |
| Rust | UTF-8 bytes | 4 | s.chars().count() |
Where This Breaks Your Interview Code
Most LeetCode problems guarantee ASCII input. Fine. Realistic. But interviews at large companies sometimes include supplementary-plane characters as edge cases, and a solution that mishandles them signals incomplete understanding of strings.
Here are the four patterns that come back to haunt you:
String reversal. Reversing a UTF-16 string by swapping code units splits surrogate pairs and produces corrupted output. The naive approach in JavaScript:
// Broken on emoji: splits surrogate pairs "hello😀".split("").reverse().join("") // Correct: code-point aware split [..."hello😀"].reverse().join("") // "😀olleh"
The string coding interview guide covers the correct reversal template in detail.
Palindrome checking. If your palindrome check uses .length and integer indices in JavaScript or Java, it can miscalculate the midpoint on strings with supplementary characters. The middle of "A😀A" is not index 1. It is a surrogate unit with nothing on either side of it, and your two-pointer will happily try to compare them.
Character frequency counting. Building a frequency map by iterating with numeric indices in JavaScript produces wrong counts for supplementary characters. Index i might land inside a surrogate pair, producing two phantom entries instead of one. You then tell the interviewer your solution handles all Unicode correctly. You are wrong.
Substring extraction. s.slice(0, n) in JavaScript counts code units. Slicing into the middle of a surrogate pair produces an invalid UTF-16 string with an unpaired surrogate. That string will fail in any downstream comparison, display as a replacement character, and generally behave like a small fire.
The safe pattern for JavaScript is to convert to a code-point array first:
const chars = [...str]; // one entry per code point const n = chars.length; // actual character count const reversed = chars.reverse().join("");
The safe pattern for Java uses codePoints():
int[] codePoints = str.codePoints().toArray(); int n = codePoints.length;
If you are writing Python, using Go's for range, or Rust's .chars(), you are already iterating by code point. No adapter needed.
Practicing with spoken explanation under time pressure, the way SpaceComplexity delivers mock interviews, makes you more likely to catch this class of bug verbally before an interviewer does. It is much easier to spot in your narration than in silent code review.
Code Points Are Not the Last Layer
Here is the part that makes people laugh or cry depending on how much Unicode they have shipped.
Code points are not the last level of abstraction. Some visible characters are composed of multiple code points combined: a base character plus a diacritical mark, an emoji plus a skin tone modifier, or a family emoji built from several individual emoji joined by zero-width joiners. These combinations are called grapheme clusters, and they are what a user sees as a single character.
"🤦🏼♂️" is one visible glyph. It is seven code points. It occupies even more code units in UTF-16.
That is: face-palm base emoji (U+1F926), medium-light skin tone modifier (U+1F3FC), zero-width joiner (U+200D), male sign (U+2642), variation selector-16 (U+FE0F), and two more hidden characters your editor is probably not showing you. All rendering as one thing on screen.
Most interview problems stop at code points. Getting code points right is almost always sufficient. Getting bytes right is sometimes required when working with encoded data. Getting grapheme clusters right is practically never tested. But knowing the layer exists prevents you from overclaiming that your "correct" character count is the same as what a user would count visually.
It usually isn't.
Further Reading
- Unicode Standard: the Unicode Consortium's official specification
- Unicode on Wikipedia: comprehensive overview of the standard and its history
- UTF-16 on Wikipedia: detailed explanation of surrogate pairs and the encoding scheme
- Python Unicode HOWTO: Python's official guide to Unicode support in Python 3
- It's Not Wrong That "🤦🏼♂️".length == 7: authoritative analysis of what "string length" means across encoding models