Design YouTube: The System Design Interview Blueprint
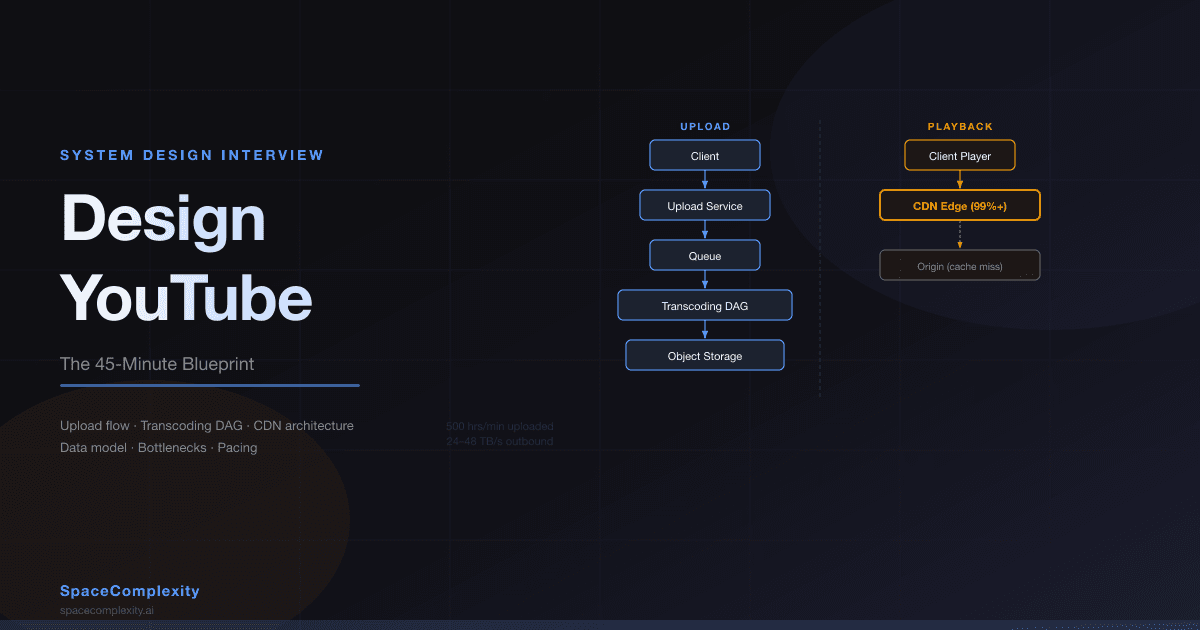
- Upload and playback paths are independent flows; a spike in either shouldn't degrade the other.
- Resumable uploads use chunked HTTP with Content-Range headers and a session ID so mobile drops never restart from byte zero.
- Transcoding is a DAG: split raw video into 20-second segments without re-encoding, transcode all in parallel, merge manifests last.
- Adaptive bitrate streaming outputs HLS for Apple and DASH for everything else; the player switches quality on 2-6 second segment boundaries without buffering.
- The CDN handles 99%+ of video bytes; API servers redirect, never proxy, so video bytes never touch your application tier.
- View count hot keys go through Redis INCR and batch-flush to PostgreSQL every 30 seconds, avoiding row-level lock contention on viral traffic.
- Pace 13 minutes for transcoding and CDN; that section generates the most follow-up questions and is where interviewers distinguish candidates.
Every minute, 500 hours of video land on YouTube. Your interviewer knows that number. So do you now. The question is whether you know what happens in the next five minutes after that upload hits a server, and why each decision in that chain was made.
This is the full system design interview walkthrough: requirements, architecture, data model, API, bottlenecks, and how to time it all in 45 minutes.
The Interview Before the Interview
Before you draw a single box, there is a minute or two of work that separates good candidates from great ones. The prompt is intentionally vague. Clarifying it is part of the test.
Spend the first five minutes turning "design YouTube" into a concrete scope:
Functional requirements (what the system does):
- Users upload videos. Uploads must be resumable (mobile networks drop).
- Users stream videos. Playback adapts to their network speed.
- Videos have titles, descriptions, and a view count.
- Likes and comments are "nice to have." Search and recommendations are out of scope.
Non-functional requirements (how it behaves under load):
- Available over consistent. A stale view count is fine. A video that won't play is not.
- Read-heavy by a wide margin. The upload-to-watch ratio is roughly 1:10,000.
- Video playback latency should feel instant. Upload processing latency of a few minutes is acceptable.
Write these on the board. They are your contract. Every later decision should trace back to them.
Back-of-the-Envelope: Why the CDN Exists
Most candidates skip estimation. Don't. It is the step that makes your architecture decisions look reasoned instead of cargo-culted. Your interviewer doesn't want to see you draw a CDN box because "you're supposed to." They want to see you derive why one is necessary.
Daily active users: ~120M
Videos uploaded: 500 hours/minute → 720K hours/day
Raw video (1 hr ≈ 1.5 GB): ~1 PB raw uploads/day
After transcoding 4 formats: ~4 PB stored/day
5-year storage: ~7 exabytes
Videos watched: ~1B hours/day
Concurrent streams: ~12M (1B hours / 24h / 3600s)
Each HLS segment ≈ 2 MB, fetched every 2-6 seconds
Outbound bandwidth needed: 12M × 2-4 MB/s ≈ 24-48 TB/s
Twenty-four to forty-eight terabytes per second cannot leave a single data center. That is not a "we need more servers" problem. That is a geographical distribution problem. This is why the CDN is not an optimization but a load-bearing component. Draw it that way.
Draw Two Flows. Keep Them Separate.
The whole system splits cleanly into two independent paths. Draw them side by side, not as one blob.

Upload flow on the left, playback on the right. They share almost nothing, and that is the point.
Most candidates draw one connected diagram where uploads flow into the same path as playback. That produces what the ProgrammerHumor crowd calls a "distributed monolith." You labeled it microservices. It is not.

The moment you route uploads through the same service handling playback at 24 TB/s.
These paths share almost nothing. That is intentional. A spike in uploads should not degrade playback for viewers, and vice versa. If you draw them as one flow in your interview, you have just told the interviewer that you don't understand why services are separated in the first place.
Upload: Chunked, Resumable, Queued
A 2-hour raw upload is around 3 GB. Sending it as one HTTP request is a bad idea on any network. Here is what actually happens:
The client splits the file into chunks, typically 5-50 MB each. Each chunk gets a checksum. The client opens a session, gets back an upload URL, and POSTs chunks with Content-Range headers. If the connection drops, it resumes from the last confirmed byte. No one is resending 2.9 GB because their phone lost wifi at mile 2.9.
# Step 1: initiate upload session POST /v1/uploads/initiate Body: { filename: "talk.mp4", size: 3221225472, mime_type: "video/mp4" } Response: { upload_id: "u_8xk2p", upload_url: "/v1/uploads/u_8xk2p" } # Step 2: push chunks (repeat until complete) PUT /v1/uploads/u_8xk2p Content-Range: bytes 0-52428799/3221225472 Body: <5 MB binary> # Server acknowledges and tells client where to continue 308 Resume Incomplete Range: bytes=0-52428799
That is Google's resumable upload protocol and the open TUS specification in a nutshell. Both work the same way: the server maintains session state keyed on upload ID, the client never has to restart from byte zero.
Once all chunks arrive, the upload service assembles them in object storage and drops a message on a queue. The video is now in state processing. The client gets a webhook or can poll for status.
Transcoding: The Expensive Heart of the System
This is where most candidates wave their hands and say "workers do the transcoding." That is not specific enough. Your interviewer will dig in here, and this is the section worth spending the most time on.
Raw video arrives in whatever codec the user's camera used (H.264, HEVC, VP9, ProRes). You need to serve it to a phone on 3G, a laptop on fiber, and a 4K TV on gigabit ethernet. You solve this with adaptive bitrate streaming, which means transcoding the same video into many resolutions and splitting each into 2-6 second segments.
The output format depends on the device. Apple requires HLS (.m3u8 manifest + .ts segments). Everything else prefers DASH (.mpd manifest + .mp4 segments). You produce both.
The naive approach: one worker processes each video end-to-end. A 2-hour raw upload at 4 resolutions would take hours to transcode serially. Nobody wants their upload sitting in a queue because one worker is chugging through some creator's uncut four-hour gaming session.
The right approach: a DAG of parallel tasks.

One 2-hour video becomes 1,440 independent transcoding tasks. Workers autoscale off queue depth.
Each node in that graph is an independent task on the message queue. A 2-hour video becomes roughly 360 segments × 4 resolutions = 1,440 transcoding tasks, all running simultaneously across a worker pool. Workers autoscale off queue depth. A DAG scheduler handles the dependency: the manifest-building step only fires after all segment tasks complete.
The split-before-transcode trick is key. FFmpeg can split without re-encoding (-c copy), which takes seconds. The expensive codec conversion (CPU-bound and takes real time) is then massively parallel across the cluster.
Streaming: CDN Is the Product
When the viewer hits play, here is the sequence:
- The player fetches the master manifest from the CDN.
- The manifest lists every quality level with bandwidth estimates.
- The player picks a starting quality and begins fetching segments.
- Every few seconds, the player measures download speed and switches quality if needed.
# HLS master manifest
#EXTM3U
#EXT-X-STREAM-INF:BANDWIDTH=6000000,RESOLUTION=1920x1080
https://cdn.example.com/v/abc123/1080p/playlist.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=2500000,RESOLUTION=1280x720
https://cdn.example.com/v/abc123/720p/playlist.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=800000,RESOLUTION=854x480
https://cdn.example.com/v/abc123/480p/playlist.m3u8
Quality switching happens on segment boundaries. The viewer's player downloads the next chunk at a lower resolution before the current one finishes. Done correctly, the viewer never sees a buffer spinner.
The popular vs. long-tail split is the CDN tradeoff worth raising explicitly:

The top 20% of videos account for about 80% of watch time. Pre-populate those. Pull the rest on demand.
- The top 20% of videos account for roughly 80% of watch time. These get proactively distributed to edge nodes globally before any user requests them.
- Long-tail videos are pulled on-demand. The first viewer in a region causes a cache miss. Every subsequent viewer in that region hits the edge cache.
This split matters because it drives your CDN cost model. Proactive push for the popular tier is expensive in storage per edge node but eliminates the cache-miss latency spike on viral videos.
Three Tables. That's the Data Model.
Three core entities. Resist the urge to design a full schema. Sketch the tables, call out the important fields, and move on. You have better things to spend time on.
users ( user_id UUID PRIMARY KEY, username VARCHAR(50) UNIQUE, email VARCHAR(255) UNIQUE, created_at TIMESTAMP ) videos ( video_id UUID PRIMARY KEY, user_id UUID REFERENCES users, title VARCHAR(200), status ENUM('uploading','processing','available','failed'), duration_s INT, manifest_url TEXT, -- CDN path to master HLS/DASH manifest raw_url TEXT, -- Object storage path for raw upload view_count BIGINT DEFAULT 0, created_at TIMESTAMP ) video_formats ( video_id UUID REFERENCES videos, resolution VARCHAR(10), -- '1080p', '720p', etc. format VARCHAR(10), -- 'hls', 'dash' manifest_url TEXT, PRIMARY KEY (video_id, resolution, format) )
Storage tier decisions:
- User and video metadata: PostgreSQL, sharded by
user_idorvideo_idonce you hit single-node limits - Raw video and transcoded segments: object storage (S3, GCS). The segments themselves never touch a database row.
- View counts: aggregated in Redis, batch-flushed to Postgres every 30 seconds (more on why below)
Four Endpoints, Two Separate Paths
The upload path and the playback path use different endpoints that talk to different backend systems.
POST /v1/videos/upload/initiate → { upload_id, upload_url }
PUT /v1/videos/upload/{upload_id} → 308 with Range, or 200 complete
GET /v1/videos/{video_id} → video metadata + manifest URLs
GET /v1/videos/{video_id}/manifest → 302 redirect to CDN manifest URL
One important rule: the GET manifest endpoint redirects. It does not proxy the manifest bytes. Your API server tells the client where the CDN file lives. The client's player fetches it directly from the CDN. Your API servers never touch video bytes. If they did, your compute bill would make your finance team faint.
Find the Failure Modes Before They Do
Volunteer these. Don't wait to be asked.
View count hot keys. A video goes viral. Ten million concurrent viewers each trigger a view count write. Writing to a Postgres row on every request serializes on a single row lock and brings your database down. The fix: write increments to Redis with INCR (O(1), atomic, in-memory), then flush aggregated counts to Postgres in batches every 30 seconds. The count is slightly stale. For a view counter, that's fine. See hash table internals for why Redis hash operations stay O(1) at this scale.
Upload ingestion bandwidth. 500 hours of raw video per minute is roughly 12 GB/s of inbound traffic globally. You handle this with geographically distributed upload endpoints that write directly to a regional object store. You do not route raw video through a single ingestion service. That single service becomes a very expensive, very unreliable funnel.
Transcoding queue spikes. A live event ends and 10,000 creators upload simultaneously. Your task queue depth spikes. Workers need to autoscale off queue depth metrics, and you want priority lanes: a 30-second clip should not wait behind a 4-hour raw upload.
CDN miss on new viral video. A video goes viral before edge caches warm up. Every viewer causes a miss, all hitting your origin simultaneously. Mitigate this with a multi-tier CDN (regional cache between edge and origin) and by detecting traffic spikes early to trigger proactive distribution.
The 45-Minute Pacing Problem
The time budget matters. Candidates who run out of time before reaching the CDN and transcoding sections almost always lose points on the most interesting components.
Here is how to pace it:
| Phase | Time | What you cover |
|---|---|---|
| Requirements and scope | 0-5 min | Functional + non-functional, what's out of scope |
| Back-of-the-envelope | 5-10 min | Bandwidth number, storage numbers |
| High-level architecture | 10-20 min | Two flows drawn and labeled |
| Upload and transcoding | 20-33 min | Chunked upload + DAG pipeline in detail |
| CDN, data model, API | 33-42 min | Streaming, tables, four endpoints |
| Bottlenecks + questions | 42-45 min | View counts, hotkeys, queue spikes |
The single most common mistake is spending 20 minutes on the data model and API, then having to rush the transcoding section. The transcoding pipeline is where most candidates get asked follow-up questions, and where you show you understand distributed computation, not just boxes and arrows.
The data model took two minutes to sketch above. That's about right.
Practice the pacing out loud before your interview. Drawing boxes silently in your head does not train you for a 45-minute spoken walkthrough. SpaceComplexity runs voice-based system design mock interviews with rubric-based feedback on your tradeoff reasoning and communication. Ten mock sessions will do more for your timing than 10 hours of reading.
The Short Version
- Split upload and playback into independent flows. A spike in one should not affect the other.
- Resumable uploads use chunked HTTP with
Content-Rangeheaders and session IDs. TUS is the open standard. - Transcoding is a DAG of parallel tasks. Split first (cheap), transcode segments in parallel (expensive and parallelizable), merge manifests last.
- HLS for Apple, DASH for everything else. Segments are 2-6 seconds. The player adapts quality on segment boundaries.
- The CDN serves 99%+ of video bytes. Your servers never proxy video. They redirect to CDN URLs.
- Proactively distribute the top 20% of videos. Pull-cache the long tail.
- View counts aggregate in Redis and flush to the database in batches. Row-level locking on viral traffic will kill your database.
- Budget 13 minutes for the transcoding and CDN deep dive. That is where the interview is won.