Kruskal vs Prim: Graph Density Is the One Question That Decides
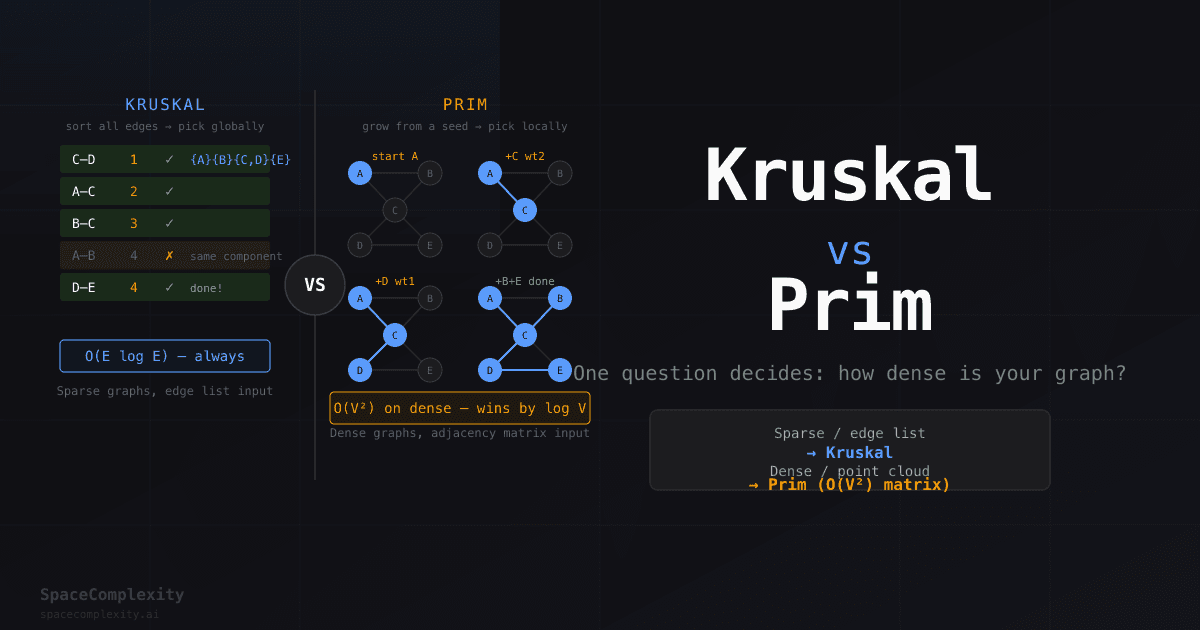
- Graph density is the decision: dense graphs favor Prim's O(V²) matrix variant; sparse graphs favor Kruskal's O(E log E) sort-and-union approach.
- Kruskal sorts all edges globally and uses Union-Find to skip cycle-creating edges, no adjacency structure required.
- Prim grows a tree locally from a seed vertex; the O(V²) matrix variant beats Kruskal on dense graphs by a full log factor.
- Disconnected graphs: Kruskal produces a spanning forest automatically; Prim silently returns an incomplete tree and needs an outer loop restart.
- Prim is structurally Dijkstra with the priority key changed from total path cost to the cheapest crossing edge, so it works with negative weights.
- k-clustering via MST: build with Kruskal, remove the k-1 heaviest edges; stop early after n-k edges added.
- On LeetCode 1584 (point cloud, complete graph), the O(n²) Prim matrix variant avoids generating and sorting all O(n²) edges.
You have a graph. It needs a minimum spanning tree. You've learned two algorithms for this problem: Kruskal's and Prim's. They're both correct, both greedy, both provably optimal. They produce the same total weight. They're basically two recipes for the same cake.
Because on the wrong graph type, one of them is several times slower. That is the one thing worth knowing before you write any code.
One Problem, One Theorem
A minimum spanning tree connects all V vertices using exactly V-1 edges, no cycles, and the minimum possible total weight. Multiple valid MSTs can exist when edge weights tie, but both algorithms find one.
Both proofs rest on the cut property. Split the vertices into any two non-empty sets. The minimum-weight edge crossing that partition is safe to include in any MST. Swap in a heavier edge crossing the same cut and the tree gets heavier, contradiction. Kruskal's and Prim's don't prove this independently. They just apply it in different orders.
 Running example: MST picks C-D(1), A-C(2), B-C(3), D-E(4). Total weight 10.
Running example: MST picks C-D(1), A-C(2), B-C(3), D-E(4). Total weight 10.
How Kruskal's Works: Sort Everything, Pick Greedily
Kruskal's is a global algorithm. It has no concept of "which vertex to expand next." It just wants the cheapest available edges.
- Collect all edges and sort them by weight, ascending.
- Walk through the sorted list. For each edge (u, v), check whether u and v are already connected. If not, add the edge.
That "check whether connected" step is Union-Find. Every time you add an edge you union the two components. Every time you inspect an edge, you call find(u) and find(v). If both return the same root, they're already in the same component, skip. If not, take the edge.
Union-Find does not detect cycles. It checks component membership. Cycle avoidance is a consequence: an edge between two vertices already in the same component would create a cycle, so you skip it. The algorithm never thinks about cycles explicitly. This trips people up every single time they first encounter it.
def kruskal(n, edges): # edges: list of (weight, u, v) edges.sort() parent = list(range(n)) rank = [0] * n def find(x): while parent[x] != x: parent[x] = parent[parent[x]] # path halving x = parent[x] return x def union(x, y): px, py = find(x), find(y) if px == py: return False if rank[px] < rank[py]: px, py = py, px parent[py] = px if rank[px] == rank[py]: rank[px] += 1 return True mst_weight = 0 edges_used = 0 for weight, u, v in edges: if union(u, v): mst_weight += weight edges_used += 1 if edges_used == n - 1: break return mst_weight
Complexity: Sorting the edges costs O(E log E). Union-Find operations over all edges cost O(E · α(V)), where α is the inverse Ackermann function (a constant for any real-world graph). The sort dominates. Total: O(E log E), or equivalently O(E log V) since E ≤ V².
 Edge C-D(1) first, A-B(4) skipped because A and B already share a component, done after 4 edges.
Edge C-D(1) first, A-B(4) skipped because A and B already share a component, done after 4 edges.
How Prim's Works: Grow a Tree, One Vertex at a Time
Prim's is a local algorithm. It picks a starting vertex and expands outward, always choosing the cheapest edge that crosses from "in the tree" to "not yet in the tree."
- Start with any vertex. Mark it visited.
- Push all its edges into a min-heap.
- Pop the cheapest edge. If the destination is already visited, discard and continue. Otherwise, add the edge and push the new vertex's edges.
- Repeat until all vertices are visited.
import heapq def prim(n, adj): # adj[u] = list of (weight, v) visited = [False] * n heap = [(0, 0)] # (cost, vertex), start at vertex 0 mst_weight = 0 while heap: cost, u = heapq.heappop(heap) if visited[u]: continue visited[u] = True mst_weight += cost for weight, v in adj[u]: if not visited[v]: heapq.heappush(heap, (weight, v)) return mst_weight
This is the lazy variant. Stale entries accumulate in the heap and get silently discarded on pop, like browser tabs you meant to revisit but never will. It needs no decrease-key operation, so Python's heapq works directly. Heap space is O(E). In practice, this is the variant almost everyone implements because it requires no fancy indexed priority queue.
There's a second implementation that changes everything on dense graphs: the O(V²) adjacency matrix variant. Instead of a heap, keep a size-V array tracking the cheapest crossing edge to each unvisited vertex. At each step, scan the whole array to find the minimum. That scan costs O(V), repeated V times: total O(V²). No heap, no sorting, just a flat array.
 Stale (4,B) from step 2 gets discarded when popped in step 4. No cleanup needed.
Stale (4,B) from step 2 gets discarded when popped in step 4. No cleanup needed.
The Complexity Table That Actually Drives the Decision
 On dense graphs, Kruskal's sort step alone costs V² log V. The O(V²) Prim matrix scan wins by a factor of log V.
On dense graphs, Kruskal's sort step alone costs V² log V. The O(V²) Prim matrix scan wins by a factor of log V.
| Graph | E roughly | Kruskal | Prim (heap) | Prim (matrix) |
|---|---|---|---|---|
| Sparse | V | V log V | V log V | V² |
| Moderate | V log V | V log²V | V log²V | V² |
| Dense | V² | V² log V | V² log V | V² |
For dense graphs the O(V²) matrix Prim wins cleanly. Kruskal's sort step alone costs V² log V, worse by a log factor. For sparse graphs both Kruskal and heap-Prim land at O(V log V), and Kruskal is often simpler because it requires no adjacency structure, just an edge list.
When to Use Kruskal vs Prim
Use Kruskal's when:
- The graph is sparse (E much smaller than V²)
- Your input is already an edge list
- The graph may be disconnected. Kruskal naturally produces a spanning forest, one MST per connected component. Prim silently returns an incomplete tree on disconnected input and requires a separate outer loop.
- You want simpler parallel implementation. Edge sorting and union-find are easier to distribute than Prim's sequential vertex expansion.
Use Prim's when:
- The graph is dense (E close to V²), especially with the O(V²) matrix variant
- Your input is an adjacency matrix
- You are on LeetCode 1584 (Min Cost to Connect All Points). That problem gives a complete graph on n points where E = n(n-1)/2. Generating all O(n²) edges just to sort them wastes both time and memory. The O(n²) Prim variant processes each point's nearest unvisited neighbor directly, without materializing every edge.
The disconnected-graph case deserves a flag in interviews. If the graph might not be fully connected, Kruskal works without modification. Detect it afterward by checking whether edges_used == n-1. Prim requires restarting from each unvisited vertex. Easy to forget when no one is watching. Even easier to forget when someone very much is watching you code on a shared screen.
Prim Is Dijkstra with a Different Priority Key
Prim's and Dijkstra's are structurally the same algorithm. Both maintain a min-heap. Both pop the minimum element. Both relax neighboring vertices. The only difference is what they store as the priority.
Dijkstra stores total distance from the source: d[v] = min path cost from start to v. Prim stores only the cheapest direct crossing edge: key[v] = min edge weight connecting v to the current tree. Dijkstra accumulates path cost. Prim resets to the direct edge, ignoring what was paid to reach the other side of the cut.
This means Prim works correctly with negative edge weights, while Dijkstra's algorithm breaks for entirely different reasons when negative weights appear. Prim never accumulates path costs, so a negative edge weight is just a cheaper crossing, not a structural problem.
If you can implement one from memory, you can implement the other by changing one line. The dangerous part is remembering which one you're writing mid-interview.
Same Theorem, Applied in a Different Order
Every edge Kruskal picks is the minimum crossing for the cut between the two components it is about to merge. Every edge Prim picks is the minimum crossing for the cut between the growing tree and everything outside it.
They apply the same cut property in different orders. Kruskal finds global minima first, the lightest edges anywhere in the graph. Prim finds local minima relative to the current frontier. The MSTs they produce may differ when edge weights tie, but the total weight is always the same. Both are optimal.
How the Pattern Shows Up in Interviews
The MST signal is "minimum cost to connect all nodes" with edge weights. Laying cable, building roads, connecting points in a plane. The underlying structure is the same.
The algorithm choice almost always comes down to graph density:
- Explicit sparse edge list (LC 1135, Connecting Cities With Minimum Cost): either works; Kruskal is natural since the input is already a sorted edge list away.
- Complete graph or n points in a plane (LC 1584, Min Cost to Connect All Points): use Prim's O(n²) matrix variant. Generating and sorting all O(n²) edges causes a TLE on large inputs.
k-clustering via MST is a less obvious pattern. Build the MST, then remove the k-1 most expensive edges. The remaining k trees form clusters where the minimum inter-cluster distance is maximized. Kruskal is cleaner here because you can stop early after adding n-k edges, without building the full MST.
For a deeper look at each algorithm individually, the Kruskal's reference walks through the exchange-argument correctness proof and all 14 language implementations, and Prim's reference covers the lazy vs eager heap distinction and the O(E + V log V) Fibonacci heap bound.
The Short Version
- Both algorithms find the MST. Both prove correct via the cut property.
- Kruskal: sort all edges globally, use union-find to skip cycle-creating edges. O(E log E) always.
- Prim: grow a tree locally from a seed vertex via a min-heap or matrix scan. O(E log V) or O(V²).
- Dense graph or adjacency matrix input: use Prim with the O(V²) matrix variant.
- Sparse graph or edge list input: use Kruskal.
- Kruskal handles disconnected graphs for free. Prim needs an outer loop.
- Prim is structurally Dijkstra with a different priority key.
- In interviews, the decision comes down to one question: point cloud or sparse edge list?
Practice explaining this tradeoff out loud, not just writing it down. In a real interview the question often starts as "which algorithm would you use?" and the answer is two sentences about graph density, not a code dump. SpaceComplexity runs voice-based mock interviews that score exactly this kind of tradeoff discussion, which is hard to train on a text-only platform.