Price Alert System Design Interview: The Complete Walkthrough
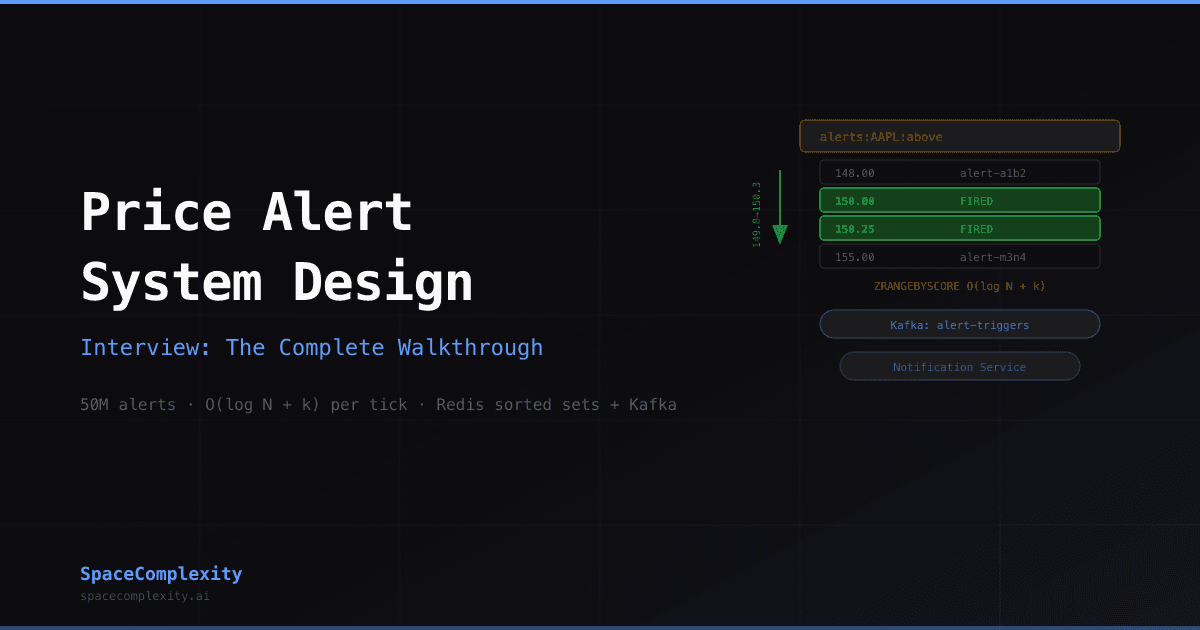
- Redis sorted sets score alerts by target price per asset, cutting evaluation from O(n) per tick to O(log n + k) where k is triggered alerts.
- ZRANGEBYSCORE finds every alert whose threshold falls inside the crossed price range in one call, paying O(log N) when nothing fires.
- A Lua script atomically queries and removes triggered alerts in a single round trip, preventing double-triggers from concurrent evaluator instances.
- Write to PostgreSQL first for durability, then populate Redis sorted sets as the evaluation index; losing a Redis write is recoverable, losing Postgres is not.
- Kafka partitioned by asset_id decouples ingestion from evaluation from notification, and keeps each evaluator instance responsible for a stable subset of assets.
- On restart, backfill Redis from PostgreSQL before accepting price ticks; the evaluator must have full state before the first tick arrives.
- Redis SET NX at the notification layer guarantees at-most-once delivery despite at-least-once Kafka semantics.
The problem sounds trivial. "Notify me when AAPL drops below $150." Every trading app ships this feature. It's the kind of thing a junior dev might knock out in an afternoon with a cron job and a prayer.
Then someone mentions you have 50 million active alerts. And prices tick every 100 milliseconds. And a volatile session can trigger half a million of them in a day. The afternoon project has become your system design interview prompt. Go build it.
The tricky part is not the notification. It is the evaluation. You have 50 million alerts across 10,000 assets and prices updating constantly. Each tick could trigger thousands of alerts simultaneously. The naive answer is a scan. The correct answer is a data structure. Once you see it, the architecture follows.
What to Clarify First (Five Minutes)
Lock down scope before drawing a box. This system has a few forks in the road that change the data model significantly, and interviewers will happily let you build the wrong thing if you don't ask.
Threshold type. Does the alert fire on an absolute price ("below $150") or a percentage move ("down 5%")? Robinhood uses percentages with configurable thresholds. Most stock apps use absolute prices. Absolute is simpler to evaluate. Percentage requires storing the reference price at alert creation. Pick one and state your assumption.
One-shot or recurring. Does the alert fire once and go inactive? Or does it re-arm and fire every time the price crosses the threshold? One-shot is the standard default. It prevents an alert from texting you 80 times while a stock bounces around your threshold at 9:31am.
Delivery channels. Push notification, email, or SMS? Assume push as the primary channel, email as fallback.
Assets covered. Stocks, crypto, or both? Crypto trades 24/7. Stocks trade 6.5 hours a day on weekdays. This affects your ingestion pipeline. Assume both for this walkthrough.
Latency requirement. "As fast as possible" is not a requirement. Commit to 30 seconds as the SLA and design everything around it. A 30-second notification still feels instant to a human waiting to buy a dip.
Scale Envelope
Before architecture, do the math.
- 10 million users, average five alerts each: 50 million active alerts
- 10,000 tradeable assets (stocks plus major crypto)
- Top 100 liquid assets: price updates every 100ms during market hours (10 per second per asset)
- Remaining 9,900 assets: one update every 1 to 60 seconds
- Alert triggers on a volatile day: roughly 500K per day, about 6 per second at peak
At 50 million alerts spread across 10,000 assets, the average is 5,000 alerts per asset. That per-asset density is exactly what makes the data structure choice matter.
High-Level Architecture
Five boxes. Draw them, then spend the next 30 minutes justifying the connections.

Five services. One rule: Kafka between every stage so nothing blocks anything else.
The Alert Management Service handles user-facing CRUD. The Price Ingestion Service polls or subscribes to market data APIs. The Alert Evaluation Engine is where the real work happens. It consumes price ticks and decides which alerts just crossed their threshold. The Notification Service is downstream, handling delivery and deduplication.
The key insight you want to state explicitly: partitioning Kafka by asset_id means each evaluator instance owns a stable slice of assets. No cross-instance coordination. No shared mutable state. Each consumer just works its partition and minds its own business.
Data Model
Two stores for the alert lifecycle: PostgreSQL for durability, Redis for fast evaluation.

Write PostgreSQL first (durability), then add to Redis (speed). If Redis dies, rebuild from Postgres on restart.
PostgreSQL: alerts table
CREATE TABLE alerts ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), user_id UUID NOT NULL, asset_id VARCHAR(16) NOT NULL, -- e.g. "AAPL", "BTC-USD" direction VARCHAR(8) NOT NULL, -- "above" or "below" target_price DECIMAL(18, 6) NOT NULL, status VARCHAR(16) NOT NULL DEFAULT 'active', -- active | triggered | deleted created_at TIMESTAMPTZ NOT NULL DEFAULT now(), triggered_at TIMESTAMPTZ ); CREATE INDEX idx_alerts_asset_status ON alerts (asset_id, status); CREATE INDEX idx_alerts_user ON alerts (user_id);
Redis: sorted sets per asset per direction
For each asset, maintain two sorted sets:
alerts:{asset_id}:above-- alerts that fire when price rises above thresholdalerts:{asset_id}:below-- alerts that fire when price falls below threshold
The score is the target_price. The member is the alert_id.
When a user creates an alert, write to PostgreSQL first (for durability), then add to the appropriate Redis sorted set with ZADD. The two writes are not atomic at the application layer, but losing a Redis write is recoverable on restart. Losing the PostgreSQL write is not.
The Alert Evaluation Engine (the Core Problem)
Here is the interview inflection point. This is where you either win or spend the remaining 20 minutes apologizing for your O(N) loop.
The naive approach: when a price update arrives, iterate through all alerts for that asset and check each one. At 5,000 alerts per asset and 10 updates per second for a liquid stock, that is 50,000 comparisons per second per asset. Multiply by 100 liquid assets: 5 million comparisons per second. Manageable today, but you are paying O(N) on every single tick, including the 99.9% of ticks where nothing fired. The system does a lot of work to conclude "nope."
The right approach cuts evaluation to O(log N + k) per update, where k is the number of triggered alerts. That number is usually zero.
Here is how the sorted set makes it work.
When price moves from P_old to P_new:
# Price rose: find all "above" alerts with threshold in [P_old, P_new] if P_new > P_old: triggered = redis.zrangebyscore( f"alerts:{asset_id}:above", P_old, # min P_new # max ) # Price fell: find all "below" alerts with threshold in [P_new, P_old] if P_new < P_old: triggered = redis.zrangebyscore( f"alerts:{asset_id}:below", P_new, # min P_old # max )

ZRANGEBYSCORE descends the skip list in O(log N) to find the range boundary, then reads the k matching members linearly. If nothing fired, you paid about 12 operations for 5,000 alerts.
ZRANGEBYSCORE on a Redis sorted set is O(log N + M), where N is the number of alerts for the asset and M is the number of results returned. The sorted set is backed by a skip list internally, so the range lookup is a logarithmic descent to the matching boundary and then a linear scan through the hits. If nothing triggered, you pay O(log N). If ten alerts triggered, you pay O(log N + 10). For the non-triggering case (most ticks), the cost is about log(5000) = 12 operations instead of 5,000.
That is the core of the system. Everything else is plumbing.
Once you have the triggered alert IDs:
- Remove them from the Redis sorted set (
ZREM) so they do not trigger again (one-shot behavior). - Publish the alert IDs to a Kafka topic
alert-triggers. - A background job asynchronously marks the alerts as
triggeredin PostgreSQL.
The atomicity concern: a Redis Lua script handles the lookup and removal in one round trip so two evaluator instances cannot double-trigger the same alert.
-- Atomic range query + removal in one round trip local triggered = redis.call('ZRANGEBYSCORE', KEYS[1], ARGV[1], ARGV[2]) if #triggered > 0 then redis.call('ZREM', KEYS[1], unpack(triggered)) end return triggered
Notification Pipeline
The notification side is a consumer reading from alert-triggers. For each alert ID, it looks up the user's contact details and delivery preferences, then fans out to push, email, or SMS.
Deduplication. Kafka gives at-least-once delivery, so the Notification Service might process the same alert ID twice. Guard against double-notification with a Redis key:
SET notified:{alert_id} 1 NX EX 86400
Only the first consumer to win that SET NX call sends the notification. The 24-hour TTL handles cleanup. The NX flag makes the check atomic. Your user gets one push notification, not three.
For a deeper look at the notification delivery layer, including fallback channels and retry logic, see the Notification System Design walkthrough.
Scaling Bottlenecks
This is where interviewers separate candidates who memorized an architecture from candidates who actually thought through the failure modes.
Hot assets. AAPL and BTC might have millions of alerts, not thousands. A single Redis sorted set with one million members is fine for Redis (it handles hundreds of millions of keys in memory), but if you shard the evaluator by asset, one instance will run hotter than the others. Fix: consistent hashing across evaluator instances with virtual nodes, so load distributes naturally.
Mass trigger events. A market crash fires millions of alerts at once. Your Kafka alert-triggers topic will back up. The Notification Service needs surge handling: batch notifications where possible (one digest instead of 20 separate alerts for the same user), and use exponential backoff when downstream providers rate-limit you. Push providers will rate-limit you. They always do.
Alert creation surge. When a hot IPO lands, every user sets an alert on the new ticker simultaneously. PostgreSQL writes are synchronous (you need durability). Redis writes can be async via Kafka: the alert is immediately active in the DB, and a consumer populates the sorted set within seconds. During that window, a price tick could slip through. For most products, this is an acceptable tradeoff. If it is not, write to Redis synchronously before returning to the user.
Market open. Stock markets open at 9:30am ET and prices move fast immediately. Pre-warm ingestion connections before market open. The evaluator must have the full Redis state loaded before the first tick arrives, not after. A cold evaluator at 9:30:01am is a bad day.
Key Tradeoffs
In-memory vs. persistent for the sorted sets. Redis is in-memory and fast, but a restart loses the sorted sets unless you use RDB snapshots or AOF persistence. The recovery path: on evaluator startup, backfill Redis sorted sets by querying PostgreSQL for all active alerts. At 50 million alerts, this takes time. Design the startup sequence so the evaluator rejects price ticks until the backfill is complete. Alternatively, keep Redis persistent with appendonly yes and accept the write overhead. Both are defensible. Pick one and explain why.
Percentage vs. absolute thresholds. Absolute thresholds fit directly into sorted set scores. Percentage thresholds require storing the reference price at alert creation and computing the trigger price at evaluation time. You can convert a percentage alert to an absolute trigger price at creation and store that, keeping the evaluation engine identical. The downside: if the reference price was captured at an unexpected moment, the user gets a confusing notification.
One-shot vs. recurring. Recurring alerts sound appealing but create product problems. If a stock bounces around your threshold, a recurring alert fires dozens of times an hour. One-shot forces deliberate re-arming. Most trading apps default to one-shot, and most users are grateful for it around hour three of a volatile session.
Push vs. pull for price data. Market data providers offer WebSocket feeds (push) and REST APIs (pull). Push is lower latency and lower bandwidth. Pull is simpler and easier to rate-limit. Use WebSocket where available. For a broader discussion of this tradeoff, see The Trade-off Maze.
The 45-Minute Clock
- 0 to 5: clarify threshold type, one-shot vs. recurring, delivery channels, asset scope, latency SLA
- 5 to 15: high-level five-box architecture, Kafka partitioned by asset_id
- 15 to 25: data model (PostgreSQL + Redis sorted sets), alert creation flow
- 25 to 35: evaluation engine deep dive (sorted set range query, Lua atomicity, removal after trigger)
- 35 to 42: bottlenecks (hot assets, mass trigger, creation surge, market open), scaling strategies
- 42 to 45: tradeoffs summary, which decision you would change given different constraints
Price Alert System Design Interview: Recap
- Two stores: PostgreSQL for durability, Redis sorted sets for O(log N + k) threshold evaluation.
- Two sorted sets per asset: one for "above" alerts, one for "below" alerts, scored by target price.
- On each price tick: one ZRANGEBYSCORE call finds all triggered alerts in the crossed range.
- Atomic Lua script removes triggered alerts from Redis and returns them in one round trip.
- Kafka between every stage decouples ingestion from evaluation from notification.
- Deduplication at the notification layer with Redis SET NX prevents double-sends.
- Partition by asset_id everywhere so each evaluator instance owns a stable subset of assets.
- Recovery on restart: backfill Redis from PostgreSQL before accepting price ticks.
If you want to drill this kind of problem under actual interview pressure, SpaceComplexity runs voice-based system design mock interviews with rubric-based feedback, so you can practice the 45-minute clock until the structure becomes automatic.
For related reading: Distributed Cache System Design covers Redis architecture in depth, and the Skip List Data Structure article explains exactly why ZRANGEBYSCORE is O(log N + M).
Further Reading
- Redis Sorted Sets Documentation -- official reference for ZADD, ZRANGEBYSCORE, ZREM
- ZRANGEBYSCORE Command Reference -- exact complexity guarantees and LIMIT behavior
- Apache Kafka Design Overview -- partitioning, consumer groups, delivery semantics
- Building a Notification Platform at Coinbase -- real production notes on event-driven notification architecture
- Wikipedia: Publish-Subscribe Pattern -- the architectural pattern underlying the evaluation-to-notification handoff