Quicksort vs Heapsort: Same O(n log n), One Wins Every Time
- Heapsort guarantees Θ(n log n) in every case; quicksort averages O(n log n) but hits O(n²) on adversarial input
- Cache locality explains the 5-8x speed gap: quicksort scans sequentially, heapsort jumps between distant memory addresses on every sift-down
- An L3 cache miss costs 40-50x more than an L1 hit; heapsort generates roughly n log n such misses once the array exceeds L3 cache
- Introsort (Musser 1997) solves both: quicksort until recursion depth hits 2·log₂(n), then heapsort — GCC, Clang, and MSVC all ship it
- Heapsort wins when input could be adversarial, auxiliary space must be zero, or you are draining an existing heap
- The standard library already made this decision for you — trust it unless you have a specific reason not to
Both sort an array in-place. Both run in O(n log n). On paper the quicksort vs heapsort debate looks like a tie. Benchmark them sorting 100 million integers and quicksort finishes in two seconds while heapsort takes twelve.
That is not a rounding error. It comes from one root cause: heapsort touches memory in a pattern that makes CPUs miserable.
Two Algorithms, One Shared Complexity
Quicksort (Hoare, 1959, published 1962) picks a pivot element, partitions the array so everything smaller sits to its left and everything larger to its right, then recurses on both halves. The pivot lands in its final sorted position after each partition. If splits are roughly balanced, the recurrence T(n) = 2T(n/2) + O(n) gives O(n log n). Hoare's analysis showed the average cost is about 1.39n log₂n comparisons with random pivot selection, around 39% more than merge sort's theoretical minimum, but still very fast in practice.
The catch is real: always pick the smallest element as pivot on a sorted array and you get T(n) = T(n-1) + O(n), which solves to O(n²). Any deterministic pivot rule can be exploited by crafted input.
Heapsort (J.W.J. Williams, 1964) runs in two phases. Phase one builds a max-heap from the unsorted array using Floyd's bottom-up method. That costs O(n), not O(n log n), because most nodes are near the leaves and barely sift at all. Phase two repeatedly swaps the max (the root) to the back of the live array and sifts down the boundary, n-1 times at O(log n) each. Total: Θ(n log n) in every single case. Best, average, worst. No pathological input makes it slower.
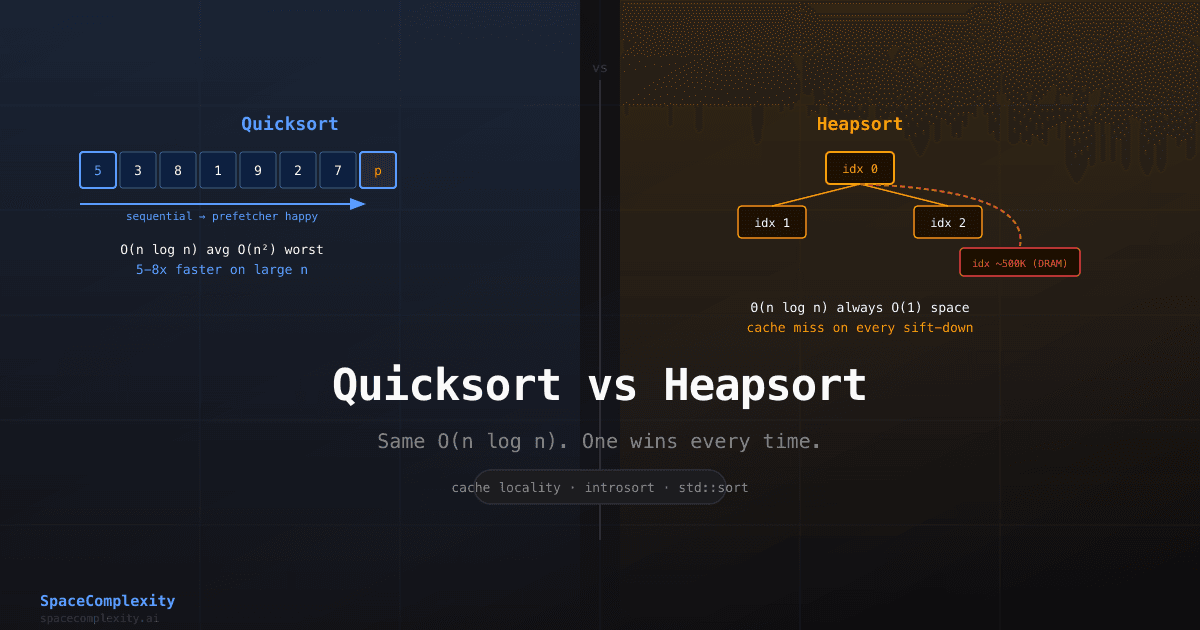
 Left: quicksort scans sequentially, giving the prefetcher an easy job. Right: heapsort jumps between index 0 and index ~500K on every sift-down step.
Left: quicksort scans sequentially, giving the prefetcher an easy job. Right: heapsort jumps between index 0 and index ~500K on every sift-down step.
O(n log n) Doesn't Tell the Whole Story
| Quicksort | Heapsort | |
|---|---|---|
| Best case | O(n log n) | Θ(n log n) |
| Average case | O(n log n) | Θ(n log n) |
| Worst case | O(n²) | Θ(n log n) |
| Extra space | O(log n) stack | O(1) |
| Stable? | No | No |
| Adaptive? | Yes | No |
Quicksort's worst case is genuinely O(n²), not a textbook footnote. And heapsort uses truly O(1) extra space, no recursion stack at all, which matters more than it sounds.
How Quicksort Moves Through Memory
The partition step scans two pointers across a subarray:
def _partition(arr, lo, hi): pivot = arr[hi] i = lo - 1 for j in range(lo, hi): if arr[j] <= pivot: i += 1 arr[i], arr[j] = arr[j], arr[i] arr[i + 1], arr[hi] = arr[hi], arr[i + 1] return i + 1 def quicksort(arr, lo=0, hi=None): if hi is None: hi = len(arr) - 1 if lo < hi: p = _partition(arr, lo, hi) quicksort(arr, lo, p - 1) quicksort(arr, p + 1, hi)
The inner loop visits index lo, lo+1, lo+2, and so on. Sequential. Your CPU's hardware prefetcher detects the stride immediately and pre-loads the next cache line before you even ask for it. A cache line is 64 bytes, which holds 16 int32 values. You pay one cache miss, then get 15 comparisons for free. When a partition recurses, the subarray shrinks by half. After about 20 levels of recursion the active subarray fits entirely in L1 cache and the rest of the work is basically free.
Why Heapsort Has a Memory Problem
The sift-down step looks innocent:
def _sift_down(arr, i, n): while True: largest, left, right = i, 2 * i + 1, 2 * i + 2 if left < n and arr[left] > arr[largest]: largest = left if right < n and arr[right] > arr[largest]: largest = right if largest == i: break arr[i], arr[largest] = arr[largest], arr[i] i = largest def heapsort(arr): n = len(arr) for i in range(n // 2 - 1, -1, -1): _sift_down(arr, i, n) for i in range(n - 1, 0, -1): arr[0], arr[i] = arr[i], arr[0] _sift_down(arr, 0, i)
Now trace what happens at the start of the extraction phase. The root is at index 0. Its children are at 1 and 2. After one swap, the new root's children are at 3 and 4. Two levels down: 7 through 10. Three levels down: 15 through 22. For an array of one million elements, the deepest comparisons in a sift-down jump between index 0 and indices around 500,000. Those elements live in completely different cache lines, different L2 lines, different L3 lines. Frequently they are not in cache at all.
 One cache miss buys quicksort 15 sequential comparisons. Heapsort earns one comparison per 100ns DRAM round-trip.
One cache miss buys quicksort 15 sequential comparisons. Heapsort earns one comparison per 100ns DRAM round-trip.
This is not a small constant-factor cost. An L1 cache hit costs about 2 nanoseconds. A miss that falls all the way to DRAM costs 80 to 100 nanoseconds, a 40 to 50x difference per access. Heapsort generates roughly n log n such misses once the array exceeds your L3 cache (typically 8 to 32 MB). Quicksort's partitions quickly shrink the active subarray into something warm. The result on large inputs: heapsort runs 8x slower despite executing only about 4x more instructions. The extra slowdown is pure DRAM latency, and it compounds as n grows.
When Heapsort Is the Right Call
 Heapsort wins in exactly three situations. Outside these, quicksort or introsort is almost always the better call.
Heapsort wins in exactly three situations. Outside these, quicksort or introsort is almost always the better call.
The cache penalty is worth paying in three situations.
Guaranteed worst case. If your input can be adversarially crafted, any deterministic quicksort pivot strategy can be exploited. Randomized pivot selection makes this astronomically unlikely but not impossible. Heapsort has no pivot. No adversary can push it past Θ(n log n).
Strict O(1) auxiliary space. Quicksort's O(log n) stack depth sounds trivial, but it requires a live call stack that grows proportionally with recursion depth. In embedded systems, kernel space, or any environment with a hard memory ceiling, heapsort sorts in-place with zero bookkeeping overhead. Quicksort's O(log n) is small but not zero.
You already have a heap. If your data structure is already a max-heap and you want a sorted array, the extraction phase of heapsort is just running the heap's standard delete-max repeatedly. No rebuild needed. The sort comes out of the structure for free.
This Was Solved in 1997 and Nobody Told You
In 1997, David Musser published "Introspective Sorting and Selection Algorithms" (Software: Practice and Experience, Vol. 27, Issue 8, pp. 983-993) and proposed a hybrid called introsort. Start with quicksort. Track the recursion depth. Switch to heapsort if depth ever exceeds 2*floor(log₂(n)).
 Three algorithms, one sort. Quicksort handles typical inputs fast, heapsort handles the bad partitioning case, and insertion sort mops up tiny subarrays.
Three algorithms, one sort. Quicksort handles typical inputs fast, heapsort handles the bad partitioning case, and insertion sort mops up tiny subarrays.
This gives you quicksort's practical speed on nearly all real inputs, with heapsort's O(n log n) worst-case guarantee. The depth threshold fires rarely on random or typical data. When it does fire, you are already on a bad partitioning path and the heapsort fallback is cheaper than letting the O(n²) scenario run.
GCC's std::sort, Clang's libc++, and Microsoft's STL all ship introsort with this same threshold. Small subarrays (typically under 16 elements) get insertion sort instead, because insertion sort has near-zero overhead for tiny n and fits entirely in registers.
So the practical answer to "which algorithm should I use" is: use your language's standard sort. It already solved this problem in 1997. You have better things to worry about.
Quicksort vs Heapsort: Picking One When You Have To
If you are implementing from scratch, the decision tree is short.
Use randomized quicksort when you want the fastest practical sort, O(n²) worst case is tolerable or you trust your randomization, and your input is large enough that cache behavior dominates. Expect 5 to 8x better cache performance than heapsort on arrays that exceed L3 cache.
Use heapsort when you need a hard worst-case guarantee, you cannot afford any extra stack space, or you are draining a priority queue. Accept the cache penalty knowing you have eliminated the adversarial scenario.
Implement introsort if both constraints apply. It is thirty extra lines and it is what every major runtime ships.
The Short Answer
- Quicksort: O(n log n) average, O(n²) worst, O(log n) stack, sequential cache access, 5 to 8x faster in practice on large arrays.
- Heapsort: Θ(n log n) always, O(1) space, every sift-down jumps to distant memory, performance degrades sharply once the array exceeds L3 cache.
- Both are in-place. Neither is stable.
- The performance gap between them grows as the array grows, because cache misses dominate DRAM latency, not instruction count.
- Introsort (Musser 1997) is the practical answer: quicksort until recursion depth hits 2*log₂(n), then heapsort. GCC and Clang both ship it.
- Your standard library already made this decision. Trust it unless you have a specific reason not to.
For the full O(n) build-heap derivation and the geometric series proof, see the heap sort time complexity breakdown. The merge sort vs quicksort comparison covers the average-case analysis and the 1.39n log n constant in more detail. The same cache locality story from a different angle is in array vs linked list performance.
Sorting algorithms come up in technical interviews not just as problems but as complexity reasoning tests. The expected follow-up is "why is std::sort faster than heapsort if they're both O(n log n)?", and the interviewer is looking for you to reach cache locality, not just a table you memorized. SpaceComplexity runs voice-based DSA mock interviews with rubric-based feedback, so you can practice explaining this kind of reasoning out loud under pressure rather than just reading about it.